Aparato y procedimiento para generar una señal de ambiente a partir de una señal de audio, aparato y procedimiento para obtener una señal de audio multi-canal a partir de una señal de audio, y programa de ordenador.
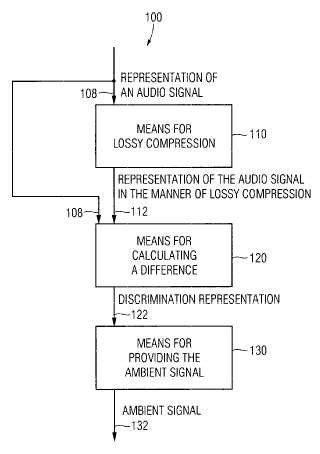
Aparato (100; 200; 300; 510) para generar una señal de ambiente (132;
252, 254; 342; 512) a partir de una señal de audio (108; 208; 308; 508), que comprende: medios (110; 220; 320) para una compresión con pérdidas de una representación espectral (108; 212; 316) de la señal de audio para obtener una representación comprimida (112; 222; 322) de la señal de audio;
medios (122; 230; 330) para calcular una diferencia entre la representación comprimida (112; 222; 322) de la señal de audio y la representación espectral (108; 212; 316) de la señal de audio para obtener una representación de discriminación (122; 232; 332); y medios (130, 240, 340) para proporcionar la señal de ambiente (132; 252, 254; 342) empleando la representación de discriminación;
en el que los medios (110; 220; 320) para la compresión con pérdidas están configurados para comprimir una representación espectral (108; 212; 316), que describe un espectrograma de la señal de audio (108; 208; 308; 508) para obtener como representación comprimida (112; 222; 322) una representación espectral comprimida de la señal de audio.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2007/009197.
Solicitante: FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V..
Nacionalidad solicitante: Alemania.
Dirección: HANSASTRASSE 27C 80686 MUNCHEN ALEMANIA.
Inventor/es: HERRE, JURGEN, UHLE, CHRISTIAN, HELLMUTH, OLIVER, WALTHER, ANDREAS, JANSSEN,CHRISTIAAN.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L19/00 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H).
- G10L19/02 G10L […] › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › utilizando análisis espectrales, p. ej. codificadores vocales de transformación o codificadores vocales subbanda.
- H04S5/00 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04S SISTEMAS ESTEREOFONICOS. › Sistemas seudoestereofónicos, p. ej. en los que las señales de un canal suplementario son derivadas de la señal monofásica por desfase, retardo o reverberación.
- H04S7/00 H04S […] › Disposiciones para la indicación; Disposiciones para el control, p. ej. para el control de la compensación.
PDF original: ES-2391308_T3.pdf
Fragmento de la descripción:
Aparato y procedimiento para generar una seral de ambiente a partir de una seral de audio, aparato y procedimiento para obtener una seral de audio multi-canal a partir de una seral de audio, y programa de ordenador
La presente invencion se refiere en general a un aparato y a un procedimiento para generar una seral de ambiente a partir de una seral de audio, a un aparato y un procedimiento para obtener una seral de audio multi-canal a partir de una seral de audio, y a un programa de ordenador. Concretamente, la presente invencion se refiere a un procedimiento y concepto para calcular una seral de ambiente a partir de una seral de audio para el upmixing de serales mono de audio para reproduccion en sistemas multi-canal.
A continuacion, se discutira la motivacion subyacente a la presente invencion. En la actualidad, el material de audio multi-canal tambien esta experimentando una creciente popularidad en entornos domesticos. La razon principal de esto es que las peliculas sobre medios de DVD ofrecen a menudo sonido multi-canal 5, 1. Por esta razon, incl uso los usuarios domesticos instalan frecuentemente sistemas de reproduccion de audio capaces de reproducir serales de audio multicanal.
Una configuracion correspondiente puede consistir, por ejemplo, en tres a ltavoces (a m odo de ejemplo designados con L, C y R) dispuestos en la parte delantera, dos altavoces (designados con L3 y Rs) dispuestos detras o hacia atras de un oyente y un canal de efectos de baja frecuencia (tambien referido como LFE) . Los tres altavoces dispuestos en la parte delantera (L, C, R) seran en lo sucesivo tambien llamados altavoces frontales. Los altavoces dispuestos detras y en la parte posterior del oyente (Ls, Rs) son en lo sucesivo tambien llamados altavoces posteriores.
Ademas, es de seralar que, por razones de conveniencia, los detalles y las explicaciones siguientes se refieren a los sistemas 5, 1. Los siguientes detalles pueden, por supuesto, tambien ser aplicados a otros siste mas de canales multiples, con solo realizar pequeras modificaciones.
Los sistemas de canales multiples (por ejemplo, un sistema de audio de canales multiples 5.1) proporcionan varias ventajas conocidas sobre la reproduccion estereo de dos canales. Esto se ejemplifica por las siguientes ventajas:
- Ventaja 1: estabilidad mejorada frente a la imagen, incluso de o fuera de la posicion de escucha optima (central) . El "punto dulce" se amplia mediante el canal central. El termino "punto dulce" se refiere a una superficie de posiciones de escucha donde se puede presentar una impresion de sonido optima percibida (por un oyente) .
- Ventaja 2: Establecer una mejor aproximacion de una impresion o experiencia a una sala de conciertos. La mayor experiencia de la "envoltura" y amplitud se obtiene a traves de los altavoces de canal posteriores o los altavoces de canal posteriores.
Sin embargo, todavia hay una gran cantidad de contenidos de audio legados que consta de solo dos ("estereo") canales de audio, tal como en los discos compactos. Incluso se venden grabaciones muy viejas y viejas peliculas y series de television en CDs y/ o DVDs que estan disponibles en calidad mono y/ o por medio de solamente una seral de audio "mono" de un solo canal.
Por lo tanto, hay opciones para la reproduccion de material legado de audio mono a traves de una configuracion multicanal 5.1:
- Opcion 1: Reproduccion o playback del canal mono a traves del centro o por el altavoz central de tal manera que se obtenga una fuente mono verdadera.
- Opcion 2: Reproduccion o playback de la seral mono por los a ltavoces L y R (es decir, por e l altavoz delantero izquierdo y el altavoz delantero derecho) . Este enfoque produce una fuente mono fantasma que tiene una anchura de fuente percibida mas amplia que una fuente de mono verdadera, pero con una tendencia hacia el altavoz mas cercano al oyente cuando el oyente no se sienta en o en el punto dulce.
Este procedimiento tambien puede ser usado si solo hay disponible un sistema de reproduccion de dos canales, y que no hace uso de la configuracion de altavoces ampliada (tales como una configuracion de altavoz con 5 o 6 altavoces) . El altavoz C o al tavoz central, el altavoz L3 o altavoz trasero izquierdo, el altavoz Rs o altavoz trasero derecho y el altavoz LFE o altavoz de canal de efectos de baja frecuencia permanecen sin utilizar.
- Opcion 3: P uede emplearse un procedimiento para convertir el canal de la seral mono en una seral multicanal utilizando todos los altavoces 5.1 (es decir, todos los seis altavoces utilizados en un sistema de canales multiples 5.1) . De esta manera, la seral multi-canal se beneficia de las ventajas previamente discutidas de la configuracion de varios canales. El procedimiento se puede emplear en tiempo real o "sobre la marcha" o por medio de preprocesamiento y se conoce como proceso de upmix o "upmixing".
En lo que respecta a la calidad del audio o la calidad del sonido, la opcion 3 ofrece ventajas sobre la opcion 1 y la opcion 2. Sin embargo, particularmente con respecto a la seral generada para la alimentacion de los altavoces posteriores, el procesamiento de la seral requerida no es obvia.
[0010] En la literatura, se describen dos conceptos diferentes para un procedimiento upmix o proceso de upmix. Estos conceptos son el " Concepto Directo / Ambiente " y el " Concepto en la banda". Los dos conceptos indicados se describen a continuacion.
Concepto Directo / Ambiente
Las "fuentes de sonido directo " se reproducen a traves de los tres canales frontales de forma que son percibidos en la misma posicion que en la original version de dos canales. El termino "fuente de sonido directo" se utiliza aqui para describir el sonido que viene, unica ydirectamente de una fuente de sonido discreto (por ejemplo, un instrumento) , y que muestra sonido adicional escaso o nulo, por ejemplo, debido a las reflexiones de las paredes.
En este escenario, el sonido o el ruido alimentado a los altavoces posteriores debe consistir unicamente en ruido
o sonido similar al ambiente (que puede o no puede estar presente en la grabacion original) . El sonido o ruido similar al ambiente no esta asociado a una sola fuente de sonido o fuente de ruido, pero contribuye a la reproduccion o playback del entorno acustico (acustica de la sala) de una grabacion o a la asi llamada "sensacion de envolvente" del oyente. El sonido similar al ambiente o ruido similar al ambiente es ruido o sonido adicional por parte del publico en las actuaciones en directo (como aplausos) o el sonido ambiental o ruido ambiental aradido con intencion artistica (como el ruido de la grabacion, canto de los pajaros, los sonidos de grillos chirriando) .
A modo de ilustracion, la figura 7 representa la version original de dos canales (de una grabacion de audio) . La figura 8 muestra una interpretacion upmixed utilizando el concepto Directo / Ambiente.
Concepto en la banda
Siguiendo el concepto circundante, a menudo referido como "concepto en-la-banda", cada sonido o ruido (sonido directo, asi como el ruido ambiental) puede ser completamente y/ o arbitrariamente posicionado alrededor del oyente. La posicion del ruido o sonido es independiente de sus propiedades (sonido directo o ruido directo o sonido ambiental o ruido ambiental) y depende solamente del disero especifico del algoritmo y sus ajustes de parametros.
La figura 9 representa el concepto envolvente.
En resumen, las figuras 7, 8 y 9 muestran variosconceptos de playback. Aqui, las figuras 7, 8 y 9 describen donde el oyente percibe el origen del sonido (como un area de traza oscura) . La figura 7 describe la percepcion acustica durante la reproduccion de musica. La figura 8 describe la percepcion acustica y/ o localizacion del sonido utilizando el concepto Directo / Ambiente. La figur a 9 describe la percepcion de sonido y/ o la localizacion del sonido utilizando el concepto envolvente.
La seccion siguiente proporciona una vision general sobre la tecnica anterior con respecto a un upmixing la seral de un canal o de dos canales para formar una version de multiples canales. La literatura ensera varios procedimientos para el upmixing de serales de un solo canal y las serales de multiples canales.
Procedimientos no senaladaptivos
La mayoria de procedimientos para la generacion de una asi llamada seral... [Seguir leyendo]
Reivindicaciones:
REIVINDICACIoNES
1º Aparato (100; 200; 300; 510) para generar una seral de ambiente (132; 252, 254; 342; 512) a partir de una seral de audio (108; 208; 308; 508) , que comprende:
medios (110; 220; 320) para una compresion con perdidas de una representacion espectral (108; 212; 316) de la seral de audio para obtener una representacion comprimida (112; 222; 322) de la seral de audio;
medios (122; 230; 330) para calcular una diferencia entre la representacion comprimida (112; 222; 322) de la seral d e audio y l a r epresentacion espectral (1 08; 2 12; 31 6) d e la ser al de audio par a obtener una representacion de discriminacion (122; 232; 332) ; y
medios (1 30, 24 0, 3 40) p ara proporcionar la se ral de ambi ente (132; 25 2, 254; 34 2) empleando la representacion de discriminacion;
en el que los medios (110; 220; 320) para la compresion con perdidas estan configurados para comprimir una representacion espectral (108; 212; 316) , que describe un espectrograma de la seral de audio (108; 208; 308; 508) para obtener como representacion comprimida (112; 222; 322) una representacion espectral comprimida de la seral de audio.
2º Aparato (100; 200; 300; 510) segun la reivindicacion 1, en el que los medios (110; 220; 320) para la compresion con perdidas estan configurados para emplear, como representacion espectral (108; 212; 316; IXI) de la seral de audio (108; 208; 308; x (t) ; x[n]) , una matriz de distribucion tiempo-frecuencia (IXI) que describe un espectrograma de la seral de audio, y para aproximar la matriz de distribucion tiempo-frecuencia (IXI) por un producto (WH) de una primera matriz de aproximacion (W) y una segunda matriz de aproximacion (H) .
3º Aparato (100; 200; 300; 510) segun la reivindicacion 2, en el que los medios (110; 220; 320) para la compresion con perdidas estan configurados para emplear, como representacion espectral (108; 212; 316; IXI) de la seral de audio (108; 20 8; 30 8; x (t) ; x[n]) , una matriz d e distribuci on ti empo-frecuencia de val ores reales ( IXI) que d escribe u n espectrograma de la seral de audio.
4º Aparato (100; 200; 300; 510) segun la reivindicacion 3, en el que los medios (110; 220; 320) para la compresion con perdidas estan configurados para emplear, como representacion espectral (108; 212; 316; IXI) de la seral de audio (108; 208; 308; x (t) ; x [n]) , una matriz de distribucion tiempo-frecuencia (IXI) , cuyas entradas (X) describen amplitudes o energias en la pluralidad de dominios de frecuencia (O) de la seral de audio para una pluralidad de intervalos de tiempo.
5º Aparato (100; 200; 300; 510) segun cualquiera de las reivindicaciones 2 a 4, en el que los medios (110; 220; 320) para la compresion con perdidas estan configurados para emplear, como representacion espectral (108; 212; 316) de la seral de audio (108; 208; 308; x (t) ; x[n]) , una matriz de distribucion tiempo-frecuencia (IXI) que comprende entradas exclusivamente no-negativas o exclusivamente no-positivas.
6º Aparato (100; 200; 300; 510) segun cualquiera de las reivindicaciones 2 a 5, en el que los medios (110; 220; 320) para la compresion con perdidas estan configurados para aproximar la matriz de distribucion tiempo-frecuencia (IXI) por un producto (WH) de la primera matriz de aproximacion (W) y la segunda matriz de aprox imacion (H) , de modo que la primera matriz de aproximacion ( W) y la segunda matriz de aproximacion ºHº tienen entradas exclusivamente no negativas o entradas exclusivamente no-positivas, o de modo que la primera matriz de aproximacion (W) tiene entradas exclusivamente no-negativas y la segunda matriz de aproximacion (H) tiene entradas exclusivamente no-positivas, o de modo que la primera matriz de aproximacion (W) tiene entradas exclusivamente no-positivas yla segunda matriz de aproximacion (H) tiene entradas exclusivamente no-negativas.
7º Aparato (100; 200; 300; 510) segun cualquiera de las reivindicaciones 2 a 6, en el que los medios (110; 220; 320) para la compresion con perdidas estan configurados para determinar entradas de la primera matriz de aproximacion (W) y entradas de la s egunda matriz de a proximacion ( H) medi ante la evaluacion de una func ion de c oste (c) que comprende una descripcion cuantitativa de una diferencia entre la matriz de distribucion tiempo-frecuencia (IXI) por un lado y el producto (WH) de la primera matriz de aproximacion (W) y la segu nda matriz de aproximacion (H) por ot ra parte.
8º Aparato (100; 200; 300; 510) segun la reivindicacion 7, en el que los medios (110; 220; 320) para la compresion con perdidas estan configurados para determinar las entradas de la primera matriz de aproximacion (W) y la segunda matriz de aproximacion ( H) empleando un procedimiento para determinar un valor extremo de la funcion de coste (c) o empleando un procedimiento para una aproximacion al valor extremo de la funcion de coste (c) .
9º Aparato (100; 200; 300; 510) segun las reivindicaciones 7 o 8, en el que la funcion de coste (c) se selecciona de modo que la funcion de coste (c) comprende una parte que depende de un signo de una diferencia entre una entrada (IXIij) de la matriz de distribucion tiempo-frecuencia por un lado y una entrada ( (WH) ij) del producto (WH) de la primera matriz de aproximacion (W) y la segunda matriz de aproximacion (H) por otra parte.
10º Aparato (100; 200; 300; 510) segun las reivindicaciones 7, 8 o 9, en el que la funcion de coste (c) o una condicion limite de los medios para la compresion con perdidas se selecciona de modo que en las diferencias entre una entrada (IXIij) de la matriz de distribucion tiempo-frecuencia por un lado y una entrada ( (WH) ij) del producto (WH) de la primera matriz de aproximacion (W) y la segunda matriz de aproximacion (H) por otra parte, valores de un primer signo se prefiere que ocurran comparados con valores de un signo inverso de este ultimo.
11º Aparato (100; 200; 300, 510) segun cualquiera de las reivindicaciones 7 a 10, en el que la funcion de coste (c) esta configurada para determinar una norma de Frobenius de una diferencia por elemento entre la matriz de distribucion tiempo-frecuencia (IXI) por un lado y el producto (WH) de la primera matriz de aproximacion (W) y la segunda matriz de aproximacion (H) por otra parte.
12º Aparato (100; 200; 300, 510) segun cualquiera de las reivindicaciones 7 a 10, en el que la funcion de coste (c) esta configurada para determinar a divergencia de Kullback-Leibler generalizada de una diferencia por elemento entre la matriz de distribucion tiempo-frecuencia ( (IXI) por un lado y el producto (WH) de la primera matriz de aproximacion (W) y la segunda matriz de aproximacion (H) por otra parte.
13º Aparato (100; 200; 300, 510) segun cualquiera de las reivindicaciones 2 a 12, en el que la matriz de distribucion tiempo-frecuencia (IXI) comprende una primera dimension de matriz n asociada y una segunda dimension de matriz m asociada; en el que la primera matriz de aproximacion (W) comprende una primera dimension de matriz n asociada y una segunda dimension de matriz r asociada; en el que la segunda matriz de aproximacion (H) comprende una primera dimension de matriz r asociada y una segunda dimension de matriz m asociada; y en el que es verdad lo siguiente:
14º Aparato (100; 200; 300, 510) segun cualquiera de las reivindicaciones 2 a 13, en el que los medios (120; 230; 330) para calcular una diferencia estan configurados para derivar una matriz de error de aproximacion (IAI) de modo que los elementos (A) de la matriz de error de aproximacion (IAI) son una funcion de una diferencia entre elementos de la matriz de distribucion tiempo-frecuencia (IXI) por un la do yelementos ( (WH) ij) del prod ucto (WH) de la primera matriz d e aproximacion (W) y la segunda matriz de aproximacion (H) por otra parte; en el que la matriz de error de aproximacion (IAI) constituye la representacion de discriminacion (122; 232; 332) .
15º Aparato (100; 200; 300; 510) segun la reivindicacion 14, en el que los medios (120; 230; 330) para calcular una diferencia esta configurada para determinar, en el calculo de una entrada determinada (IAIij) de la matriz de error de aproximacion (IAI) , una diferencia entre una entrada (IXijI) de la matriz t iempo-frecuencia (IXI) asociada a la entrada determinada (IAIij) por un lado y una entrada ( (WH) ij) del producto (WH) de la primera matriz de aproximacion (W) y la segunda matriz de aproximacion (H) asociada a la entrada determinada (IXIij) por otra parte, ypara calcular la entrada determinada (IAIij) de la matriz de error de aproximacion (IAI) como unafuncion de la diferencia por ponderacion de la diferencia en funcion de el signo de la diferencia.
16º Aparato (100; 200; 300; 510) segun la reivindicacion 14, en el que los medios (120; 230; 330) para calcular estan configurados para determinar, en el calculo de una entrada determinada (IAIij) de la matriz de error de aproximacion (IAI) , una diferencia entre una entrada (IXIij) de la matriz tiempo-frecuencia (IXI) asociada a la entrada determinada (IAIij) por un lado y una entrada (WH) ij) del producto (WH) de la primera matriz de aproximacion (W) y la segunda matriz de aproximacion (H) , que se pondera por un factor de ponderacion (º) no igual a uno asociado con la entrada determinada (IAIij) por otra parte, y para determinar la entrada determinada (IAIij) de la matriz de error de aproximacion (IAI) para que sea una magnitud de la diferencia.
17º Aparato (100; 200; 300; 510) segun cualquiera de las reivindicaciones 2 a 16, en el que los medios (120; 230; 330) para calcular la diferencia entre la representacion comprimida (112; 222; 322;X A ) de la seral de audio (108; 208; 308) y la representacion (108; 212; 316; IXIº de la seral de audio esta configurada para describir la diferencia por una medida de cantidad de valores reales (IAI) ; y en el que los medios (130; 240; 334) para proporcionar la seral de ambiente (132; 242; 336; 352, 254; 342) estan configurados para asignar un valor de fase (<) derivado de una representacion (108; 212; 312) d e la se ral d e au dio a la difer encia, descrita po r la medi da d e cantid ad d e valores re ales ( IAI) , entre l a representacion comprimida de la seral de audio y la representacion de la seral de audio, para obtener la seral de ambiente.
18º Aparato (100; 200; 300; 510) segun la reivindicacion 17, en el que los medios (130; 240; 334) para proporcionar estan configurados para asignar un valor de fase ( <) obtenido en la matriz de distrib ucion tiempo-frecuencia (X) a la diferencia descrita por la medida de cantidad de valores reales (IAI) .
19º Aparato (500) para obtener una seral de audio multi-canal que comprende una seral de altavoz frontal (562, 564, 566) y una seral de altavoz posterior (542, 544) a partir de una seral de audio (508) , que comprende:
un aparato (100; 200; 300; 510) para generar una seral de ambiente (512) a partir de una seral de audio (508) segun cualquiera de las reivindicaciones 1 a 18,
en el que el aparato (510) para generar la seral de ambiente (512) esta configurado para recibir la seral de audio (508) ;
un aparato (550, 560) para proporcionar la seral de audio (508) o una seral derivada de esta como seral de altavoz frontal (563, 564, 566) ; y
un aparato qu e pr oporciona la se ral d e altavoz p osterior (5 20, 530, 540) p ara proporcionar l a s eral d e ambiente (512) proporcionada por el aparato (510) para generar la seral de ambiente (512) o una seral derivada de esta como seral de altavoz posterior (542, 544) .
20º Aparato (500) segun la reivindicacion 19, en el q ue el aparato que proporciona la seral de altavoz posterior (520, 530, 540) esta configurado para generar la seral de altavoz posterior (542, 544) de modo que la seral de altavoz posterior esta retardada comparado con la seral de altavoz frontal (562, 564, 566) en un intervalo entre un milisegundo y 50 milisegundos.
21º Aparato (500) segun las reivindicaciones 19 o 20, en el que el aparato que proporciona la seral de altavoz posterior (520, 530, 540) esta configurado para atenuar partes de seral de tipo impulso en la seral de altavoz posterior (542, 544)
o para eliminar las partes de seral de tipo impulso de la seral de altavoz posterior (542, 544) .
22º Aparato (500) segun cualquiera de las reivindicaciones 19 a 21, en el que el aparato que proporciona la seral de altavoz posterior (520, 530, 540) esta configurado para proporcionar, a partir de la seral de ambiente proporcionada por el aparato (510) para generar la seral de ambiente (512) , una primera seral de altavoz posterior (542) para un primer altavoz posterior y una segunda seral de altavoz posterior (544) para un segundo altavoz posterior.
23º Aparato (500) segun la reivindicacion 22, en el q ue el aparato que proporciona la seral de altavoz posterior (520, 530, 540) esta configurado para proporcionar la primera seral de altavoz posterior (542) y la segunda seral de altavoz posterior (544) a partir de la seral de ambiente (512) de modo que la primera seral de altavoz posterior yla segunda seral de altavoz posterior estan al menos parcialmente descorrelacionadas entre si.
24º Procedimiento (600) para generar una seral de ambiente (132; 242; 252; 254; 336; 342) a partir de una seral de audio (108; 208; 308) , que comprende:
la compresion con perdidas (610) de una representacion espectral (108; 212; 316) de la seral de audio, que describe un espectrograma de la seral de audio, para obtener una representacion espectral comprimida (112; 222; 322) de la seral de audio;
calcular (620) una diferencia (122; 232; 332) entre la representacion espectral comprimida de la seral de audio y la representacion espectral de la seral de audio para obtener una representacion de discriminacion (122; 232; 332) ; y
proporcionar (630) la seral de ambiente empleando la representacion de discriminacion.
25º Procedimiento para obtener una seral de audio multi-canal que comprende una seral de altavoz frontal y una seral de altavoz posterior a partir de una seral de audio, que comprende:
generar una seral de ambiente de la seral de audio segun la reivindicacion 24;
proporcionar la seral de audio o una seral derivada de esta como seral de altavoz frontal; y
proporcionar la seral de ambiente o una seral derivada de esta como seral de altavoz posterior.
26º Programa de ordenador para realizar el procedimiento segun las reivindicaciones 24 o 25 cuando el programa de ordenador se ejecuta en un ordenador.
Patentes similares o relacionadas:
Aparato de codificación de señal de audio, dispositivo de decodificación de señal de audio y métodos del mismo, del 15 de Julio de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato de codificación de señal de audio, que comprende: un transformador de tiempo-frecuencia que genera un espectro que comprende realizar […]
Sistema de filtro que comprende un convertidor de filtro y un compresor de filtro y método de funcionamiento del sistema de filtro, del 15 de Julio de 2020, de DOLBY INTERNATIONAL AB: Compresor de filtro para generar respuestas a los impulsos del filtro de subbanda comprimida de las respuestas a los impulsos del filtro de subbanda […]
Aparato, método y programa informático para decodificar una señal de audio codificada, del 8 de Julio de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Aparato para decodificar una señal de audio codificada que comprende una señal central codificada y datos paramétricos , que comprende: un decodificador […]
Método de predicción y dispositivo de decodificación para la señal de la banda de expansión del ancho de banda, del 24 de Junio de 2020, de Crystal Clear Codec, LLC: Un método para predecir una señal de banda de frecuencia de extensión del ancho de banda, que comprende: demultiplexación de un flujo de bits recibido y […]
Codificador de audio, decodificador de audio, procedimiento para codificar una señal de audio y procedimiento para decodificar una señal de audio codificada, del 24 de Junio de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador para codificar una señal de audio , donde el codificador está configurado para codificar la señal de audio […]
Método y sistema para codificar una señal de sonido estéreo utilizando parámetros de codificación de un canal primario para codificar un canal secundario, del 24 de Junio de 2020, de VOICEAGE CORPORATION: Un método de codificación de sonido estéreo para codificar canales izquierdo y derecho de una señal de sonido estéreo, que comprende: mezclar por […]
Codificación de audio, del 10 de Junio de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de codificación de audio, que comprende: realizar procesamiento de transformación de tiempo-frecuencia sobre una señal en el dominio del […]
Reducción de solapamiento en dominio de tiempo para bancos de filtros no uniformes que usan análisis espectral seguido por síntesis parcial, del 3 de Junio de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un procesador de audio para procesar una señal de audio para obtener una representación de subbanda de la señal de audio , comprendiendo el procesador […]