CIP-2021 : G10L 15/06 : Creación de plantillas de referencia; Entrenamiento de sistemas de reconocimiento de la voz,
p. ej. adaptación a las características de la voz de la persona que habla (G10L 15/14 tiene prioridad).
CIP-2021 › G › G10 › G10L › G10L 15/00 › G10L 15/06[1] › Creación de plantillas de referencia; Entrenamiento de sistemas de reconocimiento de la voz, p. ej. adaptación a las características de la voz de la persona que habla (G10L 15/14 tiene prioridad).
G FISICA.
G10 INSTRUMENTOS MUSICALES; ACUSTICA.
G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ.
G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad).
G10L 15/06 · Creación de plantillas de referencia; Entrenamiento de sistemas de reconocimiento de la voz, p. ej. adaptación a las características de la voz de la persona que habla (G10L 15/14 tiene prioridad).
CIP2021: Invenciones publicadas en esta sección.
Creación de una base de datos de referencia de parámetros de habla para clasificar expresiones del habla.
(24/01/2018) Un método implementado por ordenador de creación de una base de datos de referencia de parámetros de habla para clasificar expresiones del habla según diversas características de comportamiento, psicológicas y de estilos de habla, dicho método implementado por ordenador que comprende:
seleccionar manualmente un cierto contexto de habla;
seleccionar manualmente las características de comportamiento, psicológicas y de estilos de habla a ser analizadas en el contexto seleccionado;
obtener una pluralidad de expresiones del habla de personas en el contexto seleccionado;
agrupar manualmente las expresiones del habla en grupos que…
Mapeo de una enunciación de audio a una acción usando un clasificador.
(23/08/2017) Un método, que comprende:
recibir , mediante un dispositivo informático , una enunciación de audio;
determinar una cadena de texto basándose en la enunciación;
determinar un vector de característica de cadena basándose en la cadena de texto, incluyendo el vector de característica de cadena una o más características de cadena;
recibir datos de sensor;
determinar un vector de característica de sensor basándose en los datos de sensor, incluyendo el vector de característica de sensor una o más características de sensor;
seleccionar un clasificador objetivo de un conjunto de clasificadores, en donde el clasificador…
Sistema y método para reconocer un comando de voz de usuario en un entorno con ruido.
(01/04/2015) Sistema automático de reconocimiento de voz para reconocer un comando de voz de usuario en un entorno con ruido, que comprende:
- unos medios de concordancia para hacer concordar unos elementos recuperados a partir de unas unidades de habla que forman dicho comando, con unas plantillas de una biblioteca de plantillas ;
- unos medios de procesado que incluyen un Perceptrón Multicapa para calcular plantillas a posteriori P(Oplantilla(q)) almacenadas como dichas plantillas en dicha biblioteca de plantillas ;
- unos medios para recuperar unos vectores a posteriori P(Oprueba(q)) a partir de dichas unidades de habla,…
METODO PARA ADAPTAR DINAMICAMENTE LOS MODELOS ACUSTICOS DE RECONOCIMIENTO DEL HABLA AL USUARIO.
(17/12/2009). Ver ilustración. Solicitante/s: FRANCE TELECOM ESPAA, S.A.. Inventor/es: MASO BESGA,ALVARO, BREZMES LLECHA,TOMAS.
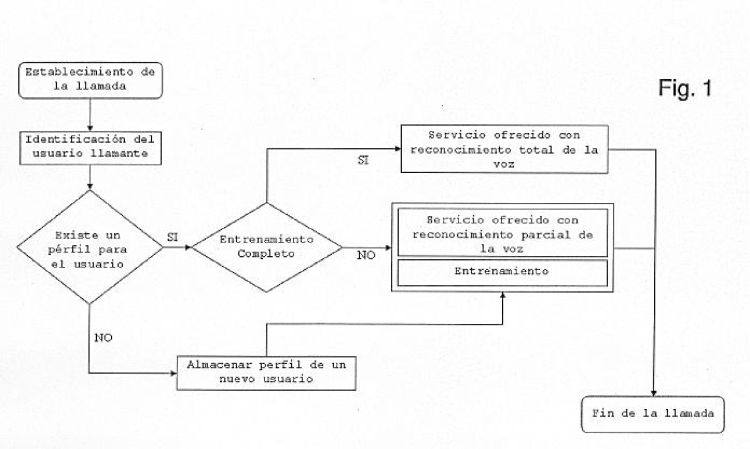
Método para adaptar dinámicamente los modelos acústicos de reconocimiento del habla al usuario, que permite mejorar la eficiencia de los sistemas de reconocimiento del habla utilizados por los teleoperadores (o cualquier servicio que requiera de reconocimiento del habla a través de las redes de telecomunicaciones) y que se basa en el envío de datos del perfil de habla del usuario, obtenidos en un único entrenamiento previo y válido para todas sesiones posteriores en cualquiera de sistemas de reconocimiento del habla compatibles con este método, adaptando los modelos acústicos al locutor para mejorar la tasa de acierto de dichos sistemas y evitar al usuario la necesidad de entrenar múltiples plataformas.
METODO DE RECONOCIMIENTO DEL HABLA CON ENTRENAMIENTO PROGRESIVO.
(17/12/2009). Ver ilustración. Solicitante/s: FRANCE TELECOM ESPAA, S.A.. Inventor/es: MASO BESGA,ALVARO, BEZMES LLECHA,TOMAS.
Método de reconocimiento del habla con entrenamiento progresivo de la plataforma, permitiendo alcanzar niveles de reconocimiento similares a los de plataformas que requieren una fase de entrenamiento específico, y a su vez ofrecer servicios previamente y durante dicho proceso de entrenamiento.
PROCEDIMIENTO DE RECONOCIMIENTO DE VOZ.
(01/09/2006). Ver ilustración. Solicitante/s: PROUS SCIENCE, S.A. Inventor/es: PROUS BLANCAFORT,JOSEP, SALILLAS TELLAECHE, JES &S.
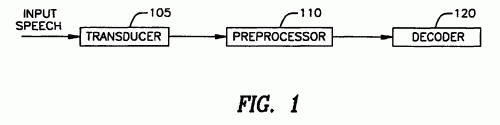
Procedimiento de reconocimiento de voz, que comprende: (a) una etapa de descomposición de una señal de voz digitalizada en una pluralidad de fracciones, (b) una etapa de representación de cada una de dichas fracciones mediante un vector representativo Xt, y (c) una etapa de clasificación de dichos vectores representativos Xt en la que cada vector representativo Xt se asocia a una representación fonética, que permite obtener una secuencia de representaciones fonéticas, caracterizado porque dicha etapa de clasificación comprende por lo menos una cuantificación vectorial residual en árbol binario multietapa.
RECONOCIMIENTO DEL HABLA ADAPTABLE A UN HABLANTE.
(16/05/2006). Ver ilustración. Solicitante/s: SRI INTERNATIONAL. Inventor/es: DIGALAKIS, VASSILIOS, NEUMEYER, LEONARDO, RTISCHEV, DIMITRY.
LA INVENCION SE REFIERE A UN METODO Y A UN APARATO PARA EL RECONOCIMIENTO VOCAL AUTOMATICO Y SE ADAPTA A UN HABLANTE PARTICULAR USANDO DATOS DE ADAPTACION PARA DESARROLLAR UNA TRANSFORMACION A TRAVES DE LA CUAL LOS MODELOS INDEPENDIENTES DE HABLANTES SE TRANSFORMAN EN MODELOS ADAPTADOS DE HABLANTE. LOS MODELOS ADAPTADOS DE HABLANTE SE USAN PARA EL RECONOCIMIENTO DEL HABLANTE Y LO REALIZAN CON UNA MAYOR PRECISION DE RECONOCIMIENTO QUE LOS MODELOS NO ADAPTADOS. EN UNA REALIZACION ADICIONAL, LA TECNICA DE ADAPTACION BASADA EN LA TRANSFORMACION SE COMBINA CON UNA TECNICA CONOCIDA DE ADAPTACION BAYESIAN.
PROCEDIMIENTO PARA LA CREACION DE SEGMENTOS DE REFERENCIA QUE DESCRIBEN MODULOS DE VOZ Y PROCEDIMIENTO PARA LA MODELIZACION DE UNIDADES DE VOZ DE UN MODELO DE PRUEBA DE VOZ.
(01/01/2006) Procedimiento para crear segmentos de referencia que describen módulos de voz a partir de señales de voz de entrenamiento pronunciadas para sistemas de reconocimiento de voz, con las siguientes etapas: - segmentación de la señal de voz de entrenamiento en módulos de voz correspondientes a una trascripción predeterminada, - análisis de la señal de entrenamiento en una cuadrícula temporal predeterminada con determinadas ventanas temporales para obtener al menos un vector característico para cada ventana temporal, de tal modo que se configuran modelos de entrenamiento que contienen en cada caso vectores característicos…
PROCEDIMIENTO PARA EL RECONOCIMIENTO DE MANIFESTACIONES VERBALES DE ORADORES QUE NO HABLAN SU PROPIO IDIOMA EN UN SISTEMA DE PROCESAMIENTO DE VOZ.
(16/12/2005) Dispositivo de reconocimiento de voz para reconocer y procesar manifestaciones verbales de un usuario en un primer idioma con un primer modelo de lenguaje basado en fonemas (2a) para reconocer manifestaciones verbales en un primer idioma y un segundo modelo de lenguaje basado en fonemas (2b) para reconocer manifestaciones verbales en un segundo idioma y un dispositivo de selección , que en base a una manifestación verbal del usuario automáticamente elige el primer o el segundo modelo de lenguaje (2a, 2b) para el reconocimiento de voz, eligiéndose aquel modelo de lenguaje (2a, 2b) que aporta un mejor resultado de reconocimiento de los fonemas hablados de este usuario, caracterizado…
MODELOS ACUSTICOS CONTEXTUALES PARA EL RECONOCIMIENTO DEL HABLA CON UN ENTRENAMIENTO DE AUTOVOCES.
(01/12/2005). Ver ilustración. Solicitante/s: MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.. Inventor/es: JUNQUA, JEAN-CLAUDE, KUHN, ROLAND, CONTOLINI, MATTEO.
Método para desarrollar modelos contextuales para el reconocimiento automático de habla que comprende: generar un autoespacio para representar una población de hablantes de entrenamiento; proporcionar un conjunto de datos acústicos para al menos un hablante del entrenamiento y representar dichos datos acústicos en dicho autoespacio para determinar al menos un centroide de alófono para dicho hablante de entrenamiento; y sustraer dicho centroide de dichos datos acústicos para generar datos acústicos adaptados al hablante para dicho hablante de entrenamiento; emplear dichos datos acústicos adaptados al hablante para desarrollar al menos un árbol de decisión que tiene nodos hoja que contienen modelos contextuales para diferentes alófonos.
SISTEMA DE RECONOCIMIENTO DE HABLA CON LEXICO ACTUALIZABLE MEDIANTE INTRODUCCION DE PALABRAS DELETREADAS.
(01/06/2005). Solicitante/s: MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.. Inventor/es: JUNQUA, JEAN-CLAUDE.
Un sistema de reconocimiento de habla con un léxico actualizable mediante la entrada de palabras deletreadas que comprende: un fonetizador para generar una transcripción fonética de dicha palabra deletreada entrada; un generador de unidades híbridas receptor de dicha transcripción fonética para generar al menos una representación de unidad híbrida de dicha palabra deletreada entrada basada en dicha transcripción fonética, una unidad híbrida que comprende una mezcla de varias unidades de sonido distintas que incluye al menos una de las sílabas, semisílabas o fonemas; y un constructor de plantillas de palabras que genera, para dicha palabra deletreada, una secuencia de símbolos indicativa de la representación de dicha unidad híbrida para almacenarla en dicho léxico.
PROCEDIMIENTO PARA SISTEMA DE RECONOCIMIENTO DE LENGUAJE Y PROCEDIMIENTO PARA EL FUNCIONAMIENTO DE UN SISTEMA ASI.
(16/04/2005) Sistema de reconocimiento de lenguaje para la introducción controlada por lenguaje de mensajes cortos en un aparato terminal de telecomunicaciones , en particular teléfono móvil o sin hilos, con un módulo reconocedor de lenguaje que funciona independientemente de la persona que habla, en el que está memorizado o bien puede establecerse un vocabulario específico para elaborar mensajes cortos, llevando cada elemento del vocabulario asociado al menos un fonema y representando cada fonema al menos un sonido según una trascripción fonética predeterminada, caracterizado por una memoria intermedia de vocabulario de mensajes para la memorización temporal de un mensaje breve enviado o recibido, una unidad comparadora de vocabulario unida por un lado con la memoria intermedia…
PROCEDIMIENTO Y DISPOSICION PARA EL RECONOCIMIENTO DE VOZ PARA UN APARATO PEQUEÑO.
(16/06/2004). Ver ilustración. Solicitante/s: SIEMENS AKTIENGESELLSCHAFT. Inventor/es: SCHNEIDER, TOBIAS, DR., NIEMOELLER, MEINRAD.
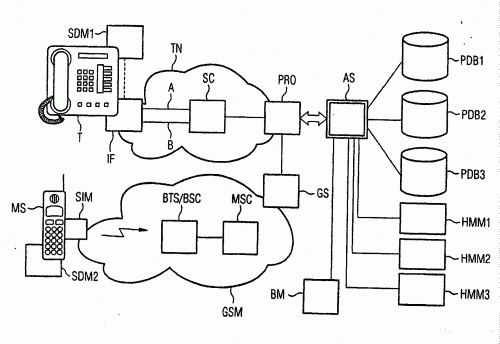
Procedimiento para el reconocimiento de voz independiente del locutor para un aparato electrónico (MS, T) pequeño, especialmente un terminal pequeño, con una instalación de entrada de voz y una instalación de transmisión de voz así como con una memoria de datos de voz (SDM1, SDM2) para la memorización interna de un conjunto de datos de voz en una red de telecomunicaciones (GSM, TN), caracterizado porque se pronuncian palabras seleccionadas de un vocabulario de reconocimiento de voz en el aparato pequeño, se transmiten los datos de voz, que corresponden a las palabras pronunciadas, a un servidor central (AS) en la red de telecomunicaciones y se procesan en una instalación de adaptación del locutor prevista en esta red utilizando un conjunto de datos de voz específicos del usuario memorizados en el servidor y se transmite una fuente de conocimientos acústica adaptada, contenida en el resultado del procesamiento, al aparato pequeño y se memoriza en su memoria de datos de voz.
PROCEDIMIENTO Y DISPOSICION PARA EL RECONOCIMIENTO DE VOZ INDENPENDIENTE DEL LOCUTOR PARA UN TERMINAL DE TELECOMUNICACIONES O TERMINALES DE DATOS.
(16/06/2004) Procedimiento para el reconocimiento de voz independiente del locutor para un terminal de telecomunicaciones o terminal de datos (MS,T) en una red de telecomunicaciones y red de datos (GSM,TN), respectivamente, donde el terminal recibe palabras pronunciadas y las emite como palabras escritas y/o las utiliza internamente para fines de control así como se pueden introducir en el terminal palabras nuevas para la ampliación del vocabulario como palabras escritas con la finalidad de la creación de una trascripción fonética, donde las palabras nuevas escritas son transmitidas por el terminal a través de un trayecto de transmisión de datos (B) de la red de telecomunicaciones y de la red de datos, respectivamente, hacia un servidor central (TS),…
DISCRIMINACION ENTRE VOZ Y SILENCIO BASADA EN UNA ADAPTACION DE LOS MODELOS OCULTOS DE MARKOV, NO SUPERVISADA.
(01/04/2004). Ver ilustración. Solicitante/s: AT&T CORP.. Inventor/es: NARAYANAN, SHRIKANTH SAMBASIVAN, POTAMIANOS, ALEXANDROS, ZELJKOVIC, ILIJA.
SE PRESENTA UNA ADAPTACION HMM, DE NIVEL DE SENTENCIA, DISCRIMINATORIA, NO SUPERVISADA, BASADA EN LA CLASIFICACION DE CONVERSACION-SILENCIO. SE DETERMINAN LAS REGIONES DE SILENCIO Y DE CONVERSACION MEDIANTE EL USO DE UN PUNTERO DE FIN DE CONVERSACION O LA SEGMENTACION OBTENIDA DESDE EL DISPOSITIVO RECONOCEDOR EN UN PRIMER PASO. A CONTINUACION, SE UTILIZA EL PROCEDIMIENTO DE APRENDIZAJE DISCRIMINATORIO MEDIANTE UN GPD O CUALQUIER OTRO ALGORITMO DE APRENDIZAJE DISCRIMINATORIO, EN COMBINACION CON EL DISPOSITIVO RECONOCEDOR BASADO EN HMM, PARA AUMENTAR LA DISCRIMINACION ENTRE EL SILENCIO Y LA CONVERSACION.
Procedimiento para incrementar la probabilidad de reconocimiento de los sistemas de reconocimiento de voz.
(16/01/2003) Procedimiento para incrementar la probabilidad de reconocimiento de los sistemas de reconocimiento de voz, en el que tras la introducción de un concepto que se trata de reconocer, tiene lugar un entrenamiento posterior del concepto similar ya registrado, sirviéndose del concepto introducido, caracterizado por a) la introducción del concepto que se trata de reconocer; b) la comparación del concepto introducido con los conceptos ya registrados en el sistema de reconocimiento de voz; c) en el caso de que el concepto haya sido reconocido unívocamente: c.1) la ejecución de la acción deseada; c.2) el entrenamiento posterior del correspondiente…
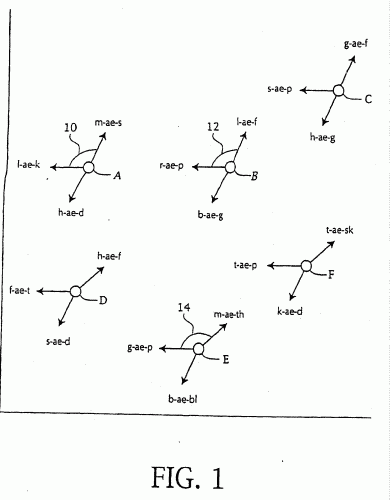
RECONOCIMIENTO DE PATRONES.
(16/11/2002). Ver ilustración. Solicitante/s: BRITISH TELECOMMUNICATIONS PUBLIC LIMITED COMPANY. Inventor/es: RINGLAND, SIMON, PATRICK, ALEXANDER, TALINTYRE, JOHN, EDWARD.
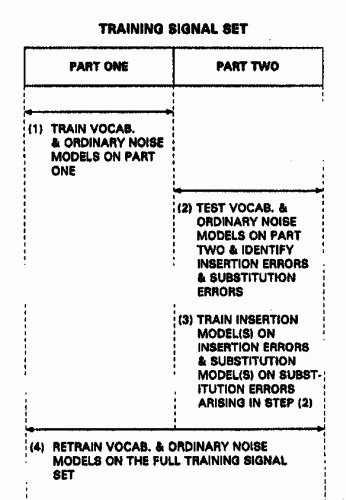
SE PROPORCIONA UN PROCEDIMIENTO PARA DERIVAR DATOS DE REFERENCIA DE RECONOCIMIENTO PARA EL USO EN RECONOCIMIENTO DE FORMAS Y, EN PARTICULAR, EL RECONOCIMIENTO DE INFORMACION LOCAL. SEGUN LA INVENCION, SE PROPORCIONAN DATOS DE REFERENCIA DE RECONOCIMIENTO QUE COMPRENDEN UNA PRIMERA PARTE QUE REPRESENTAN ELEMENTOS VALIDOS DE SONIDOS VOCALES O NO VOCALES, Y UNA SEGUNDA PARTE DERIVADA DE LAS PARTES DE UNA SEÑAL DE ENTRADA QUE SE SABEN QUE DAN ORIGEN A ERRORES DE RECONOCIMIENTO. EN PARTICULAR, SE PROPORCIONAN BLOQUES DE REFERENCIA PARA MODELAR LOS ERRORES DE INSERCION Y ERRORES DE SUSTITUCION QUE SE SABE QUE OCURREN EN LOS RESULTADOS DEL RECONOCIMIENTO.
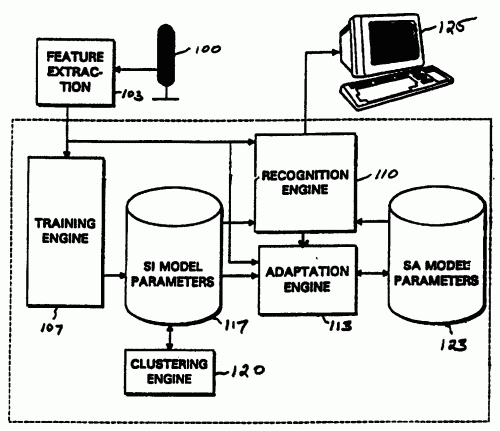
Adaptación no supervisada de un dispositivo de reconocimiento de la palabra utilizando información fiable mediante las N-mejores hipótesis.
(16/11/2002). Solicitante/s: MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.. Inventor/es: GELIN, PHILIPPE, JUNQUA, JEAN-CLAUDE, NGUYEN, PATRICK.
Un aparato de reconocimiento de voz que adapta un modelo de voz inicial basado en la entrada de voz del usuario y que comprende: un modelo de voz que representa la dicción bajo la forma de una pluralidad de modelos de unidades de voz asociados a una pluralidad de unidades de voz; un dispositivo de reconocimiento de voz que procesa la entrada de voz de un usuario mediante dicho modelo de voz para generar las N-mejores soluciones de reconocimiento; un sistema de extracción de información fiable para analizar dichas N-mejores soluciones de reconocimiento y seleccionar un conjunto de candidatos de reconocimiento ábles de entre dichas N-mejores soluciones de reconocimiento; un sistema de adaptación que utiliza dichos candidatos de reconocimiento ábles para adaptar el modelo de voz mencionado.
PROCEDIMIENTO PARA CONTROLAR AUTOMATICAMENTE UNO O VARIOS APARATOS MEDIANTE COMANDOS DE VOZ O DIALOGO DE VOZ EN FUNCIONAMIENTO EN TIEMPO REAL Y DISPOSITIVO PARA EJECUTAR EL PROCEDIMIENTO.
(16/08/2002) LA INVENCION SE REFIERE A UN METODO PARA CONTROLAR AUTOMATICAMENTE EQUIPOS MEDIANTE DIALOGO DE VOZ QUE UTILIZA METODOS DE EMISION DE VOZ, DE PREPROCESO DE LA SEÑAL DE VOZ Y DE RECONOCIMIENTO DE VOZ, DE POSTPROCESO SINTACTICO-GRAMATICAL , ASI COMO DE CONTROL DE DIALOGOS, DE SECUENCIA Y DE INTERFACES. EL METODO SE CARACTERIZA PORQUE LA ESTRUCTURA DE LA SINTAXIS Y DE LOS COMANDOS SE FIJAN DURANTE EL DESARROLLO DEL DIALOGO EN TIEMPO REAL; EL PREPROCESO, EL RECONOCIMIENTO Y EL CONTROL DE DIALOGOS ESTAN DISEÑADOS PARA OPERAR EN UN ENTORNO DISTORSIONADO POR RUIDOS; NO PRECISA FORMACION DE USUARIO PARA EL RECONOCIMIENTO DE LOS COMANDOS GENERALES; ES NECESARIA LA FORMACION PARA EL RECONOCIMIENTO DE LOS COMANDOS ESPECIFICOS DE LOS DIFERENTES USUARIOS; LA ENTRADA DE LOS COMANDOS…
Procedimiento de búsqueda por el contenido de documentos textuales utilizando el reconocimiento oral.
(16/12/2001). Solicitante/s: FRANCE TELECOM SA. Inventor/es: FERRIEUX, ALEXANDRE, PEILLON, STEPHANE.
Procedimiento consistente en buscar en un texto una expresión objeto de una petición enunciada oralmente, caracterizado porque consiste en transcribir dicho texto en una primera sucesión de unidades fonéticas, segmentar dicha petición oral en una segunda sucesión de unidades fonéticas discretas y buscar las coincidencias de la expresión objeto de dicha petición en el texto mediante un proceso de alineación de la primera y la segunda sucesión de unidades fonéticas.
METODO Y DISPOSITIVO PARA ADAPTAR UN EQUIPO DE RECONOCIMIENTO DEL HABLA A LAS VARIANTES DIALECTALES DE UNA LENGUA.
(01/02/2001) LA PRESENTE INVENCION SE RELACIONA CON UN METODO Y UN DISPOSITIVO PARA EL RECONOCIMIENTO DE LAS VARIANTES DIALECTALES DE UNA LENGUA A PARTIR DE UN HABLA DADA. POR UN LADO, SE LLEVA A CABO UN PROCEDIMIENTO DE RECONOCIMIENTO DEL HABLA A PARTIR DE UNA DISCURSO DE ENTRADA, Y, POR OTRO LADO, SE EXTRAE LA CURVA DEL TONO FUNDAMENTAL. A PARTIR DEL RECONOCIMIENTO DEL HABLA SE CREA UNA CADENA DE ALOFONOS QUE JUNTO CON LA CURVA DEL TONO FUNDAMENTAL SE UTILIZA PARA LA DETECCION DE LOS VALORES MAXIMOS Y MINIMOS DE DEL TONO FUNDAMENTAL. EL HABLA RECONOCIDA ES COMPARADA CON UN DICCIONARIO CON ORTOGRAFIA Y TRANSCRIPCION PARA ENCONTRAR LOS CANDIDATOS DE LAS PALABRAS ADECUADAS. POSTERIORMENTE, LOS CANDIDATOS DE LAS PALABRAS SON ANALIZADOS SEGUN LA SINTAXIS. ESTA INFORMACION LEXICA Y SINTACTICA ENCONTRADA SEGUN LA FORMA…
EQUIPO GENERADOR DE ANTI-RUIDOS PARA VEHICULOS A MOTOR CON DISPOSITIVO DE ALARMA.
(01/01/2001) EL EQUIPO COMPRENDE PRIMEROS TRANSDUCTORES ACUSTICOS-ELECTRICOS PARA PROPORCIONAR SEÑALES ELECTRICAS QUE INDIQUEN EL RUIDO EN UN LUGAR DEL VEHICULO A MOTOR, SEGUNDOS TRANSDUCTORES ELECTRICO-ACUSTICOS , Y UNA UNIDAD ELECTRONICA QUE, EN UN PRIMER MODO OPERATIVO, PUEDE PILOTAR LOS SEGUNDOS TRANSDUCTORES DEPENDIENDO DE LAS SEÑALES PROPORCIONADAS POR LOS PRIMEROS , PARA PROVOCAR LA GENERACION DE ONDAS DE PRESION (ANTI-RUIDO) QUE PUEDEN CANCELAR LAS ONDAS DE RUIDO. LA UNIDAD PUEDE TAMBIEN LLEVAR A CABO SELECTIVAMENTE UN SEGUNDO MODO OPERATIVO, ALTERNATIVO AL PRIMERO, EN QUE PILOTA LOS SEGUNDOS TRANSDUCTORES PARA PROVOCAR LA GENERACION DE ONDAS DE PRESION, DE CARACTERISTICAS DETERMINADAS,…
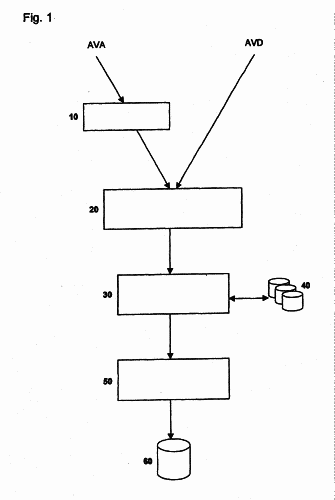
SISTEMA AUTOMATICO PARA ADQUISICION GUIADA DE SEÑALES DE VOZ DE LINEAS TELEFONICAS.
(01/05/2000). Solicitante/s: ALCATEL. Inventor/es: KOPP, DIETER, HUZENLAUB, RICHARD.
LA INVENCION SE REFIERE A UN SISTEMA AUTOMATICO PARA ADQUISICION GUIADA DE SEÑALES ORALES DESDE UNA LINEA TELEFONICA. AL AUTOMATIZAR EL PROCESO DE ADQUISICION DE SEÑALES ORALES BAJO CONTROL DE UNA UNICA UNIDAD DE CONTROL INTELIGENTE,EL TRABAJO DEL OPERADOR DE TELEFONO ES MUCHO MAS FACIL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}