MÉTODOS DE ALEATORIZACIÓN Y DESALEATORIZACIÓN DE UNIDADES DE DATOS.
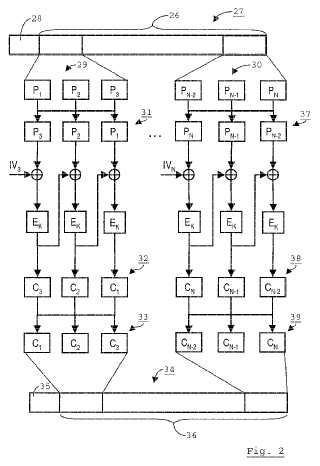
Método de aleatorización de un flujo de datos, que incluye obtener a partir de la sucesión de las primeras secuencias (29,
30) de bloques (Pi) de datos,
invertir el orden de los bloques (Pi) en cada una de las primeras secuencias (29, 30) de los bloques para formar segundas secuencias respectivas de bloques de datos, y
y codificar los bloques en cada segunda secuencia (31, 37) de bloques usando una cifra (Ek) en el bloque a modo de encadenamiento, inicializado con un vector de inicialización respectivo (IV3, IVN) para cada segunda secuencia (31, 37) de bloques,
caracterizadopor el hecho de que,
para una sucesión de primeras secuencias (29, 30) de bloques incluida en una unidad (26) de datos en el flujo, al menos un vector de inicialización (IVN) usado para codificar una segunda secuencia (37) de bloques formados a partir de una primera secuencia (30) de bloques en la unidad de datos es generado en función de al menos un bloque en una primera secuencia precedente (29) de los bloques de la unidad.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E05110495.
Solicitante: IRDETO ACCESS B.V..
Nacionalidad solicitante: Países Bajos.
Dirección: JUPITERSTRAAT 42 2132 HD HOOFDDORP PAISES BAJOS.
Inventor/es: VAN DE VEN,ANTONIUS,JOHANNES,PETRUS,MARIA.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- H04L9/06 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04L TRANSMISION DE INFORMACION DIGITAL, p. ej. COMUNICACION TELEGRAFICA (disposiciones comunes a las comunicaciones telegráficas y telefónicas H04M). › H04L 9/00 Disposiciones para las comunicaciones secretas o protegidas. › utilizando el aparato de cifrado registros de desplazamiento o memorias para la codificación por bloques, p. ej. sistema DES.
PDF original: ES-2376818_T3.pdf
Fragmento de la descripción:
Métodos de aleatorización y desaleatorización de unidades de datos.
La invención se refiere a un método de aleatorización de un flujo de datos, que incluye el hecho de
obtener del flujo una sucesión de primeras secuencias de bloques de datos,
invertir el orden de los bloques en cada una de las primeras secuencias de bloques para formar segundas secuencias respectivas de bloques de datos, y codificar los bloques en cada segunda secuencia de bloques usando un modo de encadenamiento de cifra en bloque, iniciado con un vector de inicialización respectivo para cada segunda secuencia de bloques.
La invención también se refiere a un sistema para codificar un flujo de datos, que incluye
una entrada para recibir el flujo en una sucesión de primeras secuencias de bloques de datos,
una pluralidad de registros y al menos una unidad lógica para la inversión del orden de los bloques en cada una de las primeras secuencias de bloques para formar segundas frecuencias respectivas de bloques de datos, y
una disposición de tratamiento para la codificación de los bloques en cada segunda secuencia de bloques que usa un modo de encadenamiento de cifra en bloque, iniciado con un vector de inicialización respectivo para cada segunda secuencia de bloques.
La invención también se refiere a un método de descodificación de un flujo de datos aleatorizados para formar un flujo de datos, que incluye el hecho de
obtener del flujo de datos aleatorizados una sucesión de secuencias de bloques de datos aleatorizados, y descodificar cada secuencia de bloques de datos aleatorizados para formar una secuencia asociada de bloques de datos desaleatorizados, mediante el uso de una cifra de descifrado en modo de encadenamiento inverso, donde, para descodificar una secuencia de bloques de datos aleatorizados,
un bloque final en la secuencia de bloques de datos desaleatorizados se obtiene mediante la aplicación de la cifra de descifrado a un bloque final en la secuencia asociada de bloques de datos aleatorizados y por aplicación de un operador que tiene como operandos al menos el resultado de la cifra de descifrado y un vector de inicialización, y donde cada bloque que precede el bloque final en la secuencia de bloques de datos desaleatorizados se obtiene mediante la aplicación de la cifra de descifrado a un bloque en la secuencia de bloques de datos aleatorizados en una posición correspondiente y por aplicación de un operador que tiene como operandos al menos el resultado de la cifra de descodificación y un bloque de datos aleatorizados en una posición contigua en la secuencia de bloques de datos aleatorizados.
La invención también se refiere a un sistema para descodificar un flujo de datos aleatorizados para formar un flujo de datos, que incluye
una entrada para recibir el flujo de datos aleatorizados como una sucesión de secuencias de bloques de datos aleatorizados, y una disposición de tratamiento para descodificar cada secuencia de bloques de datos aleatorizados para formar una secuencia asociada de bloques de datos desaleatorizados, usando un cifra de descifrado en modo de encadenamiento inverso, donde, para descodificar una secuencia de bloques de datos aleatorizados, se obtiene un bloque final de datos desaleatorizados en la secuencia por aplicación de la cifra de descifrado a un bloque final en la secuencia asociada de bloques de datos aleatorizados y la aplicación de un operador que tiene como operandos al menos el resultado de la cifra de descifrado y un vector de inicialización, y donde cada bloque precedente de datos desaleatorizados en la secuencia se obtiene por aplicación de la cifra de descifrado a un bloque en la secuencia de bloques de datos aleatorizados en una posición correspondiente y por aplicación de un operador que tiene como operandos al menos el resultado de la cifra de descifrado y un bloque de datos desaleatorizados en una posición siguiente en la secuencia de bloques de datos aleatorizados.
La invención también se refiere a un aparato para el envío y la recepción de datos.
La invención también se refiere a un programa informático.
Ejemplos respectivos de tales métodos y sistemas son conocidos gracias a la WO 95/10906. En el método conocido, los datos digitales se dividen en paquetes de N bloques, X(1), X(2), ... X(N), donde cada bloque tiene 2m bits. La secuencia de bloques se invierte antes de la operación de encriptación en X(N), X(N-1), ..., X(1). Esta secuencia de bloques se codifica por el algoritmo de encriptación E de la siguiente manera (donde ^ se utiliza para indica un operador OR (XOR) exclusivo).
La secuencia de estos bloques codificados se invierte de nuevo, de tal modo que la secuencia Y(N), Y(N-1), ... Y(1) se transfiere al receptor.
En el lado de receptor, los bloques de datos originales se obtienen mediante el algoritmo de descodificación D de la siguiente manera:
El método usado en el sistema conocido se indica como encadenamiento de bloque de cifra inversa o método RCBC. Muestra la ventaja de que se requiere una memoria tampón en el receptor para almacenar sólo dos bloques de datos.
Un problema del método y sistema conocidos es que requiere un tampón en el lado emisor con la capacidad de almacenar N bloques para implementar la inversión de la secuencia de bloques. Esto llega a ser un problema cuando hay muchos remitentes de datos aleatorizados en un sistema de comunicación de datos, o cuando un dispositivo tiene que funcionar como emisor y receptor de datos.
Es un objeto de la presente invención proporcionar métodos, sistemas, un aparato y programa informático de los tipos indicado en los párrafos iniciales que se puedan implementar más eficazmente mientras proporcionan un nivel aceptable de protección de contenido.
Este objeto se consigue por el método de codificación de un flujo de datos según la invención, que se caracteriza en que, para una sucesión de primeras secuencias de bloques incluidos en una unidad de datos en el flujo, al menos un vector de inicialización para la codificación de una segunda secuencia de bloques formados a partir de una primera secuencia de bloques en la unidad se genera en dependencia de al menos un bloque en una primera secuencia precedente de bloques de la unidad.
Debido a que la unidad de datos incluye una sucesión de primeras secuencias de bloques, cada primera secuencia de bloques está formada por bloques menores, lo que significa que se requiere menos memoria tampón para invertir el orden de los bloques. Esto es posible con un nivel aceptable de seguridad ya que al menos dos de las segundas secuencias de bloques son efectivamente encadenadas. Este encadenamiento se debe al hecho de que al menos un vector de inicialización -cada uno excepto el primero en caso de seguridad máxima- es requerido para codificar una segunda secuencia de bloques formados a partir de una primera secuencia de bloques y se genera en función de al menos un bloque en una primera secuencia precedente de bloques de la unidad.
En una forma de realización, los vectores de inicialización respectivos para la codificación de los bloques en cada segunda secuencia de bloques formados a partir de una primera secuencia de bloques se generan en función de al menos un bloque de datos anterior a un último bloque en la misma primera secuencia.
Esto tiene como efecto el hecho de conseguir una mayor variación en los vectores de inicialización. Incluso los bloques de una primera de las primeras secuencias de bloques en la sucesión incluida en una unidad se aleatorizan usando un vector de inicialización que tiene una gran probabilidad de ser único. La variación se asegura mediante la generación del vector de inicialización en dependencia de al menos un bloque de datos precedente a un último bloque de datos en la misma primera secuencia. Debido a la inversión del orden de los bloques en cada primera secuencia, uno o más bloques de datos en dependencia del cual se genera el vector de inicialización se vuelve disponible durante la descodificación antes de que el descodificador requiera el vector de inicialización. Así, la singularidad del vector de inicialización para cada primera secuencia en la sucesión de primeras secuencias incluidas en la unidad es alcanzable... [Seguir leyendo]
Reivindicaciones:
1. Método de aleatorización de un flujo de datos, que incluye obtener a partir de la sucesión de las primeras secuencias (29, 30) de bloques (Pi) de datos,
invertir el orden de los bloques (Pi) en cada una de las primeras secuencias (29, 30) de los bloques para formar segundas secuencias respectivas de bloques de datos, y
y codificar los bloques en cada segunda secuencia (31, 37) de bloques usando una cifra (Ek) en el bloque a modo de encadenamiento, inicializado con un vector de inicialización respectivo (IV3, IVN) para cada segunda secuencia (31, 37) de bloques,
caracterizado por el hecho de que,
para una sucesión de primeras secuencias (29, 30) de bloques incluida en una unidad (26) de datos en el flujo, al menos un vector de inicialización (IVN) usado para codificar una segunda secuencia (37) de bloques formados a partir de una primera secuencia (30) de bloques en la unidad de datos es generado en función de al menos un bloque en una primera secuencia precedente (29) de los bloques de la unidad.
2. Método según la reivindicación 1, donde vectores de inicialización respectivos (IV3, IVN) para codificar los bloques en cada segunda secuencia (31, 37) de bloques formado por una primera secuencia (29, 30) de bloques generado en función de al menos un bloque de datos que precede el último bloque de la misma secuencia (29, 30).
3. Método según la reivindicación 1 o 2, donde cada vector de inicialización (IVN) se genera en función de al menos un bloque en cada una de cualquiera de las primeras secuencias precedentes (29) de bloques de la unidad (26).
4. Método según cualquiera de las reivindicaciones 1 a 3, que incluye la recepción de un paquete de datos (27) que comprende un membrete (28) y una carga útil (26), donde la unidad es formada por el la carga útil.
5. Método según cualquiera de las reivindicaciones 1 a 4, donde la cifra (Ek) es una cifra de bloque configurado para funcionar en bloques básicos de tamaño predeterminado, donde los bloques (Pi) en al menos las segundas secuencias (31, 37) de datos corresponden en tamaño al tamaño de bloque básico.
6. Método según la reivindicación 5, donde, si la unidad (26) se constituye de la sucesión de primeras secuencias (29, 30) de bloques y la cantidad sucesiva de datos cuyo tamaño es inferior a un múltiple del tamaño del bloque básico,
la cantidad de datos se completa en un tamaño igual al múltiple del tamaño de un bloque básico para formar una primera secuencia final de al menos dos bloques,
los dos últimos bloques de la primera secuencia final de bloques se intercambian y el orden de los bloques en la primera secuencia final de bloques se invierte para formar una segunda secuencia final (40) de bloque de datos, los bloques de la segunda secuencia final (40) de bloques se codifican utilizando la cifra (Ek) a modo de encadenamiento de bloques, inicializado por un vector de inicialización (IVN) generado en función de al menos un bloque en una primera secuencia precedente (29, 30) de bloques de la unidad.
7. Método según la reivindicación 5, donde, si la unidad está constituida por cero o más primeras secuencias de un número predeterminado de bloques y por una cantidad de datos (PN) cuyo tamaño es igual a menos del tamaño del bloque básico,
la cantidad de datos se completa hasta un tamaño igual al tamaño de un bloque básico para formar un bloque final (42), la cantidad de datos se completa hasta alcanzar un tamaño igual al tamaño de un bloque básico para formar un bloque final (42), el bloque final (42) se codifica usando la cifra (Ek) a modo de encadenamiento de bloques, inicializado por un vector de inicialización generado en función de al menos un bloque en al menos una de cualquiera de las secuencias precedentes de bloques de la unidad.
8. Método según la reivindicación 7, donde el vector de inicialización se genera aplicando una operación criptográfica (Dk), preferiblemente una descodificación que es la inversa de la cifra, en un vector (IVN) basado en al menos un vector (IV0) que es independiente de cualquier bloque en cualquier primera secuencia precedente de bloques de la unidad.
9. Sistema de aleatorización de un flujo de datos, que incluye
una entrada para recibir el flujo a modo de sucesión de primeras secuencias (29, 30) de bloques (Pi) de datos, una pluralidad de registros y al menos una unidad lógica para invertir el orden de los bloques en cada una de las primeras secuencias (29, 39) de bloques (Pi) para formar segundas secuencias respectivas (31, 37) de bloques de datos, y
una disposición de procesamiento para codificar los bloques en cada segunda secuencia (31, 37) de bloques usando una cifra (Ek) a modo de encadenamiento de bloques, inicializado con un vector de inicialización respectivo (IV3, IVN) para cada segunda secuencia (31, 37) de bloques,
caracterizado por el hecho de que,
el sistema se dispone, para una sucesión de primeras secuencias (29, 30) de bloques incluidos en una unidad (26) de datos en el flujo, para generar al menos un vector de inicialización (IVN) usado para codificar una segunda secuencia (37) de bloques formada a partir de una primera secuencia (30) de bloques en la unidad de datos en función de al menos un bloque en una primera secuencia precedente (29) de bloques de la unidad (26).
10. Sistema según la reivindicación 9, configurado para ejecutar un método según cualquiera de las reivindicaciones 1 a 8.
11. Método de desaleatorización de un flujo de datos aleatorizados para formar un flujo de datos, que incluye el hecho de:
obtener del flujo de datos aleatorizados una sucesión de secuencias (44, 45) de bloques (Ci) de datos aleatorizados, y
desaleatorizar cada secuencia (44, 45) de bloques de datos aleatorizados para formar una secuencia asociada (46, 47) de bloques (Pi) de datos desaleatorizados, usando una cifra de descifrado (Dk) en modo de encadenamiento inverso, donde, para descifrar una secuencia (46, 47) de bloques de datos aleatorizados,
un bloque final (P3, PN) en la secuencia (46, 47) de bloques de datos desaleatorizados se obtiene aplicando la cifra de descifrado (Dk) a un bloque final (C3, CN) en la secuencia asociada (44, 45) de bloques de datos aleatorizados y aplicando un operador que tenga como operando al menos el resultado de la cifra de descifrado (Dk) y un vector de inicialización (IV3, IVN), y donde cada bloque que precede el bloque final (P3, PN) en la secuencia (46, 47) de bloques de datos desaleatorizados se obtiene aplicando la cifra de descifrado (Dk) en un bloque en la secuencia de un bloque (44, 45) de datos aleatorizados en una posición correspondiente y aplicando un operador que tiene como operando al menos el resultado de la cifra de descifrado (Dk) y un bloque de datos codificados en una posición sucesiva en la secuencia (44, 45) de bloques de datos aleatorizados,
caracterizado por el hecho de que,
para una sucesión de secuencia (44, 45) de bloques de datos aleatorizados incluida en una unidad (36) de datos en el flujo de datos aleatorizados, al menos un vector de inicialización (IVN) usado para desaleatorizar una secuencia (45) de bloques de datos aleatorizados se genera en función de al menos un bloque de datos desaleatorizados en una secuencia (46) de bloques de datos desaleatorizados obtenidos por desaleatorización de una secuencia precedente (44) de bloques de datos aleatorizados de la unidad (36).
12. Método según la reivindicación 11, donde los respectivos vectores de inicialización (IV3, IVN) para desaleatorizar cada secuencia (44, 45) de bloques (Ci) de datos aleatorizados se generan en función de al menos un bloque de datos desaleatorizados obtenido aplicando la cifra de descifrado (Dk) a un bloque en la secuencia (44, 45) de bloques de datos aleatorizados que precede el bloque final (C3, CN) de datos aleatorizados en la misma secuencia (44, 45) y aplicando un operador que tiene como operando al menos el resultado de la cifra de descifrado y un bloque de datos aleatorizados en una posición siguiente en la misma secuencia (44, 45) de bloques de datos aleatorizados.
13. Método según la reivindicación 11 o 12, donde cada vector de inicialización (IVN) para desaleatorizar una secuencia (45) de bloques de datos aleatorizados en la unidad (36) se genera en función de al menos un bloque de datos desaleatorizados de cada una de cualquiera de las secuencias (46) de bloques de datos desaleatorizados obtenidos por desaleatorización de una secuencia precedente (44) de bloques de datos aleatorizados en la unidad (36).
14. Método según las reivindicaciones 11 a 13, que incluye la recepción de un paquete de datos (34) comprendiendo un membrete (35) y una carga útil (36), donde la unidad es formada por la carga útil.
15. Método según cualquiera de las reivindicaciones 11 a 14, donde la cifra de descifrado (Dk) es una cifra de bloque configurada para funcionar en bloques básicos de tamaño predeterminado, donde los bloques (Ci) en las secuencias (44, 45) de bloques de datos aleatorizados corresponden en tamaño al tamaño del bloque básico.
16. Método según la reivindicación 15, donde, si la unidad (36) se constituye de la sucesión de secuencias de bloques de datos aleatorizados y una cantidad sucesiva de datos del mismo tamaño que un múltiple entero del tamaño del bloque básico y una fracción (CN) del tamaño del bloque básico,
la cantidad de datos se completa con datos predeterminados de tamaño igual a un múltiple del tamaño de bloques básicos para formar una secuencia final de bloques de datos aleatorizados,
una final (PN) de una secuencia final de bloques de datos desaleatorizados se forma aplicando la cifra de descifrado a un bloque que precede inmediatamente el bloque final de la secuencia final de datos aleatorizados, aplicando un operador XOR que tiene como operando el resultado de la cifra de descifrado y el bloque final de la secuencia final de bloques de datos aleatorizados, y eliminando una parte (C') del resultado del operador XOR que corresponde en tamaño a los datos predeterminados,
cada uno de cualquier bloque que precede los dos bloques finales (PN-1, PN) de la secuencia final de bloques de datos desaleatorizados se forma aplicando la cifra de descifrado (Dk) para un bloque en una posición correspondiente en la primera secuencia final de bloques de datos aleatorizados y aplicando un operador XOR que tiene como operando el resultado de la cifra de descifrado y un bloque de datos aleatorizados en una posición siguiente en la secuencia final de bloques de datos aleatorizados, y
un bloque (PN-1) que precede el bloque final (PN) en la secuencia final de bloques de datos desaleatorizados se obtiene aplicando la cifra de descifrado a un bloque (52) formado por concatenación de la parte eliminada (C') que corresponde en tamaño al tamaño de los datos predeterminados y el bloque final de la secuencia final de bloques de datos aleatorizados, y aplicando un operador XOR que tiene como operando el resultado de la cifra de descifrado y un vector de inicialización (IVN) generado en función de al menos un bloque en al menos una de cualquiera de las secuencias de bloques de los datos desaleatorizados obtenidos por desaleatorización de una secuencia precedente de bloques de datos aleatorizados en la unidad (36).
17. Método según la reivindicación 15, donde, si una unidad sucesiva está constituida por cero o más secuencias de un número predeterminado de bloques y por una cantidad sucesiva (CN) de datos del tamaño igual a menos del tamaño de un bloque básico, la cantidad de datos se completa hasta un tamaño igual al tamaño de un bloque básico para formar un bloque final (53),
el bloque final (53) se descodifica utilizando la cifra (Dk) a modo de encadenamiento de bloque, inicializado por un vector de inicialización generado en función de al menos un bloque en al menos una de cualquiera de las secuencias de bloques de los datos desaleatorizados obtenidos por desaleatorización de una secuencia precedente de bloques aleatorizados en la unidad.
18. Método según la reivindicación 17, donde el vector de inicialización se genera aplicando una operación criptográfica (Dk), preferiblemente la cifra de descifrado, en un vector basado en al menos un vector independiente de cualquier bloque en cualquier bloque precedente de datos desaleatorizados obtenibles por desaleatorización de una secuencia precedente de bloques de datos cifrados en la unidad.
19. Sistema para desaleatorizar un flujo de datos aleatorizados para formar un flujo de datos, que incluye:
una entrada para recibir el flujo de datos aleatorizados en forma de sucesión de secuencias (44, 45) de bloques (Ci) de datos aleatorizados, y
una disposición del procesador para desaleatorizar cada secuencia (44, 45) de bloques (Ci) de datos aleatorizados para formar una secuencia asociada (46, 47) de bloques de datos desaleatorizados, usando una cifra de descifrado (DK) en un modo de encadenamiento inverso, donde para desaleatorizar una secuencia (44, 45) de bloques de datos aleatorizados,
se obtiene un bloque final (P3, PN) de datos desaleatorizados en la secuencia (46, 47) aplicando la cifra de descifrado (Dk) a un bloque final (C3, CN) en la secuencia asociada (44, 45) de bloques de datos aleatorizados y aplicando un operador que tiene como operando al menos el resultado de la cifra de descifrado (Dk) y un vector de inicialización (IV3, IVN), y donde cada bloque precedente de datos desaleatorizados en la secuencia (46, 47) se obtiene aplicando la cifra de descifrado a un bloque en la secuencia de bloques de datos aleatorizados en una posición correspondiente y aplicando un operador que tiene como operando al menos el resultado de la cifra de descifrado y un bloque de datos aleatorizados en la posición siguiente en la secuencia (44, 45) de bloques de datos aleatorizados,
caracterizado por el hecho de que,
el sistema se configura, para una sucesión de secuencias (44, 45) de bloques de datos aleatorizados incluidas en una unidad (36) de datos del flujo de datos aleatorizados, para generar al menos un vector de inicialización (IVN) usado para descodificar una secuencia (45) de bloques de datos aleatorizados en función de al menos un bloque de datos desaleatorizados en una secuencia de bloques de datos desaleatorizados obtenidos por desaleatorización de una secuencia precedente (44) de bloques de datos aleatorizados de la unidad (36).
20. Sistema según la reivindicación 19, configurado para realizar un método según cualquiera de las reivindicaciones 11 a 18.
21. Aparato para enviar y recibir datos, incluyendo un dispositivo (14) dispuesto para aplicar un método según cualquiera de las reivindicaciones 1 a 9 y un método según cualquiera de las reivindicaciones 11 a 18.
22. Programa informático comprendiendo un conjunto de instrucciones capaces, cuando se incorporan en una medio legible por máquina, de dirigir un sistema para procesar información para realizar un método según cualquiera de las reivindicaciones 1 a 9 o cualquiera de las reivindicaciones 11 a 18.
Patentes similares o relacionadas:
Procedimiento de puesta en práctica segura de un módulo funcional en un componente electrónico, y componente electrónico correspondiente, del 29 de Julio de 2020, de Thales Dis France SA: Procedimiento de puesta en práctica segura de un módulo funcional, que tiene por función un algoritmo de criptografía, en un componente electrónico, utilizando el […]
Arquitectura e instrucciones flexibles para el estándar de cifrado avanzado (AES), del 27 de Mayo de 2020, de INTEL CORPORATION: Un procesador que comprende: una pluralidad de núcleos; una caché de instrucciones de nivel 1, L1, para almacenar una pluralidad de instrucciones […]
Método y sistema para asegurar un acceso de un cliente a servicios de agente DRM para un reproductor de video, del 29 de Abril de 2020, de Orca Interactive Ltd: Un método para asegurar el acceso del módulo informático de un cliente a los servicios de un agente DRM, comprendiendo dicho método los pasos de: […]
Procedimiento y dispositivo electrónico de gestión de datos, del 1 de Abril de 2020, de SAMSUNG ELECTRONICS CO., LTD.: Un dispositivo electrónico que comprende: una memoria configurada para almacenar al menos una aplicación; un módulo de comunicación configurado […]
Algoritmo criptográfico con etapa de cálculo enmascarada dependiente de clave (llamada de SBOX), del 12 de Febrero de 2020, de Giesecke+Devrient Mobile Security GmbH: Unidad de procesador con una implementación ejecutable implementada en la misma de un algoritmo criptográfico (AES, DES), que está configurado para, […]
Componente lógico programable, circuito de formación de claves y procedimiento para proporcionar una información de seguridad, del 11 de Diciembre de 2019, de Siemens Mobility GmbH: Componente lógico programable, que se configura por un flujo de bits , donde mediante el flujo de bits se configura un circuito de formación de […]
 Sistema y procedimiento para la creación y la gestión de autorizaciones descentralizadas para objetos conectados, del 31 de Octubre de 2019, de Bull SAS: Sistema informático de creación de autorizaciones, de atribuciones y de gestión de dichas autorizaciones para unos objetos conectados que […]
Sistema y procedimiento para la creación y la gestión de autorizaciones descentralizadas para objetos conectados, del 31 de Octubre de 2019, de Bull SAS: Sistema informático de creación de autorizaciones, de atribuciones y de gestión de dichas autorizaciones para unos objetos conectados que […]
Dispositivo y método para criptografía resonante, del 23 de Octubre de 2019, de Global Risk Advisors: Un sistema para comunicaciones seguras usando encriptación de datos, comprendiendo el sistema: una colección de dispositivos (100A, 100B, […]