RECUPERACION DE DOCUMENTOS ASISTIDA POR ORDENADOR.
Método para determinar atractores de grupo (32) en un aparato (34) para determinar atractores de grupo (32) para una pluralidad de documentos (41),
donde cada documento comprende al menos un término, donde dicho método comprende: calcular, respecto de cada término, una distribución de probabilidad que indica la frecuencia de aparición de otro término, o de cada otro término que coaparece con dicho término en al menos uno de dichos documentos; calcular, respecto de cada término, la entropía de la distribución de probabilidad respectiva; seleccionar al menos una de dichas distribuciones de probabilidad como un atractor de grupo (32) según el valor de entropía respectivo
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2004/010877.
Solicitante: UNIVERSITY OF ULSTER
ST. PETERSBURG STATE UNIVERSITY.
Nacionalidad solicitante: Reino Unido.
Dirección: CROMORE ROAD, COLERAINE,COUNTY LONDONDERRY BT52 1SA.
Inventor/es: PATTERSON, DAVID, DOBRYNIN,VLADIMIR.
Fecha de Publicación: .
Fecha Concesión Europea: 25 de Noviembre de 2009.
Clasificación PCT:
- G06F17/30
Clasificación antigua:
- G06F17/30
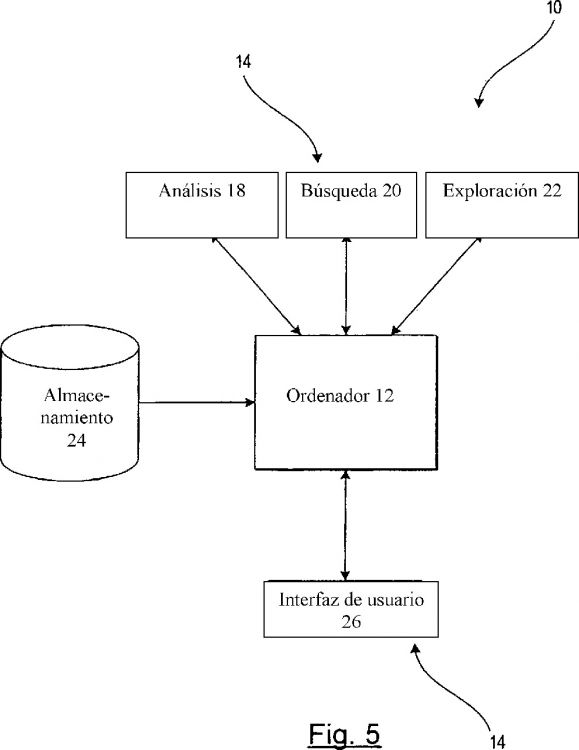
Fragmento de la descripción:
Recuperación de documentos asistida por ordenador.
Campo de la invención
La presente invención hace referencia a la recuperación de documentos asistida por ordenador desde un corpus de documentos, en especial un corpus de documentos controlado. La invención hace referencia en particular al agrupamiento de documentos asistida por ordenador.
Antecedentes de la invención
La búsqueda de documentos asistida por ordenador, generalmente, incluye la utilización de uno o más programas informáticos para analizar un corpus de documentos y después realizar una búsqueda dentro de dicho corpus de documentos analizado. El análisis de un corpus de documentos puede incluir la organización de documentos en una pluralidad de corpus de documentos para facilitar el proceso de búsqueda. Generalmente, esto incluye la utilización de uno o más programas informáticos para implementar un algoritmo de agrupamiento. La búsqueda a través de un corpus de documentos normalmente se realiza mediante un programa informático comúnmente conocido como motor de búsqueda.
Una función con un impacto importante en el diseño arquitectónico de un motor de búsqueda es el tamaño del corpus de documentos. Otra consideración importante es si el mantenimiento del corpus de documentos (agregar y eliminar documentos) está abierto a todos los usuarios (un corpus no controlado como Internet), o si el mantenimiento es controlado, por ejemplo, por un administrador, (un corpus controlado como una Intranet). En forma más general, un corpus controlado comprende un conjunto de datos controlado por un administrador o un conjunto de datos que es completamente accesible.
Los algoritmos de búsqueda convencionales entregan, como resultado de la búsqueda, una lista de documentos que deben contener todo o una parte de un conjunto de palabras claves introducidas en la consulta de un usuario. Tales sistemas determinan la relevancia del documento basándose en la frecuencia de aparición de la palabra clave, o bien mediante la utilización de referencias y enlaces entre los documentos. A menudo aparecen muchos resultados de búsqueda y el usuario no puede determinar fácilmente qué resultados son relevantes de acuerdo con sus necesidades. Por lo tanto, aunque la cobertura puede ser alta, la gran cantidad de documentos que son devueltos para alcanzar dicho objetivo resulta en poca precisión y una búsqueda laboriosa para que el usuario pueda encontrar los documentos más relevantes.
De forma adicional, un motor de búsqueda convencional devuelve una lista de documentos sin clasificar. Si el tema de consulta es relativamente amplio, esta lista puede contener documentos pertenecientes a muchos subtemas específicos.
Para poder obtener los mejores resultados a partir de algoritmos de búsqueda convencionales, que se basan en estadísticas de palabras, un usuario necesita tener conocimientos estadísticos sobre el corpus de documentos antes de realizar la consulta. Este conocimiento nunca se conoce a priori y por lo tanto el usuario rara vez formula buenas consultas. Con una búsqueda temática, es posible ofrecer conocimientos sobre descripciones de agrupaciones al usuario, lo que le permite mejorar y especificar sus consultas de manera inteligente e interactiva.
Los motores de búsqueda convencionales a menudo utilizan información adicional tal como enlaces entre páginas Web, o referencias entre documentos para mejorar los resultados de búsqueda.
El concepto de búsqueda o exploración basadas en agrupamiento de documentos es conocido (por ejemplo, la herramienta de exploración Scatter-Gather [4]). Los principales problemas de este tipo de enfoque son su aplicabilidad a aplicaciones de la vida real y la eficiencia y efectividad de los algoritmos de agrupamiento. Los algoritmos de agrupamiento no supervisados se enmarcan dentro de paradigmas jerárquicos o separadores. En general, deben determinarse similitudes entre todos los pares de documentos lo que hace que estos enfoques sean no escalables. Los enfoques supervisados requieren un conjunto de datos de capacitación que no siempre está disponible, puede aumentar el coste de un proyecto y demandar mucho tiempo de preparación.
Se considera un enfoque diferente al problema de la recuperación con enfoque temático en [5]. Este sistema utiliza un conjunto de agentes para recuperar de Internet, o filtrar de entre un grupo de noticias, documentos relevantes sobre un tema específico. Los temas se describen manualmente en forma de texto. De forma adicional, un conjunto de reglas se genera manualmente en un lenguaje de reglas especial para describir cómo comparar un documento con un tema, es decir, qué palabras de la descripción de un tema deberían utilizarse y cómo influyen estas palabras en los pesos de las categorías. La categoría de documentos resultante se determina utilizando pesos de categoría calculados y lógica difusa. La principal desventaja de este enfoque es que todas las descripciones temáticas y reglas se definen de manera manual. Es imposible predecir por adelantado cuáles son las descripciones temáticas dadas y el grupo de reglas correspondiente, suficientes para recuperar los documentos relevantes, con gran precisión y cobertura. Por lo tanto, se requiere una gran cantidad de trabajo manual e investigación para generar descripciones temáticas y reglas efectivas. Por todo esto, este enfoque no puede considerarse escalable.
El descubrimiento automático de temas a través de la generación de grupos de documentos puede basarse en técnicas tales como Probabilistic Latent Semantic Indexing (Indexación Semántica Latente Probabilística) [6]. La Indexación Semántica Latente Probabilística utiliza un modelo probabilístico y los parámetros de este modelo se calculan utilizando el algoritmo de maximización de cálculos.
En [7], se presenta otro ejemplo de un motor de búsqueda basado en enfoques teóricos de información para descubrir información sobre temas que se encuentran en el corpus de documentos. La idea principal es generar un conjunto de los llamados hilos temáticos y utilizarlo para presentar el tema de cada documento en el corpus. El hilo temático es una secuencia de palabras de un sistema fijo de clases de palabras. Estas clases se forman como resultado de un análisis de un conjunto representativo de documentos seleccionados al azar del corpus de documentos (un conjunto de entrenamiento). Palabras de diferentes clases difieren por probabilidades de aparición en el conjunto de entrenamiento y, por lo tanto, representan temas en diferentes niveles de abstracción. Un hilo es una secuencia de esas palabras en la cual la siguiente palabra pertenece a una clase más delimitada, y las palabras vecinas de esta secuencia deben aparecer en el mismo documento con una probabilidad suficientemente alta. A cada documento del corpus de documentos se le asigna uno de los hilos temáticos posibles. Se utiliza entropía cruzada como medida para seleccionar un hilo temático que sea el más relevante según el tema del documento. Este hilo temático se almacena en el índice y se utiliza en la etapa de búsqueda en lugar del documento mismo. La principal desventaja de este enfoque es que sólo una parte relativamente pequeña de la información sobre un documento se almacena en el índice y se utiliza durante la búsqueda. Además, no pueden utilizarse los hilos temáticos para agrupar documentos dentro de agrupaciones temáticas y, por lo tanto, la información sobre la estructura temática del corpus de documentos está oculta para el usuario.
La publicación de la patente US2002/0042793 presenta agrupamiento en tiempo real sin utilizar la entropía de distribuciones de probabilidad para calcular los atractores de grupos. Sería deseable mitigar los problemas antes señalados.
Resumen de la invención
Un aspecto de la invención proporciona un método para determinar atractores de grupos en un aparato para determinar atractores de grupos a partir de una pluralidad de documentos, donde cada documento comprende al menos un término, y donde dicho método comprende: calcular, respecto de cada término, una distribución de probabilidad que indique la frecuencia de aparición del otro término, o de cada otro término, que co-aparezca con dicho término en al menos uno de dichos documentos; calcular, respecto de cada término, la entropía de la distribución de probabilidad respectiva; seleccionar al menos una de dichas distribuciones de probabilidad como un atractor de grupo, según el valor de entropía respectivo.
Cada distribución de probabilidad puede comprender, respecto de cada término que co-aparezca,...
Reivindicaciones:
1. Método para determinar atractores de grupo (32) en un aparato (34) para determinar atractores de grupo (32) para una pluralidad de documentos (41), donde cada documento comprende al menos un término, donde dicho método comprende: calcular, respecto de cada término, una distribución de probabilidad que indica la frecuencia de aparición de otro término, o de cada otro término que coaparece con dicho término en al menos uno de dichos documentos; calcular, respecto de cada término, la entropía de la distribución de probabilidad respectiva; seleccionar al menos una de dichas distribuciones de probabilidad como un atractor de grupo (32) según el valor de entropía respectivo.
2. Método según la reivindicación 1, en donde cada distribución de probabilidad comprende, respecto de cada término que coaparece, un indicador que indica la cantidad total del término respectivo que coaparece en todos los documentos (41) en los cuales coaparece el término respectivo que coaparece con el término respecto del cual se calcula la distribución de probabilidad.
3. Método según la reivindicación 1 ó 2, en donde cada distribución de probabilidad comprende, respecto de cada término que coaparece, un indicador que comprende una probabilidad condicional de la aparición del término respectivo que coaparece en un documento (41) si aparece en dicho documento el término respecto del cual se calcula la distribución de probabilidad.
4. Método según cualquiera de las reivindicaciones 1 a 3, en donde cada indicador se normaliza respecto de la cantidad total de términos en el documento, o en cada documento (41) en el cual aparece el término respecto del cual se calcula la probabilidad de distribución.
5. Método según la reivindicación 1, que comprende asignar cada término a un subconjunto de una pluralidad de subconjuntos de términos según la frecuencia de aparición del término; y seleccionar, como atractor de grupo (32), la distribución de probabilidad respectiva de uno o más términos de cada subconjunto de términos.
6. Método según la reivindicación 5, en donde cada término se asigna a un subconjunto según la cantidad de documentos del corpus donde aparece el término respectivo.
7. Método según la reivindicación 5 ó 6, en donde un umbral de entropía se asigna a cada subconjunto, el método comprende seleccionar, como atractor de grupo (32), la distribución de probabilidad respectiva de uno o más términos de cada subconjunto que tiene una entropía que satisface el umbral de entropía respectiva.
8. Método según la reivindicación 7, que comprende seleccionar, como atractor de grupo (32), la distribución de probabilidad respectiva de uno o más términos de cada subconjunto que tiene una entropía que es menor o igual al umbral de entropía respectiva.
9. Método según cualquiera de las reivindicaciones de 5 a 8, en donde cada subconjunto se asocia a un rango de frecuencia y en donde los rangos de frecuencia de los subconjuntos respectivos están separados.
10. Método según cualquiera de las reivindicaciones de 5 a 9, en donde cada subconjunto se asocia a un rango de frecuencia, el tamaño de cada rango de frecuencia sucesivo es igual a una constante multiplicada por el tamaño del rango de frecuencia precedente en orden de frecuencia ascendente.
11. Método según cualquiera de las reivindicaciones 7 a 10, en donde cada umbral de entropía respectivo aumenta para subconjuntos sucesivos en orden de frecuencia ascendente.
12. Método según la reivindicación 11, en donde el umbral de entropía respectivo para subconjuntos sucesivos aumenta de manera lineal.
13. Programa informático que comprende un código de programa informático que hace que un ordenador lleve a cabo el método de la reivindicación 1.
14. Aparato (34) para determinar atractores de grupo (32) para una pluralidad de documentos (41), donde cada documento comprende al menos un término, donde el aparato comprende: medios para calcular, respecto de cada término, una distribución de probabilidad que indica la frecuencia de aparición del otro término o cada otro término que comparece con dicho término en al menos uno de dichos documentos (41); medios para calcular, respecto de cada término, la entropía de la distribución de probabilidad respectiva; y medios para seleccionar al menos una de dichas distribuciones de probabilidad como un atractor de grupo según el valor de entropía respectivo.
Patentes similares o relacionadas:
Composiciones y métodos para modelar el metabolismo de Saccharomyces cerevisiae, del 3 de Junio de 2020, de THE REGENTS OF THE UNIVERSITY OF CALIFORNIA: Un metodo implementado por computadora para proporcionar a un usuario una simulacion de una funcion fisiologica de levadura relacionada con un gen heterologo […]
Procedimiento de visualización de páginas por medio de un navegador de un equipo como una caja descodificadora Proveedor de Servicios de Internet, del 10 de Enero de 2020, de FREEBOX (100.0%): Un procedimiento de visualización de páginas por un equipo cliente equipado de un sistema cerrado, conectado a un servidor remoto , integrando […]
Procedimiento implementado por ordenador y controlado por ordenador, producto de programa informático y plataforma para disponer datos para su procesamiento y almacenamiento en un motor de almacenamiento de datos, del 4 de Noviembre de 2019, de Dynactionize N.V: Un procedimiento implementado por ordenador y controlado por ordenador de disposición de datos para procesamiento y almacenamiento de los mismos en un […]
MÉTODO DE DOBLAJE Y LOCUCIONES DE AUDIO, del 11 de Julio de 2019, de TANGO VOZ, S.L: Se describe en este documento un método que permite gestionar la producción de doblajes y locuciones de audio destinados a medios audiovisuales de tal manera que no se […]
Un sistema de control para controlar el funcionamiento de una unidad de procesamiento de datos, del 21 de Mayo de 2019, de IG Knowhow Limited: Un sistema de control para controlar el funcionamiento de una unidad de procesamiento de datos, la unidad de procesamiento de datos recibiendo una primera […]
Método para proporcionar una estructura de índice en una base de datos, del 1 de Mayo de 2019, de Capish International AB: Metodo para proporcionar una estructura de indice en una base de datos que comprende una pluralidad de tipos de objetos, donde cada tipo de objetos […]
Dispositivo de procesamiento de información, método de procesamiento de información, programa de procesamiento de información y soporte de registro, del 1 de Mayo de 2019, de RAKUTEN, INC: Dispositivo de procesamiento de información que comprende: un medio (12b) de memoria de palabra de área local que almacena una palabra de área […]
SISTEMA PARA LA DETECCIÓN REMOTA DEL USO DEL CINTURÓN DE SEGURIDAD EN UN VEHÍCULO, del 18 de Abril de 2019, de CASANOVA RENT VOLKS, S.A. DE C.V: La presente invención se refiere a la industria automotriz, particularmente está relacionada con los cinturones de seguridad con que están equipados los vehículos, […]