DETECCION Y MEDIDA EN TIEMPO REAL DE FLUJOS DE ELEMENTOS FRECUENTES EN GRANDES POBLACIONES, ESCALABLE Y SINTONIZABLE.
Detección y medida en tiempo real de flujos de elementos frecuentes en grandes poblaciones,
escalable y sintonizable.Un "método" para la detección y medida de elementos frecuentes (que aparecen más veces que un determinado umbral en una población de elementos potencialmente muy grande, como pueden ser "registros" en una base de datos, o "paquetes" en redes de conmutación de paquetes. El método combina muestreo y el uso de funciones resumen (hash). Permite la detección de elementos frecuentes con alta probabilidad, en tiempo real, con tiempo de proceso reducido y determinista y con bajos requerimientos de memoria. En particular, requiere un número de contadores inferior e independiente al número de elementos distintos presentes en la población. Estas características permiten su aplicación en entornos de bases de datos y en redes de alta velocidad donde es interesante detectar y medir grandes flujos de tráfico en tiempo real
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P200700260.
Solicitante: UNIVERSITAT POLITECNICA DE CATALUNYA.
Nacionalidad solicitante: España.
Provincia: BARCELONA.
Inventor/es: YUFERA GOMEZ,JOSE MANUEL.
Fecha de Solicitud: 25 de Enero de 2007.
Fecha de Publicación: .
Fecha de Concesión: 30 de Marzo de 2011.
Clasificación PCT:
- H04L12/26 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04L TRANSMISION DE INFORMACION DIGITAL, p. ej. COMUNICACION TELEGRAFICA (disposiciones comunes a las comunicaciones telegráficas y telefónicas H04M). › H04L 12/00 Redes de datos de conmutación (interconexión o transferencia de información o de otras señales entre memorias, dispositivos de entrada/salida o unidades de tratamiento G06F 13/00). › Disposiciones de vigilancia; Disposiciones de ensayo.
PDF original: ES-2341742_B1.pdf
Fragmento de la descripción:
Detección y medida en tiempo real de flujos de elementos frecuentes en grandes poblaciones, escalable y sintonizable.
Sector de la técnica
De manera general, esta invención se encuadra en el ámbito del análisis de grandes volúmenes de datos. Por ejemplo, en el contexto de bases de datos, donde suele interesar identificar aquellos elementos (registros) que aparecen con más frecuencia que un determinado umbral, ya sea en términos absolutos (p.e. que aparecen más de T veces) o que una cierta fracción del total (p.e. que constituyen más de un porcentaje z del total).
Se encuadra también en el contexto de redes de datos de alta velocidad, donde suele ser conveniente, para su gestión y monitorización, la medida del tráfico "por flujos". El descubrimiento de dichos flujos, así como su medida es útil para aplicaciones como balanceo de carga, ingeniería de tráfico o tarificación. Sin embargo, la medida de todos los flujos presentes en un enlace es hoy en día costosa debido al potencialmente elevado número de flujos. Por este motivo suele interesar detectar o descubrir aquellos flujos (entendidos como grupos de paquetes con alguna característica en común) cuyo tamaño exceda un determinado umbral.
De manera general, la presente invención es aplicable en cualquier ámbito donde, de una población elevada de elementos, pueda interesar descubrir y medir/contar aquellos elementos que aparecen más veces que un determinado umbral.
Estado de la técnica
La medida del tráfico "por flujos" proporciona un compromiso razonable entre la cantidad de datos a adquirir/analizar/almacenar y el nivel de información obtenido. Se entiende por flujo un conjunto de elementos, en este caso paquetes, con alguna característica en común. La medida por flujos consiste en identificar y medir dichos conjuntos o flujos, reportando las características que los identifican y su tamaño. Qué características deben tener en común los paquetes para ser considerados del mismo flujo es lo que se denomina "definición de flujo" y es totalmente flexible. Por ejemplo, puede definirse un flujo como todos los paquetes que utilizan el mismo protocolo de transporte y van destinados a la misma dirección (p.e. dirección IP).
Dada una definición de flujo, cada flujo queda identificado por los valores que en éste toman las propiedades especificadas en la definición. Por ejemplo, para la definición de flujo anterior, todos los paquetes destinados a la dirección IP 192.1.4.5 que utilizan el protocolo TCP, formarían un flujo cuyo identificador de flujo (FID) seria el (192.1.4.5, TCP).
Para identificar y medir los distintos flujos existentes en un enlace (en un intervalo de tiempo determinado), la solución directa del problema consiste en examinar cada uno de los paquetes, descubrir a qué flujo pertenecen (su identificador) y contar la cantidad de bytes de cada flujo como la suma de los tamaños de los paquetes observados. Esta solución requiere mantener tantos contadores como flujos haya.
En redes de alta velocidad, esta solución es poco escalable, compleja y cara por los siguientes motivos:
Una solución comercial ampliamente utilizada, Sampled NetFlow, se basa en el uso de muestreo para paliar algunos de los problemas antes mencionados. Sin embargo, este método presenta problemas relacionados con el compromiso entre precisión y cantidad de memoria necesaria: a mayor frecuencia de muestreo mejor precisión pero más cantidad de memoria necesaria para almacenar los datos obtenidos. Además, en muchos casos debe sobredimensionarse dicha cantidad de memoria dada la incertidumbre en el número de flujos que pueden estar ocupando el enlace y/o ser capturados. Finalmente, en Sampled NetFlow puede ocurrir que, si no se sobredimensiona de manera adecuada, se detecten muchos flujos pequeños pero no alguno de los grandes, que en algunos casos pueden resultar los más interesantes de capturar.
Una alternativa propuesta pasa por medir sólo flujos grandes, lo que resulta útil en muchas aplicaciones como, por ejemplo, en ingeniería de tráfico, tarificación, etc. Esta alternativa facilita la escalabilidad de la solución, ya que el número de grandes flujos está por definición, acotado: por ejemplo, no puede haber más de 100 flujos con tamaño superior al 1% del volumen total. Este nuevo enfoque está justificado por diversos estudios que demuestran que el tráfico en Internet está típicamente compuesto de muchos flujos pequeños y pocos grandes.
En esta dirección se enmarcan los trabajos y métodos conocidos como Sample-and-Hold (S&H) y Multistage Filters (MF) (ver C. Están and G. Varghese, New directions in traffic measurement and accounting, Proc. of the 2001 ACM SIGCOMM Internet Measurement Workshop, 2001). Si bien el S&H es un método simple, no es selectivo, es decir, garantiza la detección de flujos grandes a costa de detectar muchos pequeños. Además, necesita realizar consultas en memoria para cada paquete, con lo cual sólo resulta viable su implementación, en entornos de elevada velocidad, mediante el uso de memorias asociativas (CAMs) que son caras y de consumo elevado.
Por otra parte, MF es más selectivo que S&H (detectando siempre los flujos grandes y evitando la detección de los pequeños) gracias al uso de varios vectores de contadores. Sin embargo, requiere, como S&H, analizar y realizar una consulta para cada paquete, así como el cómputo de varias funciones resumen (ver The art of computer programming, volumen 3, Sorting and searching, pp.506-542, Donald E. Knuth, Addison Wesley Ed.) y la actualización de contadores también para cada paquete, en el peor de los casos. Por este motivo, a altas velocidades, sólo es posible implementar dichos vectores de contadores en memorias estáticas (SRAMs).
Más recientemente se han propuesto otras soluciones: Sticky Sampling y Lossy Counting (ver G. Manku and R. Motwani, Approximate frequency counts over data streams, Proc. of VLDB, 2002). Si bien estos métodos son aplicables en el contexto de bases de datos, donde encontrar elementos frecuentes resulta útil en el análisis de grandes volúmenes de información, su aplicación en el contexto de medidas de tráfico a altas velocidades presenta serios inconvenientes. Esto se debe a que, para su funcionamiento, deben examinar periódicamente toda la colección de flujos detectados, lo que supone accesos a memoria y un tiempo de proceso dependiente del número de flujos detectados. Esto los hace no escalables en tiempo si, además, el número de flujos detectados depende de las características del tráfico. Finalmente, como los otros... [Seguir leyendo]
Reivindicaciones:
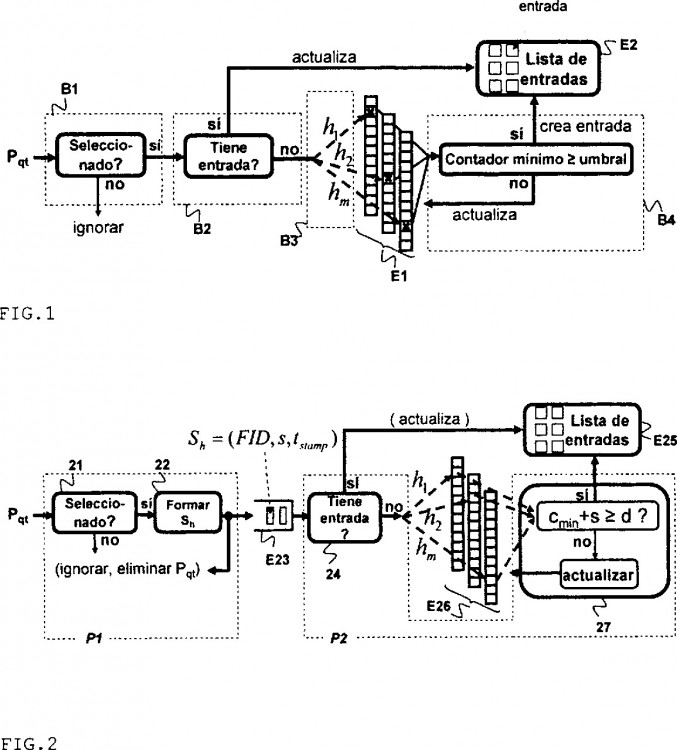
1. Un método para detectar y medir flujos de elementos frecuentes en grandes poblaciones de elementos (donde por flujo se entiende una colección de elementos que tienen ciertas características en común) que comprende las cuatro etapas siguientes:
(a) muestrear elementos mediante un bloque (B1) de muestreo que: 1) selecciona cada uno de los elementos de la población a estudiar con una probabilidad p; y 2) no procesa los elementos no seleccionados;
(b) almacenar en un buffer información sobre los elementos muestreados. Dicha información (Sh) está compuesta por el identificador del flujo (FID) al que pertenecen los elementos, el número de muestras tomadas y una marca temporal de tiempo de llegada de la información (tstamp);
(c) leer la información del buffer mediante un bloque (B2), que extrae los Sh del buffer y comprueba si existe, en la lista de entradas (E2), alguna cuyo identificador FID coincida con aquél contenido en el Sh que se ha extraído. Cada elemento de la lista de entradas (E2) contiene el identificador de un flujo (FID), un contador y dos marcas temporales (una indicando el tiempo de generación de entrada para el flujo, y otra el último instante de su actualización);
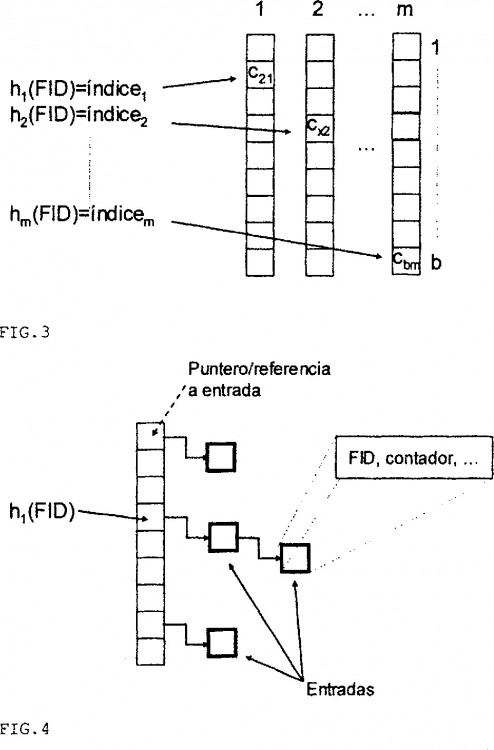
(d) procesar la información del buffer mediante un bloque (E1) compuesto por m vectores de b contadores cada uno (m*b posiciones que denominamos cxy, donde x indica un vector e y un contador de dicho vector). Esta etapa se caracteriza por:
- en el caso de que exista una entrada (en la etapa (c)) con idéntico identificador al indicado en el Sh, actualizar dicha entrada (incrementando su contador y guardando la segunda marca temporal, a parir de la información contenida en el Sh).
- si no existe ninguna entrada en la etapa (c) con identificador igual al del Sh:
1) aplicar m funciones resumen al FID indicado en el Sh (bloque B3), y utilizar los m valores o números resultantes (h1 (FID), ... hm (FID), comprendidos entre 1 y b) para seleccionar un contador en cada uno de los m vectores del siguiente modo: el valor 1
2) calcular el mínimo de los contadores seleccionados por dichos índices, cmin (bloque B4).
3) si la suma de cmin y el valor numérico contenido en el Sh es igual o superior a un umbral d, crear una entrada en la lista de entradas con FID igual al del Sh (etapa (c)). De lo contrario, actualizar los contadores seleccionados en función del valor de cmin y del valor numérico contenido en el Sh.
2. Un método según la reivindicación 1 caracterizado porque la probabilidad mencionada en la etapa (a) se calcula como el cociente entre un umbral de muestras d y un umbral de t amaño de flujo Vc (es decir p=d/Vc) donde Vc es inferior o igual al volumen a partir del cual un flujo se considera como grande.
3. Un método según la reivindicación 1 caracterizado porque, si elementos del mismo flujo (con el mismo FID) llegan agrupados a la etapa (a):
a) puede determinar qué elementos del grupo serán seleccionados en lugar de procesar cada uno de ellos por separado.
b) puede procesar los elementos seleccionados como uno único, almacenando su FID, el número de elementos seleccionados y el tstamp en un único elemento de síntesis Sh.
c) y porque no requiere almacenar los elementos muestreados una vez que el elemento de síntesis Sh ha sido creado.
4. Un método según la reivindicación 1 caracterizado porque, en la etapa (b), la información de los elementos muestreados y que es sintetizada en un Sh puede almacenarse en un buffer o bien ser descartada, en el caso en que dicho buffer esté lleno.
Patentes similares o relacionadas:
Método y aparato para configurar un identificador de dispositivo móvil, del 22 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un método implementado por servidor para configurar un identificador de dispositivo móvil, que comprende: obtener una lista de aplicaciones, APP, […]
SISTEMA PARA CONTROL DE EQUIPOS DE UN RESTAURANTE O TIENDA DE CONVENIENCIA, del 16 de Julio de 2020, de PEREZ GONZALEZ, Daniel: Sistema para control de equipos de un restaurante o tienda de conveniencia , que comprende: -unos sensores (50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 63, […]
Método y sistema para medición de latencia en sistemas de comunicación, del 8 de Julio de 2020, de ASSIA SPE, LLC: Un método que comprende: determinar , por un primer dispositivo de comunicación, un estado de gestión de potencia de un segundo dispositivo de comunicación, […]
Procedimiento y sistema para diagnosticar averías de transmisión en una red según el estándar opc ua, del 24 de Junio de 2020, de SIEMENS AKTIENGESELLSCHAFT: Procedimiento para diagnosticar averías en la transmisión en una red de datos (NET), incluyendo la red de datos al menos una primera clase de elementos […]
Gestión de software intrusivo, del 17 de Junio de 2020, de Google LLC: Un método, que comprende: dividir páginas de destino asociadas a anuncios en páginas de destino de entrenamiento y probar las páginas de […]
Dispositivo de interfaz, procedimiento y programa informático para controlar dispositivos sensores, del 10 de Junio de 2020, de Ubiquiti Inc: Un primer dispositivo de interfaz para su uso en un sistema de domótica , comprendiendo el primer dispositivo de interfaz: un módulo de comunicación […]
Protocolos de control de sistema de chasis virtual, del 3 de Junio de 2020, de ALCATEL LUCENT: Un nodo de red (110a-110f) adaptado para ser parte de un sistema de chasis virtual que tiene una pluralidad de nodos de red dispuestos de modo que la pluralidad de […]
Acceso de red híbrido inteligente, del 27 de Mayo de 2020, de DEUTSCHE TELEKOM AG: Procedimiento para la organización de una conexión de comunicaciones entre un equipo terminal de acceso "CPE" 1 del lado del cliente y un punto […]