PROCEDIMIENTO DE ADAPTACION DE UNA RED NEURAL DE UN DISPOSITIVO AUTOMATICO DE RECONOCIMIENTO DEL HABLA.
Procedimiento de adaptación de una red neural (NN) multicapa de de un dispositivo automático de reconocimiento del habla (ASR),
comprendiendo el procedimiento las etapas de:
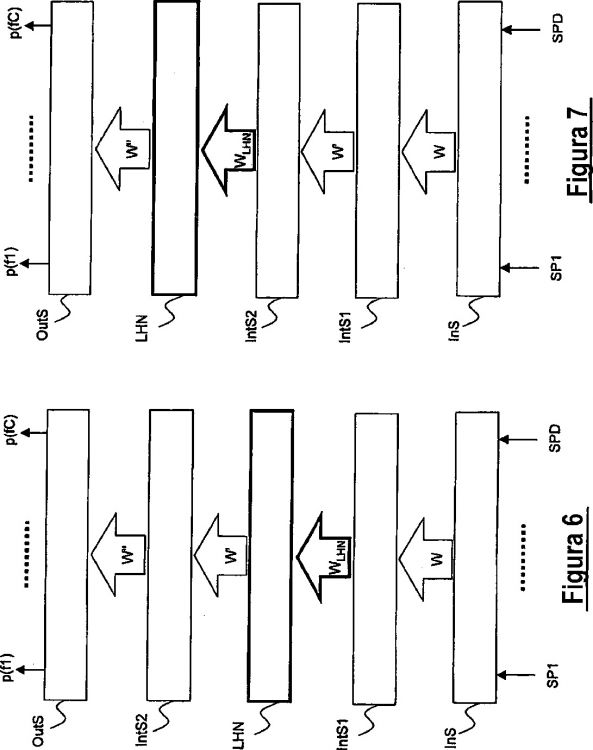
- proporcionar una red neural (NN) que comprende una etapa de entrada (Ins) para el almacenamiento de al menos una muestra de la señal del habla, una etapa intermedia (IntS, IntS1, IntS2) que tiene conexiones de entrada asociadas a una primera matriz de ponderación (W) y una etapa de salida (OutS) que tiene conexiones de entrada asociadas a una segunda matriz de ponderación (W''''), proporcionando dicha etapa de salida (OutS) probabilidades de fonemas;
- proporcionar una etapa lineal (LHN) en dicha red neural (NN), después de dicha etapa intermedia (IntS, IntS1, IntS2), teniendo dicha etapa lineal (LHN) el mismo número de nodos que dicha etapa intermedia (IntS, IntS1, IntS2); y
- entrenar dicha etapa lineal (LHN) mediante un conjunto de adaptación, manteniéndose dicha primera matriz de ponderación (W) y dicha segunda matriz de ponderación (W'''') fijas durante dicho entrenamiento
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2005/052510.
Solicitante: LOQUENDO S.P.A..
Nacionalidad solicitante: Italia.
Dirección: VIA ARRIGO OLIVETTI 6,10100 TORINO.
Inventor/es: GEMELLO,ROBERTO,LOQUENDO S.P.A, MANA,FRANCO,LOQUENDO S.P.A.
Fecha de Publicación: .
Fecha Concesión Europea: 23 de Diciembre de 2009.
Clasificación Internacional de Patentes:
- G10L15/06A
- G10L15/16 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad). › utilizando redes neuronales artificiales.
Clasificación PCT:
Fragmento de la descripción:
Procedimiento de adaptación de una red neural de un dispositivo automático de reconocimiento del habla.
La presente invención se refiere al campo del reconocimiento automático del habla. Más concretamente, la presente invención se refiere a un procedimiento de adaptación de una red neural de un dispositivo automático de reconocimiento del habla, una red neural adaptada correspondiente y un dispositivo automático de reconocimiento del habla correspondiente.
Un dispositivo automático de reconocimiento del habla es un aparato que es capaz de reconocer señales del habla, tales como palabras o frases pronunciadas en un idioma predefinido.
Un dispositivo automático de reconocimiento del habla puede utilizarse, por ejemplo, en dispositivos para la conversión de señales del habla en texto escrito o para la detección de una palabra clave que permite a un usuario acceder a un servicio. Además, un dispositivo automático de reconocimiento del habla puede utilizarse en sistemas de soporte a servicios de telefonía particulares, tal como el suministro a un usuario del número de teléfono de un abonado de teléfono determinado.
Con el fin de reconocer una señal del habla, un dispositivo automático de reconocimiento del habla realiza las etapas que se describen brevemente aquí posteriormente.
El dispositivo automático de reconocimiento del habla recibe la señal del habla para ser reconocida a través de un canal fónico. Ejemplos de canales fónicos son un canal de una red de telefonía fija, de una red de telefonía móvil, o el micrófono de un ordenador.
La señal del habla, en primer lugar, se convierte en una señal digital. La señal digital es muestreada periódicamente con un periodo de muestreo determinado, normalmente de unos pocos milisegundos. Cada muestra comúnmente se denomina "marco". Sucesivamente, cada marco se asocia con un conjunto de parámetros del espectro que describe el espectro del habla del marco.
A continuación, este conjunto de parámetros espectrales se envían a un bloque de patrón de coincidencia. Para cada fonema del idioma para el que está destinado el dispositivo automático de reconocimiento del habla, el bloque de patrón de coincidencia calcula la probabilidad de que la estructura asociada al conjunto de los parámetros del espectro corresponda al fonema.
Como es sabido, un fonema es la más pequeña porción de una señal del habla que, en sustitución de un primer fonema con un segundo fonema de una señal del habla en un idioma determinado, se pueden obtener dos significados diferentes de la lengua.
Una señal del habla comprende una secuencia de fonemas y transiciones entre fonemas sucesivos.
Para simplificar, en la siguiente descripción y en las reivindicaciones, el término "fonema" comprenderá tanto los fonemas definidos anteriormente como las transiciones entre fonemas sucesivos.
Así, hablando en general, el bloque de patrón de coincidencia calcula una probabilidad alta para el fonema que corresponde a un fotograma de entrada, una baja probabilidad para fonemas con el espectro del habla similar a la del espectro del habla del marco de entrada, y una probabilidad cero para fonemas con un espectro del habla diferente del espectro del habla del marco de entrada.
Sin embargo, los marcos correspondientes al mismo fonema pueden estar asociados a diferentes conjuntos de parámetros espectrales. Esto se debe al hecho de que el espectro del habla de un fonema depende de diferentes factores, tales como las características del canal fónico, del hablante y del ruido que afectan a la señal del habla.
Las probabilidades de fonemas asociados a los marcos sucesivas se emplean, junto con los datos de otros idiomas (como, por ejemplo, el vocabulario, las reglas de la gramática, y/o reglas de sintaxis) para reconstruir las palabras o frases que corresponden a la secuencia de marcos.
Tal como ya se mencionó, la etapa del cálculo de probabilidades de fonemas de un marco de entrada se realiza mediante un bloque de patrón de coincidencia. Por ejemplo, el bloque de patrón de coincidencia puede aplicarse a través de una red neural.
Una red neural es una red compuesta por al menos una unidad de cálculo, que se llama "neurona".
Una neurona es una unidad de computación adaptada para calcular un valor de salida en función de una pluralidad de valores de entrada (también llamado "patrón"). Una neurona recibe la pluralidad de valores de entrada a través de una pluralidad de conexiones de entrada correspondientes. Cada conexión de entrada se asocia a una ponderación respectiva. Cada valor de entrada, en primer lugar, se multiplica por la ponderación respectiva. Entonces, la neurona suma todos los valores de entrada ponderados. También puede agregar una desviación, es decir:

en donde a es la combinación lineal ponderada de los valores de entrada, wi es la i-ésima ponderación de conexión de entrada, xi es el i-ésimo valor de entrada y b es la desviación. En el siguiente, para simplificar, se supondrá que la desviación es cero.
Sucesivamente, la neurona transforma la suma lineal en [1] de acuerdo con una función de activación G (.). La función de activación puede ser de diferentes tipos. Por ejemplo, puede ser una función de Heaviside (función de umbral), o una función sigmoidea. Una función sigmoidea común se define mediante la siguiente fórmula:

Este tipo de función sigmoidea es una función limitada [0, 1] cada vez mayor, por lo que está adaptada para representar una función de probabilidad.
La función de activación también puede ser una función lineal, por ejemplo, g (a) = k * a, donde k es una constante, en este caso, la neurona se llama "neurona lineal".
Normalmente, una red neural empleada en un dispositivo automático de reconocimiento del habla es una red neural multicapa.
Una red neural multicapa consta de una pluralidad de neuronas, que se agrupan en dos o más etapas en cascada. Típicamente, las neuronas de una misma etapa tienen la función de activación.
Una red neural multicapa normalmente consta de una etapa de entrada, que incluye una memoria intermedia para almacenar un patrón de entrada. En el campo de reconocimiento del habla, este patrón de entrada comprende un conjunto de parámetros espectrales de un marco de entrada, y series de parámetros espectrales de unos pocos marcos anteriores y posteriores al marco de entrada. En total, un patrón típicamente comprende conjuntos de parámetros espectrales de siete o nueve marcos consecutivos.
La etapa de entrada suele estar conectada con una etapa intermedia (u "oculta"), que comprende una pluralidad de neuronas. Cada conexión de entrada de cada neurona de la etapa intermedia se adapta para recibir de la etapa de entrada un parámetro espectral respectivo. Cada neurona de la etapa intermedia calcula un valor de salida correspondiente de acuerdo con las fórmulas [1] y [2].
La etapa intermedia está típicamente conectada con una etapa de salida, que también comprende una pluralidad de neuronas. Cada neurona de la etapa de salida tiene un número de conexiones de entrada que es igual al número de neuronas de la etapa intermedia. Cada conexión de entrada de cada neurona de la etapa de salida está conectada a una neurona respectiva de la etapa intermedia. Cada neurona de la etapa de salida calcula un valor de salida correspondiente en función de los valores de salida de la etapa intermedia.
En el campo del reconocimiento del habla, cada neurona de la etapa de salida está asociada con un fonema correspondiente. Así, el número de neuronas de la etapa de salida es igual al número de fonemas. El valor de salida calculado por cada neurona de la etapa de salida es la probabilidad de que el marco asociado al patrón de entrada se corresponda con el fonema asociado a la neurona de la etapa de salida.
Para simplificar, una red multicapa con una sola etapa intermedia se ha descrito anteriormente. Sin embargo, una red multicapa puede comprender un mayor número de etapas intermedias en cascada (normalmente dos o tres) entre la etapa de entrada y la etapa de salida.
Para que una red neural adquiera la capacidad...
Reivindicaciones:
1. Procedimiento de adaptación de una red neural (NN) multicapa de de un dispositivo automático de reconocimiento del habla (ASR), comprendiendo el procedimiento las etapas de:
- proporcionar una red neural (NN) que comprende una etapa de entrada (Ins) para el almacenamiento de al menos una muestra de la señal del habla, una etapa intermedia (IntS, IntS1, IntS2) que tiene conexiones de entrada asociadas a una primera matriz de ponderación (W) y una etapa de salida (OutS) que tiene conexiones de entrada asociadas a una segunda matriz de ponderación (W''), proporcionando dicha etapa de salida (OutS) probabilidades de fonemas;
- proporcionar una etapa lineal (LHN) en dicha red neural (NN), después de dicha etapa intermedia (IntS, IntS1, IntS2), teniendo dicha etapa lineal (LHN) el mismo número de nodos que dicha etapa intermedia (IntS, IntS1, IntS2); y
- entrenar dicha etapa lineal (LHN) mediante un conjunto de adaptación, manteniéndose dicha primera matriz de ponderación (W) y dicha segunda matriz de ponderación (W'') fijas durante dicho entrenamiento.
2. Procedimiento según la reivindicación 1, en el que la etapa de entrenamiento de dicha etapa lineal (LHN) comprende el entrenamiento de dicha etapa lineal (LHN), de modo que la probabilidad de fonemas de un fonema que pertenece a señales del habla no comprendidas en dicho conjunto de adaptación es igual a la probabilidad de fonemas de dicho fonema calculada por dicha red neural (NN) antes de la etapa de proporcionar una etapa lineal (LHN).
3. Procedimiento según la reivindicación 2, en el que la etapa de entrenamiento de dicha etapa lineal (LHN) comprende el entrenamiento de dicha etapa lineal (LHN), de modo que la probabilidad de fonemas del fonema correspondiente a una muestra de señal del habla de dicho conjunto de adaptación se calcula restando las probabilidades de fonemas de todos los fonemas que pertenecen a dichas señales del habla no comprendidas en dicho conjunto de adaptación desde 1.
4. Procedimiento según la reivindicación 3, en el que la etapa de entrenamiento de dicha etapa lineal (LHN) comprende el entrenamiento de dicha etapa lineal (LHN), de modo que la probabilidad de fonemas de los fonemas restantes es igual a cero.
5. Procedimiento según cualquiera de las reivindicaciones 1 a 4, en el que la etapa de proporcionar dicha etapa lineal (LHN) comprende la etapa de proporcionar dicha etapa lineal (LHN) entre dicha etapa intermedia (IntS) y dicha etapa de salida (OutS).
6. Procedimiento según cualquiera de las reivindicaciones 1 a 4, en el que la etapa de proporcionar dicha red neural (NN) comprende la etapa de proporcionar una red neural (NN) que comprende dos etapas intermedias (Int1, Int2) y en el que la etapa de proporcionar dicha etapa lineal (LHN) comprende proporcionar dicha etapa lineal (LHN) entre dichas dos etapas intermedias (IntS1, IntS2).
7. Procedimiento según cualquiera de las reivindicaciones anteriores, en el que la etapa de entrenamiento de dicha etapa lineal (LHN) comprende la etapa de entrenamiento de dicha etapa lineal (LHN) mediante un algoritmo de propagación de errores de vuelta.
8. Procedimiento según cualquiera de las reivindicaciones anteriores, que también comprende una etapa de proporcionar una etapa equivalente obtenida mediante la combinación de dicha etapa lineal (LHN) y la siguiente etapa intermedia (IntS2) o la etapa de salida (OutS).
9. Módulo de computación de una red neural (NN) multicapa, que comprende una etapa de entrada (Ins) para el almacenamiento de al menos una muestra de señal del habla, una etapa intermedia (IntS, IntS1, IntS2) que tiene conexiones de entrada asociadas a una primera matriz de ponderación (W), una etapa de salida (OutS) que tiene conexiones de entrada asociadas a una segunda matriz de ponderación (W''), y una etapa lineal (LHN), que está adaptada para ser entrenada mediante un conjunto de adaptación, manteniéndose dicha primera matriz de ponderación (W) y dicha segunda matriz de ponderación (W'') fijas mientras dicha etapa lineal (LHN) se entrena, estando adaptada dicha etapa de salida (OutS) a las probabilidades de fonemas de salida, en donde dicha etapa lineal (LHN) se proporciona después de dicha etapa intermedia (IntS, IntS1, IntS2), teniendo dicha etapa lineal (LHN) el mismo número de nodos que dicha etapa intermedia (IntS, IntS1, IntS2).
10. Red neural según la reivindicación 9, en la que dicha etapa lineal (LHN) está adaptada para ser entrenada de tal forma que la probabilidad de fonemas de un fonema perteneciente a las señales del habla no comprendidas en dicho conjunto de adaptación es igual a la probabilidad de fonemas de dicho fonema calculado mediante dicha red neural (NN) antes de la etapa de proporcionar una etapa lineal (LHN).
11. Red neural según la reivindicación 10, en la que dicha etapa lineal (LHN) está adaptada para ser entrenada de manera que la probabilidad de fonemas del fonema correspondiente a una muestra de señal del habla de dicho conjunto de adaptación se calcula restando las probabilidades de fonemas de todos los fonemas que pertenecen a dichas señales del habla no comprendidas en dicho conjunto de adaptación desde 1.
12. Red neural según la reivindicación 11, en la que dicha etapa lineal (LHN) está adaptada para ser entrenada de tal manera que la probabilidad de fonemas de los fonemas restantes es igual a cero.
13. Red neural según cualquiera de las reivindicaciones 9 ó 12, en la que dicha etapa lineal (LHN) se proporciona entre dicha etapa intermedia (IntS) y dicha etapa de salida (OutS).
14. Red neural según cualquiera de las reivindicaciones 9 ó 12, en el que la red neural (NN) comprende dos fases intermedias (Int1, Int2) y dicha etapa lineal (LHN) se proporciona entre dichas dos etapas intermedias (IntS1, IntS2).
15. Red neural según cualquiera de las reivindicaciones 9 a 14, en la que dicha etapa lineal (LHN) está adaptada para ser entrenada mediante un algoritmo de propagación de errores de vuelta.
16. Red neural según cualquiera de las reivindicaciones 9 a 15, en la que la red neural (NN) comprende una etapa equivalente obtenida mediante la combinación de dicha etapa lineal (LHN) y la siguiente etapa intermedia (IntS2) o la etapa de salida (OutS).
17. Dispositivo automático de reconocimiento del habla (ASR) que comprende un bloque de patrón de coincidencia (PM) que comprende una red neural (NN) según cualquiera de las reivindicaciones 9 a 16.
18. Programa de ordenador que comprende medios de código de programa informático adaptados para realizar todas las etapas según cualquiera de las reivindicaciones 1 a 8, cuando dicho el programa se ejecuta en un ordenador.
19. Medio legible por ordenador que tiene un programa grabado en el mismo, comprendiendo dicho medio legible por ordenador medios de código de programa informático adaptados para realizar todas las etapas según cualquiera de las reivindicaciones 1 a 8, cuando dicho programa se ejecuta en un ordenador.
Patentes similares o relacionadas:
Sistema y método para reconocer un comando de voz de usuario en un entorno con ruido, del 1 de Abril de 2015, de Veovox SA: Sistema automático de reconocimiento de voz para reconocer un comando de voz de usuario en un entorno con ruido, que comprende: - unos medios de concordancia para […]
RED NEURONAL Y APLICACION DE LA MISMA PARA EL RECONOCIMIENTO DE VOZ., del 1 de Septiembre de 2004, de SWISSCOM AG: Sistema de redes neuronales comprendiendo una pluralidad de niveles de redes neuronales interconectadas , incluyendo cada una de dichas redes neuronales interconectadas […]
 SISTEMA DE RECONOCIMIENTO DE LA VOZ QUE USA ADAPTACION IMPLICITA DEL HABLANTE, del 16 de Enero de 2008, de QUALCOMM INCORPORATED: Un aparato de reconocimiento de la voz que comprende: un modelo acústico independiente del hablante; un modelo acústico dependiente del hablante que está […]
SISTEMA DE RECONOCIMIENTO DE LA VOZ QUE USA ADAPTACION IMPLICITA DEL HABLANTE, del 16 de Enero de 2008, de QUALCOMM INCORPORATED: Un aparato de reconocimiento de la voz que comprende: un modelo acústico independiente del hablante; un modelo acústico dependiente del hablante que está […]
 PROCEDIMIENTO DE FUNCIONAMIENTO DE UN RECONOCEDOR AUTOMATICO DE VOZ PARA EL RECONOCIMIENTO POR VOZ, INDEPENDIENTE DEL ORADOR, DE PALABRAS EN DISTINTOS IDIOMAS Y RECONOCEDOR AUTOMATICO DE VOZ, del 1 de Octubre de 2007, de SIEMENS AKTIENGESELLSCHAFT: Procedimiento de funcionamiento de un reconocedor automático de voz para el reconocimiento por voz, independiente del orador, de palabras de […]
PROCEDIMIENTO DE FUNCIONAMIENTO DE UN RECONOCEDOR AUTOMATICO DE VOZ PARA EL RECONOCIMIENTO POR VOZ, INDEPENDIENTE DEL ORADOR, DE PALABRAS EN DISTINTOS IDIOMAS Y RECONOCEDOR AUTOMATICO DE VOZ, del 1 de Octubre de 2007, de SIEMENS AKTIENGESELLSCHAFT: Procedimiento de funcionamiento de un reconocedor automático de voz para el reconocimiento por voz, independiente del orador, de palabras de […]
 METODO PARA ACELERAR LA EJECUCION DE REDES NEURONALES DE RECONOCIMIENTO DE LA VOZ Y EL MECANISMO DE LA VOZ RELACIONADO, del 1 de Octubre de 2007, de LOQUENDO S.P.A.: Procedimiento para acelerar la ejecución de redes neuronales en un sistema de reconocimiento del habla, para reconocer palabras contenidas en un subconjunto de […]
METODO PARA ACELERAR LA EJECUCION DE REDES NEURONALES DE RECONOCIMIENTO DE LA VOZ Y EL MECANISMO DE LA VOZ RELACIONADO, del 1 de Octubre de 2007, de LOQUENDO S.P.A.: Procedimiento para acelerar la ejecución de redes neuronales en un sistema de reconocimiento del habla, para reconocer palabras contenidas en un subconjunto de […]
Creación de una base de datos de referencia de parámetros de habla para clasificar expresiones del habla, del 24 de Enero de 2018, de VOICESENSE LTD.: Un método implementado por ordenador de creación de una base de datos de referencia de parámetros de habla para clasificar expresiones del habla según diversas características […]
Mapeo de una enunciación de audio a una acción usando un clasificador, del 23 de Agosto de 2017, de Google LLC: Un método, que comprende: recibir , mediante un dispositivo informático , una enunciación de audio; determinar una cadena de texto […]
 METODO PARA ADAPTAR DINAMICAMENTE LOS MODELOS ACUSTICOS DE RECONOCIMIENTO DEL HABLA AL USUARIO, del 17 de Diciembre de 2009, de FRANCE TELECOM ESPAA, S.A.: Método para adaptar dinámicamente los modelos acústicos de reconocimiento del habla al usuario, que permite mejorar la eficiencia de los sistemas de reconocimiento […]
METODO PARA ADAPTAR DINAMICAMENTE LOS MODELOS ACUSTICOS DE RECONOCIMIENTO DEL HABLA AL USUARIO, del 17 de Diciembre de 2009, de FRANCE TELECOM ESPAA, S.A.: Método para adaptar dinámicamente los modelos acústicos de reconocimiento del habla al usuario, que permite mejorar la eficiencia de los sistemas de reconocimiento […]