PROCEDIMIENTO Y APARATO PARA REALIZAR VOCODIFICACION CON TASA REDUCIDA Y TASA VARIABLE.
Un procedimiento para codificar una trama de habla, que comprende las etapas de:
derivar una pluralidad de parámetros de trama;
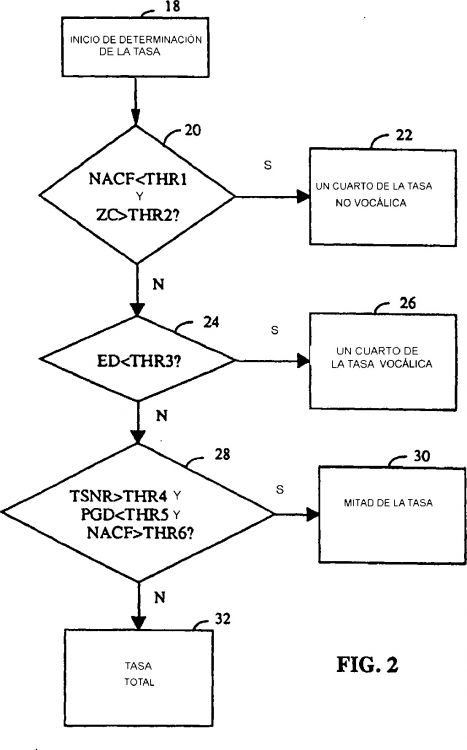
seleccionar (20) una primera modalidad de codificación, si un parámetro derivado de medición de autocorrelación normalizada (NACF) es superado por un primer valor de umbral, y si un parámetro contador de cruces por cero (ZC) supera un segundo valor de umbral;
seleccionar (24) una segunda modalidad de codificación si la primera modalidad de codificación no es seleccionada, y si un parámetro derivado (ED) de medición diferencial de energía es superado por un tercer valor de umbral, en donde el parámetro derivado (ED) de medición diferencial de energía indica una diferencia en energía entre una trama actual y las tramas anteriores;
seleccionar (28) una tercera modalidad de codificación si las modalidades de codificación primera y segunda no son seleccionadas y si un parámetro derivado de calidad de codificación (TMSNR) supera un cuarto nivel de umbral, y si un parámetro derivado de medición de diferencial de ganancia de predicción (PGD) es superado por un quinto nivel de umbral, y si el parámetro derivado de medición de autocorrelación normalizada (NACF) supera un sexto valor de umbral, en donde el parámetro derivado de calidad de codificación (TMSNR) indica el desempeño de un modelo de codificación;
seleccionar una cuarta modalidad de codificación si las modalidades de codificación primera, segunda y tercera no se seleccionan; y
codificar la trama de voz según la modalidad de codificación seleccionada
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E03005273.
Solicitante: QUALCOMM INCORPORATED.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 5775 MOREHOUSE DRIVE,SAN DIEGO, CALIFORNIA 92121.
Inventor/es: DEJACO, ANDREW, P..
Fecha de Publicación: .
Fecha Solicitud PCT: 1 de Agosto de 1995.
Fecha Concesión Europea: 9 de Junio de 2010.
Clasificación Internacional de Patentes:
- G10L19/14A1
Clasificación PCT:
- G10L19/14
Clasificación antigua:
- G10L19/12 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › Determinación o codificación de una excitación de código, p. ej. en codificadores vocales de predicción lineal excitados por código [CELP].
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Lituania, Letonia.
Fragmento de la descripción:
Procedimiento y aparato para realizar vocodificación con tasa reducida y tasa variable.
Antecedentes de la invención
La presente invención se refiere a las comunicaciones. Más en particular, la presente invención se refiere a un procedimiento y a un aparato, novedosos y mejorados, para realizar la codificación por predicción lineal excitada por código (CELP) con tasa, o velocidad, variable.
La transmisión de voz mediante técnicas digitales se ha extendido, particularmente en aplicaciones de larga distancia y de radiotelefonía digital. Esto, a su vez, ha despertado interés en determinar la menor cantidad de información que puede enviarse por el canal que mantiene la calidad percibida del habla reconstruida. Si el habla se transmite simplemente muestreando y digitalizando, se requiere una tasa de transmisión de datos del orden de 64 kilobits por segundo (kbps) para conseguir una calidad del habla del teléfono analógico convencional. Sin embargo, a través del uso de análisis del habla, seguido de la codificación, la transmisión, y la resíntesis apropiadas en el receptor, puede lograrse una reducción significativa en la tasa de transmisión de datos.
Los dispositivos que emplean técnicas para comprimir habla vocal extrayendo parámetros que se refieren a un modelo de generación del habla humana normalmente se denominan vocodificadores. Tales dispositivos están compuestos por un codificador, que analiza el habla entrante para extraer los parámetros pertinentes, y un descodificador, que resintetiza el habla utilizando los parámetros que recibe por el canal de transmisión. Con el fin de ser preciso, el modelo debe cambiar continuamente. Así el habla se divide en bloques de tiempo, o tramas de análisis, durante las cuales se calculan los parámetros. Los parámetros entonces se actualizan para cada nueva trama.
De las diversas clases de codificadores del habla la codificación por predicción lineal excitada por código (CELP), la codificación estocástica o la codificación del habla excitada por vector son de una clase. Un ejemplo de un algoritmo de codificación de esta clase particular se describe en el artículo "A 4.8kbps Code Excited Linear Predictive Coder" ["Un Codificador Predictivo Lineal Excitado por Código de 4,8 kbps"] de Thomas E. Tremain et al., Proceedings of the Mobile Satellite Conference, 1988.
La función del vocodificador es comprimir la señal del habla digitalizada en una señal de tasa de transmisión de bits baja eliminando todas las redundancias naturales inherentes al habla. El habla normalmente tiene redundancias a corto plazo debidas principalmente a la operación de filtrado del tracto vocal, y redundancias a largo plazo debidas a la excitación del tracto vocal por las cuerdas vocales. En un codificador CELP, estas operaciones se modelan mediante dos filtros, un filtro formante a corto plazo y un filtro de altura tonal a largo plazo. Una vez eliminadas estas redundancias, la señal residual resultante puede modelarse como ruido blanco gaussiano, que también debe codificarse. La base de esta técnica es calcular los parámetros de un filtro, llamado el filtro LPC, que realiza predicción a corto plazo de la onda del habla utilizando un modelo del tracto vocal humano. Además, los efectos a largo plazo, relacionados con la altura tonal del habla, se modelan calculando los parámetros de un filtro de altura tonal, que esencialmente modela las cuerdas vocales humanas. Finalmente, estos filtros deben excitarse, y esto se hace determinando cuál, de un número de ondas de excitación aleatorias en un libro de códigos (codebook), tiene como resultado la aproximación más cercana al habla original cuando la onda excita los dos filtros mencionados anteriormente. Así los parámetros transmitidos se refieren a tres elementos (1) el filtro LPC, (2) el filtro de altura tonal y (3) la excitación del libro de códigos.
Aunque el uso de técnicas de vocodificación favorece el objetivo de intentar reducir la cantidad de información enviada por el canal mientras se mantiene un habla reconstruida de calidad, es necesario emplear otras técnicas para lograr reducción adicional. Una técnica utilizada previamente para reducir la cantidad de información enviada es la interrupción momentánea de la actividad vocal. En esta técnica no se transmite ninguna información durante las pausas del habla. Aunque esta técnica logra el resultado deseado de reducción de datos, padece varias deficiencias.
En muchos casos, la calidad del habla se reduce debido al recorte de las partes iniciales de las palabras. Otro problema de interrumpir momentáneamente el canal durante la inactividad es que los usuarios del sistema perciben la falta de ruido de fondo que normalmente acompaña al habla y juzgan la calidad del canal como inferior a una llamada telefónica normal. Un problema adicional de la interrupción momentánea de la actividad es que ruidos repentinos ocasionales en el fondo pueden activar el transmisor cuando no se produce habla, lo que tiene como resultado ráfagas de ruido molestas en el receptor.
En un intento de mejorar la calidad del habla sintetizada en sistemas de desconexión de actividad vocal, se añade un murmullo de fondo sintetizado durante el proceso de descodificación. Aunque se logra alguna mejora de la calidad al añadir el murmullo de fondo, no mejora sustancialmente la calidad global, ya que el murmullo de fondo no modela el ruido de fondo real en el codificador.
Una técnica preferida para llevar a cabo la compresión de datos, a fin de que tenga como resultado una reducción de la información que se necesita enviar, es realizar vocodificación con tasa variable. Debido a que el habla contiene inherentemente periodos de silencio, es decir, pausas, la cantidad de datos requeridos para representar estos periodos puede reducirse. La vocodificación con tasa variable aprovecha de la manera más eficaz este hecho reduciendo la tasa de transmisión de datos para estos periodos de silencio. Una reducción en la tasa de transmisión de datos, en contraposición a una detención completa en la transmisión de datos, para periodos de silencio supera los problemas asociados con la interrupción momentánea de la actividad vocal mientras se facilita una reducción en la información transmitida.
La patente estadounidense Nº US 5.414.796, presentada el 14 de enero de 1993, titulada "Variable Rate Vocoder" ["Vocodificador de Tasa Variable"] y transferida al cesionario de la presente invención, detalla un algoritmo de vocodificación de la clase de codificadores del habla mencionada anteriormente, codificación por predicción lineal excitada por código (CELP), codificación estocástica o vocodificación excitada por vector. La técnica CELP por sí misma proporciona una reducción significativa en la cantidad de datos necesarios para representar el habla de una manera que, tras la resíntesis, tenga como resultado habla de alta calidad. Tal como se mencionó anteriormente, los parámetros del vocodificador se actualizan para cada trama. El vocodificador detallado en la solicitud de patente, en tramitación junto con la presente, proporciona una tasa variable de transmisión de datos de salida cambiando la frecuencia y la precisión de los parámetros del modelo.
El algoritmo de vocodificación de la solicitud de patente mencionada anteriormente difiere de manera sumamente marcada de las técnicas de CELP anteriores, produciendo una tasa variable de transmisión de datos de salida, basándose en la actividad del habla. La estructura se define para que los parámetros se actualicen con menos frecuencia, o con menos precisión, durante las pausas en el habla. Esta técnica permite un descenso incluso mayor en la cantidad de información que va a transmitirse. El fenómeno que se aprovecha para reducir la tasa de transmisión de datos es el factor de actividad vocal, que es el porcentaje medio de tiempo que un orador dado está efectivamente hablando durante una conversación. Para conversaciones telefónicas bidireccionales típicas, la tasa de transmisión de datos media se reduce en un factor de 2 o más. Durante las pausas en el habla, el vocodificador sólo está codificando el ruido de fondo. En estos momentos, no es necesario que se transmitan algunos de los parámetros relacionados con el modelo del tracto vocal humano.
Tal como se mencionó anteriormente, un enfoque anterior para limitar la cantidad de información transmitida durante el silencio se llama interrupción momentánea de actividad vocal,...
Reivindicaciones:
1. Un procedimiento para codificar una trama de habla, que comprende las etapas de:
2. El procedimiento de la reivindicación 1, en el cual la primera modalidad de codificación es una modalidad de codificación del habla no vocálica, de un cuarto de tasa, la segunda modalidad de codificación es una modalidad de codificación del habla vocálica, de un cuarto de tasa, la tercera modalidad de codificación es una modalidad de codificación de media tasa y la cuarta modalidad de codificación es una modalidad de codificación de tasa completa.
3. El procedimiento de la reivindicación 2, en el cual la modalidad de codificación del habla no vocálica, de cuarto de tasa, comprende dividir la trama de habla entre cuatro subtramas, y transmitir una pluralidad de coeficientes de filtrado de codificación predictiva lineal y, para cada subtrama, un valor de ganancia.
4. El procedimiento de la reivindicación 3, en el cual el valor de ganancia está representado por cinco bits digitales.
5. El procedimiento de la reivindicación 4, en el cual la modalidad de codificación del habla vocálica, de un cuarto de tasa, comprende dividir la trama de habla entre dos subtramas, y determinar, para cada subtrama, un índice del libro de códigos y un valor de ganancia.
6. El procedimiento de la reivindicación 5, en el cual el valor de ganancia está representado por cinco bits digitales, y el índice del libro de códigos está representado por cinco bits digitales.
7. El procedimiento de la reivindicación 6, en el cual el parámetro de calidad de codificación es una razón que indica una coincidencia entre una trama de habla anterior y una trama de habla sintetizada derivada de la misma.
8. El procedimiento de la reivindicación 7, que comprende adicionalmente la etapa de variar al menos uno entre los valores de umbral para ajustar una tasa media de codificación para una pluralidad de tramas de habla.
9. El procedimiento de la reivindicación 8, en el cual el valor de umbral es el cuarto valor de umbral.
10. El procedimiento de la reivindicación 8, en el cual la tasa media de codificación se reduce codificando una pluralidad de tramas de habla a la mitad de la tasa, en donde la pluralidad de tramas de habla codificadas a la mitad de la tasa son tramas de habla que fueron seleccionadas para ser codificadas con la tasa completa.
11. El procedimiento de la reivindicación 8, en el cual la tasa media de codificación se aumenta codificando una pluralidad de tramas de habla con la tasa completa, en donde la pluralidad de tramas de habla codificadas con la tasa completa son tramas de habla que fueron seleccionadas para ser codificadas con la mitad de la tasa.
12. Un aparato de determinación de tasa de codificación en un codificador del habla, para codificar una trama de habla, que comprende:
13. El aparato de la reivindicación 12, en el cual la primera modalidad de codificación es una modalidad de codificación del habla no vocálica, de un cuarto de tasa, la segunda modalidad de codificación es una modalidad de codificación del habla vocálica, de un cuarto de tasa, la tercera modalidad de codificación es una modalidad de codificación de media tasa, y la cuarta modalidad de codificación es una modalidad de codificación de tasa completa.
14. El aparato de la reivindicación 13, en el cual la modalidad de codificación del habla no vocálica, de un cuarto de tasa, comprende dividir la trama de habla entre cuatro subtramas, y transmitir una pluralidad de coeficientes de filtrado de codificación predictiva lineal y, para cada subtrama, un valor de ganancia.
15. El aparato de la reivindicación 14, en el cual el valor de ganancia está representado por cinco bits digitales.
16. El aparato de la reivindicación 13, en el cual la modalidad de codificación de habla vocálica, de un cuarto de tasa, comprende dividir la trama de habla entre dos subtramas y determinar, para cada subtrama, un índice del libro de códigos y un valor de ganancia.
17. El aparato de la reivindicación 16, en el cual el valor de ganancia está representado por cinco bits digitales, y el índice del libro de códigos está representado por cinco bits digitales.
18. El aparato de la reivindicación 12, en el cual el parámetro de calidad de codificación es una razón que indica una coincidencia entre una trama anterior de habla y una trama de habla sintetizada derivada de la misma.
19. El aparato de la reivindicación 12, que comprende adicionalmente medios para variar al menos uno de los valores de umbral, a fin de ajustar una tasa media de codificación para una pluralidad de tramas de habla.
20. El aparato de la reivindicación 19, en el cual el valor de umbral es el cuarto valor de umbral.
21. El aparato de la reivindicación 19, en el cual la tasa media de codificación se reduce codificando una pluralidad de tramas de habla a media tasa, en donde la pluralidad de tramas de habla codificadas a media tasa son tramas de habla que fueron seleccionadas para ser codificadas con tasa completa.
22. El aparato de la reivindicación 19, en el cual la tasa media de codificación se aumenta codificando una pluralidad de tramas de habla a tasa completa, en donde la pluralidad de tramas de habla codificadas a tasa completa son tramas de habla que fueron seleccionadas para ser codificadas a media tasa.
23. El aparato de cualquiera de las reivindicaciones 12 a 22, en el cual dichos medios (12) para derivar una pluralidad de parámetros de trama comprenden un calculador de mediciones (12) de modalidad, configurado para derivar dicha pluralidad de parámetros de trama; y en el cual dichos medios (14) para seleccionar comprenden una lógica (14) de determinación de tasa.
24. Un medio legible por procesador, con instrucciones que son ejecutables para llevar a cabo las etapas de la reivindicación 1.
Patentes similares o relacionadas:
PRE-PROCESAMIENTO DE DATOS DIGITALES DE AUDIO PARA CODECS DE AUDIO DE MÓVIL, del 2 de Enero de 2012, de REALNETWORKS ASIA PACIFIC CO., LTD: Un método para el pre-procesamiento de datos de audio que contienen datos musicales a procesar por un códec de Codificación de Velocidad Variable Reforzada, para la transmisión […]
 PROCEDIMIENTO Y APARATO DE DETECCION DE COMPONENTES TONALES DE SEÑALES DE AUDIO, del 29 de Octubre de 2010, de QUALCOMM INCORPORATED: Un procedimiento de procesamiento de señales de audio, comprendiendo dicho procedimiento:
llevar a cabo una operación de codificación en una porción de […]
PROCEDIMIENTO Y APARATO DE DETECCION DE COMPONENTES TONALES DE SEÑALES DE AUDIO, del 29 de Octubre de 2010, de QUALCOMM INCORPORATED: Un procedimiento de procesamiento de señales de audio, comprendiendo dicho procedimiento:
llevar a cabo una operación de codificación en una porción de […]
 PROCEDIMIENTO DE CODIFICACION MULTIPLE OPTIMIZADO, del 16 de Febrero de 2010, de FRANCE TELECOM: Procedimiento de codificación múltiple en compresión, en el que una señal de entrada está destinada a alimentar en paralelo al menos un primer […]
PROCEDIMIENTO DE CODIFICACION MULTIPLE OPTIMIZADO, del 16 de Febrero de 2010, de FRANCE TELECOM: Procedimiento de codificación múltiple en compresión, en el que una señal de entrada está destinada a alimentar en paralelo al menos un primer […]
Decodificación de audio estéreo paramétrico, del 9 de Enero de 2019, de DOLBY INTERNATIONAL AB: Receptor, que comprende: un demultiplexor para desmultiplexar un flujo de bits para obtener una señal mono y parámetros de amplitud estéreo; […]
Receptor y método para decodificar flujo de datos codificado estéreofónico paramétrico, del 20 de Septiembre de 2017, de DOLBY INTERNATIONAL AB: Receptor, que comprende: un demultiplexor configurado para extraer una señal monofónica codificada y parámetros de amplitud estereofónica […]
Método de codificación, método de descodificación, codificador, descodificador, programa y medio de grabación, del 29 de Marzo de 2017, de NIPPON TELEGRAPH AND TELEPHONE CORPORATION: Un método de codificación de voz o de señales acústicas que comprende adquirir códigos correspondientes a residuos de predicción obtenidos según […]
Dispositivo de codificación de sonido y procedimiento de codificación de sonido, del 25 de Enero de 2017, de III Holdings 12, LLC: Un aparato de codificación de voz que comprende: una sección de análisis de parámetro de predicción que calcula una diferencia de retardo y una relación […]
 Codificador y decodificador de audio para codificar tramas de señales de audio muestreadas, del 2 de Febrero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio adaptado para codificar tramas de una señal de audio muestreada para obtener tramas codificadas, en el que una […]
Codificador y decodificador de audio para codificar tramas de señales de audio muestreadas, del 2 de Febrero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio adaptado para codificar tramas de una señal de audio muestreada para obtener tramas codificadas, en el que una […]