Renderización de vista virtual sensible a texto.
Método de renderización de vista virtual, en el que un vídeo de entrada (101),
con al menos un texto, es renderizado de acuerdo a los datos de profundidad (106) para representar una vista virtual, caracterizado porque dicho método comprende las etapas de;
- determinación de un formato del vídeo de entrada (101) en términos de número de vistas (102);
- detección de, al menos, un texto en dicho vídeo de entrada (101) (103) mediante la ejecución de un algoritmo de detección de texto, de acuerdo con un determinado formato de video de entrada (101); en el que
i. si el formato de vídeo detectado del mencionado vídeo de entrada (101) es de una vista única, la etapa de detección de texto (103) comprende ejecutar un algoritmo de detección para determinar las posiciones de regiones de texto posibles,
ii. si el formato de vídeo detectado del mencionado vídeo de entrada (101) es de una vista en estéreo o de vista múltiple, antes de la etapa de detección de texto se lleva a cabo una etapa de análisis de error de renderizado (104) para detectar posibles regiones de texto (103) y la etapa de análisis de error de renderizado comprende comparar dos imágenes procedentes de diferentes vistas de videos estéreo o de vistas múltiples para detectar texto y comprendiendo la etapa de detección de texto (103) ejecutar un algoritmo de detección para detectar el texto de un vista estéreo o múltiple,
- generación de una vista renderizada (107) mediante la realización de post-procesamiento de datos de profundidad (105) en el que para cada región de texto, todos los caracteres de texto detectado son deformados con misma distribución de profundidad de acuerdo con dichos datos de profundidad (106).
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E12165350.
Solicitante: VESTEL ELEKTRONIK SANAYI VE TICARET A.S.
Nacionalidad solicitante: Turquía.
Dirección: ORGANIZE SANAYI BÖLGESI 45030 MANISA TURQUIA.
Inventor/es: CIGLA,CEVAHIR.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06T11/60 FISICA. › G06 CALCULO; CONTEO. › G06T TRATAMIENTO O GENERACIÓN DE DATOS DE IMAGEN, EN GENERAL. › G06T 11/00 Generación de imagen 2D (Bidimiensional). › Edición de figuras y de texto; Combinación de figuras o de texto.
- H04N13/00 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04N TRANSMISION DE IMAGENES, p. ej. TELEVISION. › Sistemas de video estereoscópico; Sistemas de video multivista; Sus detalles.
PDF original: ES-2545513_T3.pdf
Fragmento de la descripción:
Renderización de vista virtual sensible a texto
Campo técnico
La presente invención se refiere a un dispositivo y un método para renderización de vista virtual sensible a texto en video estéreo o de vistas múltiples.
Técnica anterior [0002] En las pantallas de presentación estereoscópicas o pantallas de presentación de vistas múltiples, la síntesis de vista virtual es un método utilizado comúnmente para mejorar las capacidades 3D, tales como ajuste de profundidad, cambio del ángulo de visualización para vista libre o extensión de videos mono/estéreo a vistas múltiples, de las pantallas de visualización. En general, con el fin de generar dicha vista virtual, se utiliza la renderización de base de profundidad. En la renderización de base de profundidad, preferentemente se genera por escena un mapa de profundidad, utilizando imágenes reales adquiridas desde diferentes puntos de vista y mediante la utilización del mencionado mapa de profundidad y textura de una escena original (referencia) , se genera una vista virtual desde un punto de vista arbitrario (renderizado) . Durante este proceso, la textura de dicha escena se ha deformado de acuerdo con la información del mapa de profundidad (por ejemplo los píxeles (o los voxels) más cercanos a la posición del punto de vista de la vista virtual se tienen en cuenta para visualizarse) . Cuando toda la textura de la vista de referencia es deformada; se producen algunas posiciones perdidas (huecos) debido a regiones ocluidas. Estas posiciones son rellenadas por diversos métodos, tales como pintura (interpolación de imagen) , copiado de fondo o promediado de pixeles vecinos (voxels) . Para el caso estéreo, las texturas de las vistas izquierda y derecha también podrían mezclarse para obtener la textura de la vista arbitraria. [0003] Durante la síntesis de la vista virtual, la información de mapa de profundidad no podrá generarse perfectamente. En otras palabras, dicha información puede incluir errores. Debido a dichos errores la vista virtual generada puede contener objetos con una profundidad inadecuada. Aunque la mayoría de los usuarios no se dan cuenta de este error de profundidad de los objetos de fondo, dichos errores en los textos (tales como subtítulos) a la vista de usuarios degradan su confort ya que los textos son considerados los objetos más sobresalientes en una pantalla. Así, durante la renderización de la vista virtual, los textos deberían ser renderizados con mínimo error. [0004] El documento de patente WO2008115222A1 describe un sistema y un método para combinar texto con contenido 3D. En este documento, un texto se inserta en el contenido 3D como el valor de profundidad más alto. Aunque en este documento son insertados subtítulos con alta visibilidad en la vista 3D, la imagen de fondo y parte de texto de la imagen se pueden mezclar entre sí porque regiones de texto se detectan poniendo cajas alrededor del texto y procesándose dicha caja como un todo. De la misma manera, la detección de profundidad se proporciona para la imagen original sin subtítulos lo cual es tarea fácil en comparación con las imágenes con texto incorporado. [0005] Otro documento de patente WO2010151555A1, describe un método para incrustar subtítulos y/o superponer gráficos en un video 3D o de vistas múltiples. Sin embargo, este documento no resuelve el problema de los caracteres erróneamente posicionados en la imagen renderizada, lo cual se produce debido a mapa de profundidad erróneo. [0006] El documento de patente EP2403254A1 describe un aparato, programa y método para el procesamiento de imagen. De acuerdo con este documento, se reciben dos imágenes por un receptor. Utilizando un módulo de detección de subtítulos se determinan los textos de las imágenes recibidas. En este documento, la misma información de paralaje se utiliza para los subtítulos.
Breve descripción de la invención [0007] La presente invención describe un método y sistema para la renderización de vista virtual, en el cual un vídeo de entrada con un texto se renderiza de acuerdo con los datos de profundidad. Dicho método incluye las etapas de; determinación del formato de vídeo en términos de número de vistas; detección de dicho texto en el mencionado vídeo de entrada, mediante la ejecución de un algoritmo de detección de texto de acuerdo con un determinado formato del vídeo de entrada; generación de una vista renderizada, llevando a cabo el postprocesamiento de datos de profundidad en el cual el texto detectado es deformado con distribución de profundidad constante de acuerdo con dichos datos de profundidad. [0008] Además, dicho sistema comprende al menos unos medios para determinar el formato de un vídeo de entrada, en términos de número de vistas; al menos unos medios para la detección de, al menos, un texto del mencionado video de acuerdo con determinado formato; al menos unos medios de post-procesamiento de datos de profundidad, los cuales deforman el texto detectado con un valor de profundidad constante. [0009] Con el método de renderización de vista virtual y el sistema de la presente invención, a partir del video se extrae un texto de un vídeo. Entonces, dicho texto y la vista de fondo del video son deformados Independientemente de acuerdo con los datos de profundidad del video. Así, de acuerdo a la presente invención, se previenen caracteres desplazados debido a información de profundidad errónea y el fondo del video es deformado sin mezclar el texto.
Objeto de la Invención 2
El objeto de la invención es proporcionar un método y un sistema para la renderización de vistas virtuales que comprenden textos. [0011] Otro objeto de la presente invención es proporcionar un método y un sistema para la renderización de textos en una vista virtual con el mínimo error. [0012] Otro objeto de la presente invención es proporcionar un método y un sistema para la renderización de vistas virtuales con alta fiabilidad.
Descripción de las figuras [0013]
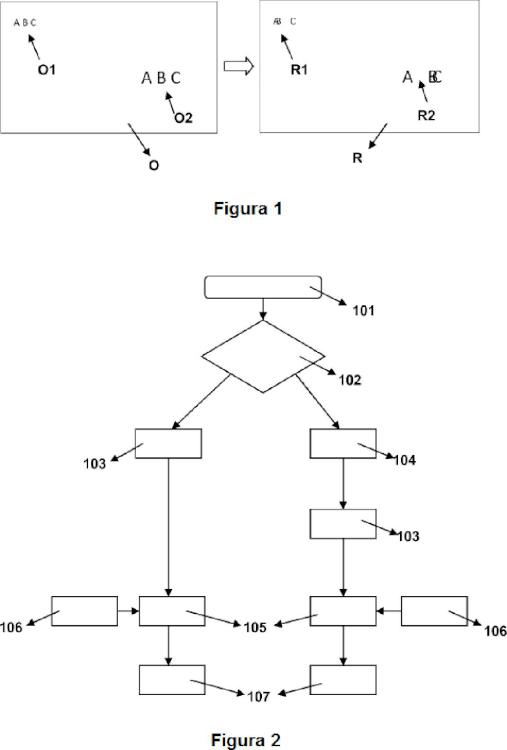
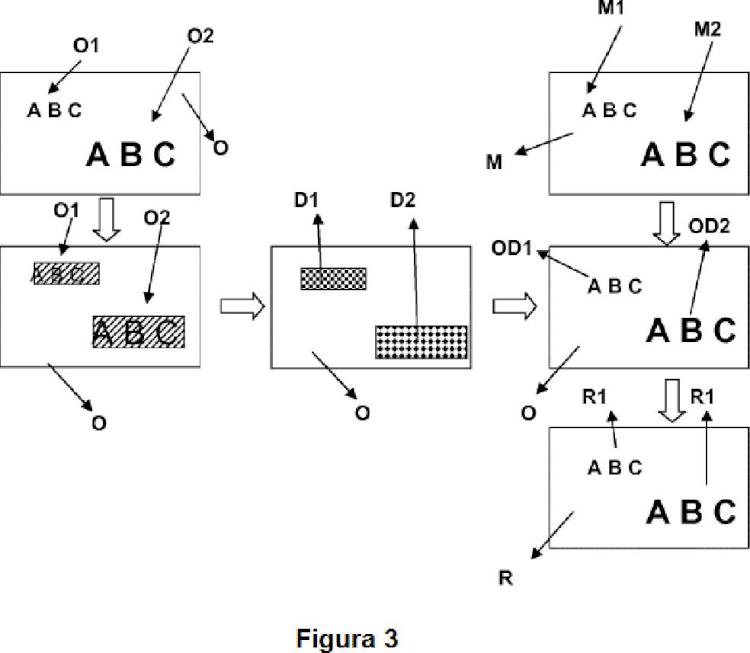
La figura 1 muestra una renderización de vista virtual errónea de la técnica anterior. La figura 2 muestra un diagrama de flujo del método de renderización de vista virtual de la presente invención. La figura 3 muestra un ejemplo de renderización de vista virtual de la presente invención. [0014] Los números de referencia que se utilizan en las figuras pueden poseer los siguientes significados. Vista original (O) Caracteres de texto originales (O1, O2) Vista renderizada (R) Caracteres de texto renderizados (R1, R2) Datos de mapa de profundidad (M) Información de profundidad de los caracteres (M1, M2) Profundidad de los caracteres (D1, D2) Caracteres con información de profundidad (OD1, OD2) Vídeo de entrada (101) Detector tipo de vídeo (102) Detección de texto (103) Análisis de error de renderizado (104) Post-procesamiento de datos de profundidad (105) Datos de profundidad (106) Vista renderizada (107)
Descripción detallada de la invención [0015] En pantallas de visualización estereoscópica o pantallas de visualización de vistas múltiples, la síntesis de vista virtual es un método comúnmente utilizado para la mejora de las capacidades 3D de dichas pantallas de visualización. En la síntesis de vista virtual, por lo general, se generan unos datos de textura y una información de mapa de profundidad para una pantalla de visualización y dicha información se utiliza para generar (renderizar) una vista virtual desde una ubicación arbitraria. Durante la generación de dicha vista virtual, dicha textura es deformada de acuerdo con la información del mapa de profundidad. Si dicha información de mapa de profundidad comprende valores erróneos, la imagen generada (renderizada) también comprende partes erróneas, que también son llamadas artefactos. Normalmente, estos artefactos no son percibidos por los usuarios. Sin embargo, si un mapa de profundidad de un texto comprende errores, la posición de los caracteres de dicho texto puede desplazarse erróneamente. Un ejemplo de imagen renderizada erróneamente se muestra en la figura 1. En este ejemplo, la vista original (O) implica porciones de texto con caracteres de texto original (01, 02) . Cuando la textura de vista original
(O) es deformada con un mapa de profundidad erróneo, la imagen renderizada (R) comprende caracteres de texto renderizados (R1, R2) , cuyas posiciones están desplazadas. Por lo tanto, con el fin de evitar este tipo de caracteres posicionados erróneamente en la imagen renderizada (R) , la presente invención proporciona un método y un sistema para renderización sin error de textos en una vista virtual. [0016] En el método de renderización de vista virtual de la presente invención, cuyo diagrama de flujo se da en la figura 2, en primer lugar, el formato de vídeo de entrada (101) se determina (102) en función... [Seguir leyendo]
Reivindicaciones:
1. Método de renderización de vista virtual, en el que un vídeo de entrada (101) , con al menos un texto, es renderizado de acuerdo a los datos de profundidad (106) para representar una vista virtual, caracterizado porque dicho método comprende las etapas de; -determinación de un formato del vídeo de entrada (101) en términos de número de vistas (102) ; -detección de, al menos, un texto en dicho vídeo de entrada (101) (103) mediante la ejecución de un algoritmo de detección de texto, de acuerdo con un determinado formato de video de entrada (101) ; en el que i. si el formato de vídeo detectado del mencionado vídeo de entrada (101) es de una vista única, la etapa de detección de texto (103) comprende ejecutar un algoritmo de detección para determinar las posiciones de regiones de texto posibles, ii. si el formato de vídeo detectado del mencionado vídeo de entrada (101) es de una vista en estéreo o de vista múltiple, antes de la etapa de detección de texto se lleva a cabo una etapa de análisis de error de renderizado (104) para detectar posibles regiones de texto (103) y la etapa de análisis de error de renderizado comprende comparar dos imágenes procedentes de diferentes vistas de videos estéreo o de vistas múltiples para detectar texto y comprendiendo la etapa de detección de texto (103) ejecutar un algoritmo de detección para detectar el texto de un vista estéreo o múltiple, -generación de una vista renderizada (107) mediante la realización de post-procesamiento de datos de profundidad (105) en el que para cada región de texto, todos los caracteres de texto detectado son deformados con misma distribución de profundidad de acuerdo con dichos datos de profundidad (106) .
2. Método de acuerdo con la reivindicación 1 caracterizado porque; la etapa de detección de texto (103) comprende adicionalmente la extracción de información de texto de dichas regiones mediante utilización de un algoritmo de reconocimiento de texto.
3. Método de acuerdo con la reivindicación 1 caracterizado porque la etapa de análisis de error de renderizado (104) comprende las etapas de; -deformación de una primera trama de dicho vídeo en estéreo o de vistas múltiples en una trama pareja a través de los datos de profundidad (106) de dicho vídeo de entrada (101) ; -comparación de una imagen deformada con dicha trama pareja, tomando la diferencia de trama absoluta de la vista sintetizada y dicha trama pareja; -comparación de la diferencia de trama absoluta con un valor umbral; -si para un píxel la diferencia de trama absoluta de la trama deformada y dicha trama pareja es mayor que dicho valor umbral, se asigna dicho píxel como una posible región de texto; -llevar a cabo la etapa de detección de texto (103) para dicha región de texto posible.
4. Método de acuerdo con la reivindicación 1 caracterizado porque la etapa de post procesamiento de datos de profundidad (105) , comprende la deformación del mencionado texto detectado con un valor de datos de profundidad del carácter de texto, que está más próximo a un punto de vista.
5. Sistema de renderización de vista virtual, en el que un vídeo de entrada (101) , con al menos un texto, es renderizado de acuerdo con unos datos de profundidad (106) para representar una vista virtual caracterizado porque comprende; -al menos unos medios para determinar el formato de un vídeo de entrada (101) en términos de número de vistas; -al menos unos medios para la detección de, al menos, un texto en dicho vídeo mediante la ejecución de un algoritmo de detección de texto de acuerdo con determinado formato de vídeo de entrada; en el que
i. si el formato de vídeo detectado de dicho vídeo de entrada es una vista única, la etapa de detección de texto comprende la ejecución de un algoritmo de detección para determinar las posiciones de regiones de texto posibles, ii. si el formato de vídeo detectado de dicho vídeo de entrada es una vista estéreo o una vista múltiple antes de la etapa de detección de texto se lleva a cabo una etapa de análisis de error de renderizado para detectar posibles regiones de texto y comprendiendo la etapa de análisis de error de renderizado comparar dos imágenes procedentes de diferentes vistas de video estéreo o de vistas múltiples para la detección de texto y comprendiendo la etapa de detección de texto ejecutar un algoritmo de detección para detectar el texto de un vista estéreo o múltiple, -al menos unos medios para generar una vista renderizada, llevando a cabo un post procesamiento de los datos de profundidad en el que para cada región de texto, todos los caracteres de texto detectado son deformados con misma distribución de profundidad de acuerdo con dichos datos de profundidad.
Patentes similares o relacionadas:
SISTEMA PARA ACOPLAR UN DISPOSITIVO DE DIGITALIZACIÓN DE IMÁGENES A UN INSTRUMENTO ÓPTICO, del 21 de Noviembre de 2019, de Spotlab, S.L: 1. Sistema para acoplar un dispositivo de digitalización de imágenes, que comprende al menos una lente, a un instrumento óptico que comprende […]
Seguimiento tridimensional de un dispositivo de control del usuario en un volumen, del 30 de Octubre de 2019, de zSpace, Inc: Un método que comprende: recibir múltiples imágenes capturadas de al menos un punto visualmente indicado de un dispositivo de control del usuario […]
 Procedimiento de compresión de información de vídeo, del 30 de Octubre de 2019, de Broadmedia GC Corporation: Un procedimiento de compresión de información de vídeo, que comprende las etapas de:
- proyectar puntos de una imagen siguiente en puntos proyectados […]
Procedimiento de compresión de información de vídeo, del 30 de Octubre de 2019, de Broadmedia GC Corporation: Un procedimiento de compresión de información de vídeo, que comprende las etapas de:
- proyectar puntos de una imagen siguiente en puntos proyectados […]
Predicción residual avanzada simplificada para la 3d-hevc, del 14 de Junio de 2019, de QUALCOMM INCORPORATED: Un procedimiento de codificación de datos de vídeo, el procedimiento que comprende: determinar que un bloque actual (Actual) de una primera vista se codifica utilizando […]
Generación y codificación de imágenes integrales residuales, del 22 de Mayo de 2019, de Orange: Procedimiento de codificación de al menos una imagen integral actual (IIj) capturada por un dispositivo de captura de imágenes, que comprende las etapas siguientes: […]
Dispositivo de visualización auto-estereoscópico, del 27 de Marzo de 2019, de KONINKLIJKE PHILIPS N.V: Un dispositivo de visualización auto-estereoscópico que comprende: un medio de formación de la imagen que tiene una matriz bidimensional de píxeles de visualización […]
Dispositivo móvil de visualización 3D sin gafas, procedimiento de configuración del mismo, y procedimiento de uso del mismo, del 20 de Marzo de 2019, de SAMSUNG ELECTRONICS CO., LTD.: Un dispositivo de visualización tridimensional (3D) sin gafas que comprende: un dispositivo de visualización que comprende un monitor […]
Síntesis de visualización en vídeo 3D, del 6 de Marzo de 2019, de QUALCOMM INCORPORATED: Un procedimiento de descodificación de datos de vídeo de múltiples visualizaciones, el procedimiento que comprende: determinar si un índice […]