FLUJO DE DATOS DE VÍDEO CON CALIDAD AJUSTABLE A ESCALA.
Aparato para generar un flujo (36) de datos de vídeo con calidad ajustable a escala,
en el que una secuencia unidimensional de valores de coeficiente de transformada se dispone en una pluralidad de capas de calidad, que comprende: medios (42) para codificar una señal (18) de vídeo usando transformación por bloques para obtener bloques (146, 148) de transformada de valores de coeficiente de transformada dispuestos bidimensionalmente para una imagen (140) de la señal de vídeo, en el que un orden (154, 156, 164, 166) de barrido predeterminado con posibles posiciones de barrido ordena los valores de coeficiente de transformada en dicha secuencia unidimensional de valores de coeficiente de transformada; y medios (44) para formar, para cada una de la pluralidad de capas de calidad, un subflujo (30; 28, 30) de datos de vídeo que contiene información de alcance de barrido que indica un subconjunto de las posibles posiciones de barrido, de tal manera que el subconjunto de cada una de la pluralidad de capas de calidad comprende al menos una posible posición de barrido no incluida en el subconjunto de cualquier otra de la pluralidad de capas de calidad y una de las posibles posiciones de barrido está incluida en más de uno de los subconjuntos de capas de calidad, e información de coeficiente de transformada sobre valores de coeficiente de transformada pertenecientes al subconjunto de posibles posiciones de barrido de la respectiva capa de calidad, que contiene un valor de contribución por cada posible posición de barrido del subconjunto de posibles posiciones de barrido de la respectiva capa de calidad, de tal manera que el valor de coeficiente de transformada de la posible posición de barrido puede derivarse basándose en una suma de los valores de contribución para la posible posición de barrido de los más de un subconjuntos de las capas de calidad
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2007/003411.
Solicitante: FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V..
Nacionalidad solicitante: Alemania.
Dirección: HANSASTRASSE 27C 80686 MUNCHEN ALEMANIA.
Inventor/es: WIEGAND, THOMAS, SCHWARZ, HEIKO, KIRCHHOFFER,Heiner .
Fecha de Publicación: .
Fecha Solicitud PCT: 18 de Abril de 2007.
Clasificación Internacional de Patentes:
- H04N7/26E2
- H04N7/30H
- H04N7/50
Clasificación PCT:
- H04N7/50
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia.
Fragmento de la descripción:
Antecedentes
La presente invención se refiere a flujos de datos de vídeo con calidad ajustable a escala, a su generación y decodificación tal como la generación y decodificación de flujos de datos de vídeo obtenidos 5 mediante el uso de transformación por bloques.
El actual Equipo Conjunto de Vídeo “JVT” del Grupo de Expertos en Codificación de Vídeo de la ITU-T en el Grupo de Expertos en Imágenes en Movimiento (MPEG) de la ISO/IEC está en la actualidad especificando una extensión ajustable a escala de la norma de codificación de vídeo H.264/MPEG4-AVC. La característica clave de la codificación de vídeo ajustable a escala (SVC) en comparación con la 10 codificación convencional de una única capa es que se proporcionan varias representaciones de una fuente de vídeo con diferentes resoluciones, tasas de transmisión de tramas y/o tasas de transmisión de bits dentro de un único flujo de bits. A partir de un flujo de bits de SVC global puede extraerse mediante sencillas manipulaciones del flujo, tales como la eliminación de paquetes, una representación de vídeo con una resolución espaciotemporal y una tasa de transmisión de bits específicas. Como característica 15 importante del diseño SVC, la mayoría de los componentes de H.264/MPG4-AVC se usan tal como se especifican en la norma. Esto incluye la predicción con compensación de movimiento y la intrapredicción, la codificación de transformada y de entropía, el desbloqueo así como la paquetización de unidades NAL (NAL = capa de abstracción de red). La capa base de un flujo de bits de SVC se codifica generalmente de conformidad con la norma H.264-MPEG4-AVC, y por tanto cualquier decodificador que cumpla con la 20 norma H.264-MPEG4-AVC puede decodificar la representación de la capa base cuando se le proporciona un flujo de bits de SVC. Simplemente se añaden nuevas herramientas para soportar la ajustabilidad a escala espacial y de SNR.
Para la ajustabilidad a escala de SNR, se distingue entre ajustabilidad a escala de grano grueso/grano medio (CGS/MGS) y ajustabilidad a escala de grano fino (FGS) en el actual borrador de 25 trabajo. La codificación ajustable a escala de SNR de grano grueso o grano medio se consigue usando conceptos similares a los usados para la ajustabilidad a escala espacial. Las imágenes de diferentes capas de SNR se codifican de manera independiente con parámetros de movimiento específicos de la capa. Sin embargo, con el fin de mejorar la eficacia de la codificación de las capas mejoradas en comparación con la difusión simultánea, se han introducido mecanismos de predicción entre capas 30 adicionales. Estos mecanismos de predicción se han hecho intercambiables de modo que un codificador pueda elegir libremente qué información de capa base debe aprovechar para una codificación de capa de mejora eficaz. Puesto que los conceptos de predicción entre capas incorporados incluyen técnicas para la predicción residual y de parámetros de movimiento, las estructuras de predicción temporal de las capas de SNR deben alinearse temporalmente para un uso eficaz de la predicción entre capas. Ha de indicarse 35 que todas las unidades NAL para un instante de tiempo forman una unidad de rebosamiento y por tanto tienen que sucederse unas tras otras dentro de un flujo de bits de SVC. En el diseño SVC se incluyen las siguientes tres técnicas de predicción entre capas.
La primera se denomina predicción de movimiento entre capas. Con el fin de emplear datos de movimiento de la capa base para la codificación de capas de mejora, se ha introducido un modo de 40 macrobloque adicional en las capas de mejora de SNR. La división del macrobloque se obtiene copiando la división del macrobloque coubicado en la capa base. Los índices de la imagen de referencia así como los vectores de movimiento asociados se copian de los bloques de capa base coubicados. Adicionalmente, un vector de movimiento de la capa base puede usarse como predictor de vector de movimiento para los modos de macrobloque convencionales. 45
La segunda técnica de reducción de redundancia entre las diversas capas de calidad se denomina predicción residual entre capas. El uso de la predicción residual entre capas se señaliza mediante un indicador (flag) (residual_prediction_flag) que se transmite para todos los macrobloques intercodificados. Cuando este indicador es verdadero, la señal de capa base del bloque coubicado se usa como predicción para la señal residual del macrobloque actual, de modo que sólo se codifica la 50 correspondiente señal de diferencia.
Finalmente, la intrapredicción entre capas se usa con el fin de aprovechar la redundancia entre las capas. En este modo de intra-macrobloque, la señal de predicción se construye mediante la señal de reconstrucción coubicada de la capa base. Para la intrapredicción entre capas generalmente se requiere que las capas base estén completamente decodificadas incluyendo las operaciones computacionalmente 55 complejas de predicción con compensación de movimiento y desbloqueo. Sin embargo, se ha mostrado que este problema puede evitarse cuando la intrapredicción entre capas se limita a aquellas partes de la imagen de capa inferior que están intracodificadas. Con esta limitación, cada capa objetivo soportada puede decodificarse con un único bucle con compensación de movimiento. Este modo de decodificación de un solo bucle es obligatorio en la extensión H.264-MPEG4-AVC ajustable a escala.
Puesto que la intrapredicción entre capas sólo puede aplicarse cuando el macrobloque coubicado está intracodificado y la predicción de movimiento entre capas con inferencia del tipo de macrobloque sólo puede aplicarse cuando el macrobloque de capa base está intercodificado, ambos modos se señalizan mediante un único elemento de sintaxis base_mode_flag a nivel de macrobloque. 5 Cuando este indicador es igual a 1, se elige la intrapredicción entre capas cuando el macrobloque de capa base está intracodificado. En caso contrario, el modo de macrobloque así como los índices de referencia y los vectores de movimiento se copian desde el macrobloque de capa base.
Con el fin de soportar una granularidad más fina que la codificación CGS/MGS, se han introducido denominados segmentos de refinamiento progresivo que posibilitan una codificación ajustable 10 a escala de SNR con granularidad más fina (FGS). Cada segmento de refinamiento progresivo representa un refinamiento de la señal residual que corresponde a una bisección del tamaño de paso de cuantificación (incremento de QP de 6). Estas señales están representadas de manera que sólo tienen que realizarse una única transformada inversa para cada bloque de transformada en el lado del decodificador. La ordenación de los niveles de coeficientes de transformada en segmentos de 15 refinamientos progresivos permite truncar las correspondientes unidades NAL en cualquier punto arbitrario en alineación de byte, de modo que la calidad de la capa base de SNR puede refinarse con granularidad fina. Además de un refinamiento de la señal residual, también es posible transmitir un refinamiento de parámetros de movimiento como parte de los segmentos de refinamiento progresivo.
Un inconveniente de la codificación de FGS en el actual borrador de SVC es que aumenta de 20 manera significativa la complejidad del decodificador en comparación con la codificación CGS/MGS. Por un lado, los coeficientes de transformada en un segmento de refinamiento progresivo se codifican usando varios barridos por los bloques de transformada, y en cada barrido sólo se transmiten unos pocos niveles de coeficientes de transformada. Para el decodificador, esto aumento la complejidad ya que se requiere un ancho de banda con más memoria, porque todos los niveles de coeficientes de transformada de 25 diferentes barridos tienen que recopilarse antes de que pueda llevarse a cabo la transformada inversa. Por otro lado, el proceso de análisis sintáctico para segmentos de refinamiento progresivo depende de los elementos de sintaxis de los correspondientes segmentos de capa base. El orden de los elementos de sintaxis así como las tablas de palabras de código para la codificación VLC o la selección del modelo de probabilidad para codificación aritmética dependen de los elementos de sintaxis en la capa base. Esto 30 aumenta adicionalmente el ancho de banda con memoria requerido para la decodificación, ya que hay que acceder a los elementos de sintaxis de la capa base durante el análisis sintáctico de la capa de mejora.
Además, la propiedad especial de los segmentos de refinamiento progresivo de que pueden truncarse es difícil de usar en las redes de conmutación...
Reivindicaciones:
1. Aparato para generar un flujo (36) de datos de vídeo con calidad ajustable a escala, en el que una secuencia unidimensional de valores de coeficiente de transformada se dispone en una pluralidad de capas de calidad, que comprende:
medios (42) para codificar una señal (18) de vídeo usando transformación por bloques 5 para obtener bloques (146, 148) de transformada de valores de coeficiente de transformada dispuestos bidimensionalmente para una imagen (140) de la señal de vídeo, en el que un orden (154, 156, 164, 166) de barrido predeterminado con posibles posiciones de barrido ordena los valores de coeficiente de transformada en dicha secuencia unidimensional de valores de coeficiente de transformada; y 10
medios (44) para formar, para cada una de la pluralidad de capas de calidad, un subflujo (30; 28, 30) de datos de vídeo que contiene información de alcance de barrido que indica un subconjunto de las posibles posiciones de barrido, de tal manera que el subconjunto de cada una de la pluralidad de capas de calidad comprende al menos una posible posición de barrido no incluida en el subconjunto de cualquier otra de la pluralidad de capas de 15 calidad y una de las posibles posiciones de barrido está incluida en más de uno de los subconjuntos de capas de calidad, e información de coeficiente de transformada sobre valores de coeficiente de transformada pertenecientes al subconjunto de posibles posiciones de barrido de la respectiva capa de calidad, que contiene un valor de contribución por cada posible posición de barrido del subconjunto de posibles posiciones 20 de barrido de la respectiva capa de calidad, de tal manera que el valor de coeficiente de transformada de la posible posición de barrido puede derivarse basándose en una suma de los valores de contribución para la posible posición de barrido de los más de un subconjuntos de las capas de calidad.
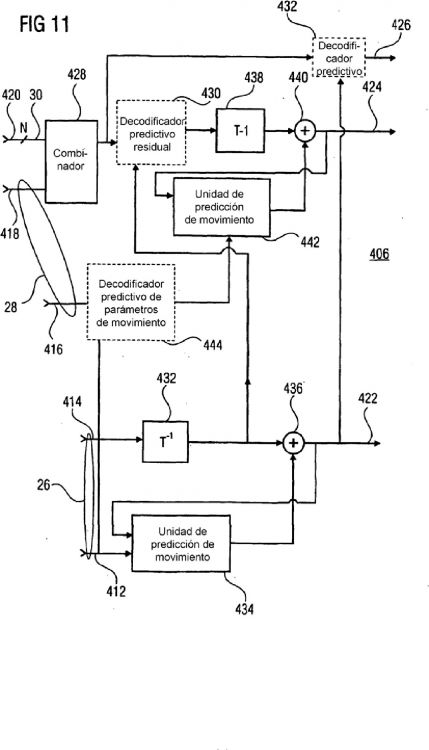
2. Aparato para reconstruir una señal de vídeo a partir de un flujo (36) de datos de vídeo con 25 calidad ajustable a escala, en el que una secuencia unidimensional de valores de coeficiente de transformada se dispone en una pluralidad de capas de calidad, y que comprende, para cada una de la pluralidad de capas de calidad, un subflujo (30; 28, 30) de datos de vídeo, que comprende:
medios (402) para analizar sintácticamente los subflujos de datos de vídeo de la pluralidad 30 de capas de calidad, para obtener, para cada capa de calidad, una información de alcance de barrido e información de coeficiente de transformada sobre valores de coeficiente de transformada dispuestos bidimensionalmente de diferentes bloques de transformada, en el que un orden de barrido predeterminado con posibles posiciones de barrido ordena los valores de coeficiente de transformada en dicha secuencia unidimensional de valores de 35 coeficiente de transformada, y la información de alcance de barrido indica un subconjunto de las posibles posiciones de barrido;
medios (428) para, usando la información de alcance de barrido, para cada capa de calidad, construir los bloques de transformada asociando los valores de coeficiente de transformada de los respectivos bloques de transformada a partir de la información de 40 coeficiente de transformada al subconjunto de posibles posiciones de barrido; y
medios (438) para reconstruir una imagen de la señal de vídeo mediante una transformación hacia atrás de los bloques de transformada, en el que los medios para analizar sintácticamente están configurados de tal manera que la información de coeficiente de transformada de más de una de las capas de calidad contiene un valor de 45 contribución relativo a un valor de coeficiente de transformada, y en el que los medios de construcción están configurados para derivar el valor para el valor de coeficiente de transformada basándose en una suma de los valores de contribución relativos al valor de coeficiente de transformada.
3. Aparato según la reivindicación 2, en el que los medios (428) de construcción están configurados 50 para usar la información de alcance de barrido como si indicara una primera posición de barrido de entre las posibles posiciones de barrido dentro del subconjunto de posibles posiciones de barrido en el orden de barrido predeterminado.
4. Aparato según las reivindicaciones 2 ó 3, en el que los medios (428) de construcción están configurados para usar la información de alcance de barrido como si indicara una última posición 55 de barrido de entre las posibles posiciones de barrido dentro del subconjunto de posibles posiciones de barrido en el orden de barrido predeterminado.
5. Aparato según cualquiera de las reivindicaciones 2 a 4, en el que los medios de reconstrucción están configurados para reconstruir la señal de vídeo usando predicción con compensación de movimiento basándose en información de movimiento y combinando un resultado de predicción con compensación de movimiento con un residuo de predicción con compensación de movimiento, obteniéndose el residuo de predicción con compensación de movimiento mediante 5 una transformación inversa por bloques de los bloques de transformada de valores de coeficiente de transformada.
6. Aparato según la reivindicación 5, en el que los medios (402) para analizar sintácticamente están configurados para esperar que cada subflujo de datos contenga una indicación que indica la existencia de información de movimiento o la no existencia de información de movimiento para la 10 respectiva capa de calidad y que el subflujo de datos de una primera capa de las capas de calidad contenga la información de movimiento y tenga la indicación que indica la existencia de información de movimiento, o la indicación dentro del subflujo de datos de la primera capa de calidad indica la no existencia de información de movimiento, comprendiendo una parte del flujo de datos de vídeo con calidad ajustable a escala diferente de los subflujos de datos la 15 información de movimiento, y para esperar que el (los) subflujo(s) de datos de la(s) otra(s) capa(s) de calidad tenga(n) la indicación que indica la no existencia de información de movimiento.
7. Aparato según la reivindicación 6, en el que los medios para analizar sintácticamente están configurados para esperar que el subflujo de datos de la primera capa de calidad tenga la 20 indicación que indica la existencia de información de movimiento, siendo la información de movimiento igual a la información de movimiento de calidad más alta o igual a una información de refinamiento que permite una reconstrucción de la información de movimiento de calidad más alta basándose en la información de movimiento de calidad más baja, y que la parte del flujo de datos de vídeo con calidad ajustable a escala también contenga la información de movimiento de 25 calidad más baja.
8. Aparato según las reivindicaciones 6 ó 7, en el que los medios para analizar sintácticamente están configurados de tal manera que la información de movimiento y la indicación se refieren a un macrobloque de la imagen.
9. Aparato según cualquiera de las reivindicaciones 2 a 8, en el que los medios para analizar 30 sintácticamente están configurados para analizar sintácticamente cada subflujo de datos individualmente de manera independiente, con respeto a un resultado del análisis sintáctico, del (de los) otro(s) subflujo(s) de datos.
10. Aparato según la reivindicación 9, en el que los medios de construcción están configurados para asociar la respectiva información de coeficiente de transformada con los valores de coeficiente 35 de transformada, siendo el resultado de la asociación independiente del (de los) otro(s) subflujo(s) de datos.
11. Aparato según la reivindicación 10, en el que se define un orden de capas entre las capas de calidad, y el subflujo de datos de una primera capa de calidad en el orden de capas permite una asociación de la respectiva información de coeficiente de transformada con los valores de 40 coeficiente de transformada independiente del (de los) subflujo(s) de datos de la(s) siguiente(s) capa(s) de calidad, mientras que el (los) subflujo(s) de datos de las siguientes capas de calidad en el orden de capas permite(n) una asociación de la respectiva información de coeficiente de transformada con los valores de coeficiente de transformada meramente en combinación con el (los) subflujo(s) de datos de (una) capa(s) de calidad que precede(n) a la respectiva capa de 45 calidad, en el que los medios de construcción están configurados para asociar la información de coeficiente de transformada de una respectiva capa de calidad con los valores de coeficiente de transformada usando los subflujos de datos de la respectiva capa de calidad y la(s) capa(s) de calidad que precede(n) a la respectiva capa de calidad.
12. Método para generar un flujo (36) de datos de vídeo con calidad ajustable a escala, en el que 50 una secuencia unidimensional de valores de coeficiente de transformada se dispone en una pluralidad de capas de calidad, que comprende:
codificar una señal (18) de vídeo usando transformación por bloques para obtener bloques (146, 148) de transformada de valores de coeficiente de transformada dispuestos bidimensionalmente para una imagen (140) de la señal de vídeo, en el que un orden (154, 55 156, 164, 166) de barrido predeterminado con posibles posiciones de barrido ordena los valores de coeficiente de transformada en dicha secuencia unidimensional de valores de coeficiente de transformada; y
formar, para cada una de la pluralidad de capas de calidad, un subflujo (30; 28, 30) de datos de vídeo que contiene información de alcance de barrido que indica un subconjunto de las posibles posiciones de barrido, de tal manera que el subconjunto de cada una de la pluralidad de capas de calidad comprende al menos una posible posición de barrido no incluida en el subconjunto de cualquier otra de la pluralidad de capas de calidad y una de 5 las posibles posiciones de barrido está incluida en más de uno de los subconjuntos de las capas de calidad, e información de coeficiente de transformada sobre valores de coeficiente de transformada pertenecientes al subconjunto de posibles posiciones de barrido de la respectiva capa de calidad, que contiene un valor de contribución por cada posible posición de barrido del subconjunto de posibles posiciones de barrido de la 10 respectiva capa de calidad de tal manera que el valor de coeficiente de transformada de la posible posición de barrido puede derivarse basándose en una suma de los valores de contribución para la posible posición de barrido de los más de un subconjuntos de las capas de calidad.
13. Método para reconstruir una señal de vídeo a partir de un flujo (36) de datos de vídeo con 15 calidad ajustable a escala, en el que una secuencia unidimensional de valores de coeficiente de transformada se dispone en una pluralidad de capas de calidad, y que comprende, para cada una de la pluralidad de capas de calidad, un subflujo (30; 28, 30) de datos de vídeo, que comprende:
analizar sintácticamente los subflujos de datos de vídeo de la pluralidad de capas de 20 calidad, para obtener, para cada capa de calidad, una información de alcance de barrido e información de coeficiente de transformada sobre valores de coeficiente de transformada dispuestos bidimensionalmente de diferentes bloques de transformada, en el que un orden de barrido predeterminado con posibles posiciones de barrido ordena los valores de coeficiente de transformada en dicha secuencia unidimensional de valores de coeficiente 25 de transformada, y la información de alcance de barrido indica un subconjunto de las posibles posiciones de barrido;
usando la información de alcance de barrido, para cada capa de calidad, construir los bloques de transformada asociando los valores de coeficiente de transformada de los respectivos bloques de transformada a partir de la información de coeficiente de 30 transformada al subconjunto de posibles posiciones de barrido; y
reconstruir una imagen de la señal de vídeo mediante una transformación hacia atrás de los bloques de transformada, en el que el análisis sintáctico de los subflujos de datos de vídeo se realiza de tal manera que la información de coeficiente de transformada de más de una de las capas de calidad contiene un valor de contribución relativo a un valor de 35 coeficiente de transformada, y la construcción de los bloques de transformada comprende derivar el valor para el valor de coeficiente de transformada basándose en una suma de los valores de contribución relativos al valor de coeficiente de transformada.
14. Flujo de datos de vídeo con calidad ajustable a escala en el que una secuencia unidimensional de valores de coeficiente de transformada se dispone en una pluralidad de capas de calidad, y 40 que permite una reconstrucción de una señal de vídeo que comprende, para cada una de la pluralidad de capas de calidad, una información de alcance de barrido e información de coeficiente de transformada sobre valores de coeficiente de transformada dispuestos bidimensionalmente de diferentes bloques de transformada, en el que un orden de barrido predeterminado con posibles posiciones de barrido ordena los valores de coeficiente de 45 transformada en dicha secuencia unidimensional de valores de coeficiente de transformada, y la información de alcance de barrido indica un subconjunto de las posibles posiciones de barrido, de tal manera que el subconjunto de cada una de la pluralidad de capas de calidad comprende al menos una posible posición de barrido no incluida en el subconjunto de cualquier otra de la pluralidad de capas de calidad, en el que la información de coeficiente de transformada se refiere 50 a valores de coeficiente de transformada pertenecientes al subconjunto de posibles posiciones de barrido, en el que la información de coeficiente de transformada de más de una de las capas de calidad contiene un valor de contribución relativo a un valor de coeficiente de transformada, y el valor de coeficiente de transformada de la posible posición de barrido puede derivarse basándose en una suma de los valores de contribución para la posible posición de barrido de los 55 más de un subconjuntos de las capas de calidad.
15. Programa informático que tiene un código de programa para realizar, cuando se ejecuta en un ordenador, un método según la reivindicación 12 ó 13.
Patentes similares o relacionadas:
 Filtro de desbloqueo condicionado por el brillo de los píxeles, del 25 de Marzo de 2020, de DOLBY INTERNATIONAL AB: Método para desbloquear datos de píxeles procesados con compresión de vídeo digital basado en bloque, incluyendo los pasos:
- recibir […]
Filtro de desbloqueo condicionado por el brillo de los píxeles, del 25 de Marzo de 2020, de DOLBY INTERNATIONAL AB: Método para desbloquear datos de píxeles procesados con compresión de vídeo digital basado en bloque, incluyendo los pasos:
- recibir […]
Método para codificar y descodificar imágenes B en modo directo, del 19 de Febrero de 2020, de Godo Kaisha IP Bridge 1: Un método para generar y descodificar una secuencia de bits de una imagen B objetivo, en donde generar la secuencia de bits de la imagen B objetivo incluye las siguientes […]
Interpolación mejorada de cuadros de compresión de vídeo, del 4 de Diciembre de 2019, de DOLBY LABORATORIES LICENSING CORPORATION: Un método para compresión de imágenes de video usando predicción en modo directo, que incluye: proporcionar una secuencia de cuadros predichos […]
Interpolación mejorada de cuadros de compresión de vídeo, del 4 de Diciembre de 2019, de DOLBY LABORATORIES LICENSING CORPORATION: Un método de compresión de imágenes de video que comprende: proporcionar una secuencia de cuadros referenciables (I, P) y predichos bidireccionales […]
Capa de sectores en códec de vídeo, del 27 de Noviembre de 2019, de Microsoft Technology Licensing, LLC: Un procedimiento de decodificación de vídeo e imágenes, que comprende: decodificar una imagen de un flujo de bits codificado que tiene una jerarquía […]
Transformación solapada condicional, del 20 de Noviembre de 2019, de Microsoft Technology Licensing, LLC: Un método para codificar un flujo de bits de vídeo utilizando una transformación solapada condicional, en donde el método comprende: la señalización de un modo de filtro […]
Procedimiento de codificación de longitud variable y procedimiento de decodificación de longitud variable, del 14 de Agosto de 2019, de Godo Kaisha IP Bridge 1: Un método de codificación para codificar un coeficiente de un componente de frecuencia incluido en un bloque objetivo a codificar, comprendiendo el método de codificación: […]
Método de cálculo de vectores de movimiento, del 12 de Junio de 2019, de Panasonic Intellectual Property Corporation of America: Un método de codificación de imágenes para codificar un bloque actual incluido en una imagen actual en modo directo, comprendiendo el método de codificación de imágenes: […]