Procedimiento para identificar a un hablante usando ecualización de formante.
Un procedimiento para la identificación de un hablante a partir de una grabación de audio de habla oral,
en el que el procedimiento comprende:
evaluar la similitud entre una primera grabación de audio de un hablante y una segunda grabación de audio o muestra por una coincidencia de las frecuencias de los formantes en los fragmentos de referencia de la señal de voz seleccionada para la comparación a partir de la primera grabación de audio y la segunda grabación de audio, y comprende además:
seleccionar fragmentos de referencia de la señal de voz desde la primera grabación de audio y la segunda grabación de audio de manera que los fragmentos de referencia comprendan trayectorias de los formantes de al menos tres frecuencias de los formantes;
para cada fragmento de referencia de la primera grabación de audio, seleccionar un fragmento de referencia de la segunda grabación de audio para la comparación, de manera que los fragmentos de referencia a ser comparados tengan valores de frecuencia de formantes coincidentes para al menos dos frecuencias de los formantes;
evaluar la similitud de dichos fragmentos de referencia a ser comparados mediante la comparación de las frecuencias de los formantes restantes, en el que dichos fragmentos de referencia a ser comparados coinciden si sus frecuencias de los formantes restantes coinciden dentro de una desviación predeterminada, en el que la similitud de las grabaciones de audio es reconocida si todos los fragmentos de referencia comparados coinciden.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/RU2010/000661.
Solicitante: SPEECH TECHNOLOGY CENTER LIMITED.
Nacionalidad solicitante: Federación de Rusia.
Dirección: 4 Krasutskogo street, lit. A St. Petersburg, 196084 FEDERACION RUSA.
Inventor/es: KOVAL,SERGEY LVOVICH.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L17/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 17/00 Identificación o verificación de la persona que habla. › Operaciones anteriores al procesamiento, p. ej. elección del segmento; Representación o modelado de patrones, p. ej. basados en Análisis Discriminante Linear (LDA) o componentes principales; Elección o extracción de características.
- G10L17/06 G10L 17/00 […] › Técnicas de toma de decisiones; Estrategia de ajuste de patrones.
- G10L17/20 G10L 17/00 […] › Transformación de patrones operaciones dirigidas al incremento de la robustez del sistema, p. ej. contra el ruido del canal o las diferentes condiciones de trabajo.
- G10L25/15 G10L […] › G10L 25/00 Técnicas de análisis del habla o voz no restringidos a un solo de los grupos G10L 15/00 - G10L 21/00 (silenciar los amplificadores basados en semiconductores, cuando algunas de las características especiales de una señal son detectadas por un detector de voz, p. ej. detectar cuando no hay ninguna señal, H03G 3/34). › siendo los parámetros estraídos información de la estructura de la formación del habla.
PDF original: ES-2547731_T3.pdf

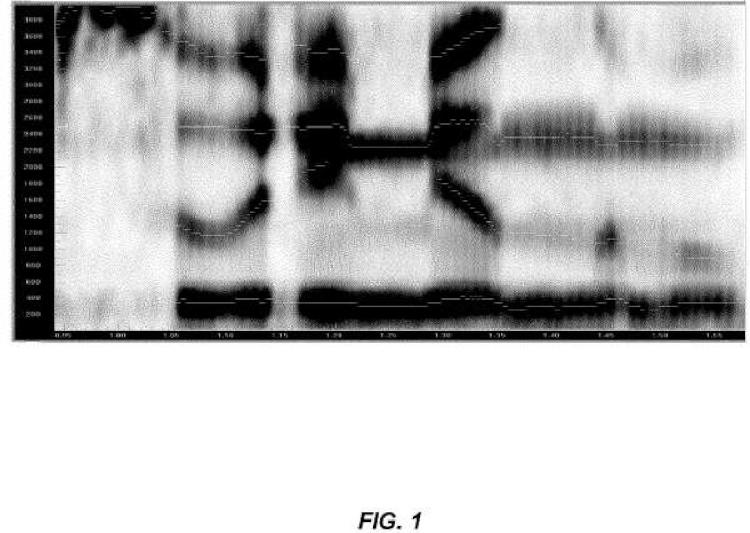
Fragmento de la descripción:
Procedimiento para identificar a un hablante usando ecualización de formante Campo técnico
La invención se refiere al campo de reconocimiento de voz de hablante, particularmente a procedimientos automáticos, automatizados y expertos para la identificación de un hablante a partir de grabaciones de audio de habla oral espontánea. Los procedimientos están destinados a, pero no se limitan a, examen forense.
Se conocen investigaciones prácticas, particularmente el examen forense y la comparación de grabaciones de audio de habla oral para identificar un hablante, en algunos casos para adoptar decisiones difíciles que presentan obstáculos a la evaluación experta. Dichos obstáculos pueden incluir una duración corta y una baja calidad de las grabaciones de audio examinadas, estados psico-fisiológicos diferentes de los hablantes en las grabaciones de audio comparadas, contenidos y lenguajes del habla diferentes, tipos y niveles de ruido y distorsión diferentes del canal de audio, etc.
Por lo tanto, es deseable proporcionar procedimientos para la identificación de un hablante a partir de grabaciones de audio de habla oral espontánea, en los que los procedimientos sean aplicables a, pero no se limiten a, examen forense y tengan en cuenta los problemas Indicados anteriormente, En particular, es deseable proporcionar procedimientos que permitan la Identificación de un hablante a partir de grabaciones de audio cortas de habla oral grabadas en diversos canales de grabación de audio, con altos niveles de ruido y distorsión, así como a partir de grabaciones de audio con hablantes en estados pisco-fisiológicos diferentes, con contenidos verbales diferentes del habla oral, o habla oral en idiomas diferentes.
Técnica anterior
Se conoce un procedimiento de identificación de un hablante a partir de grabaciones de audio, en el que las características del hablante son extraídas a partir de ciertas frases de tipo único pronunciadas por el hablante (DE 2431458, 2/05/1976).
Este procedimiento comprende el filtrado de una señal de voz a través de un peine de 24 filtros de paso de banda, la detección de la señal, el suavizado de la señal y la introducción de la señal a través de un convertidor analógico- digital y un conmutador a un dispositivo de procesamiento digital, en el que las características distintivas asociadas con el espectro de voz integral son reconocidas y almacenadas automáticamente.
Sin embargo, este procedimiento no puede ser usado con grabaciones de audio de habla oral obtenidas en un entorno de alta distorsión y ruido ya que el procedimiento no puede proporcionar un número suficiente de características distintivas. Además, no se ha probado que este procedimiento sea suficientemente fiable para la identificación, ya que requiere el uso de grabaciones de audio que comprenden contenido verbal idéntico tanto para un hablante verificado como para un hablante desconocido.
Se conoce un procedimiento de identificación de una grabación de audio individual mediante una entrada de voz que es comparada con una firma de voz almacenada anteriormente de ese individuo. La identificación se basa en la selección y la comparación de palabras clave de tipo único a partir de las grabaciones objeto de análisis (US 3.466.394).
Este procedimiento consiste en someter una señal de voz a un análisis espectral a corto plazo y, a continuación, determinar los contornos del espectro y el tono de voz fundamental en función del tiempo. Los contornos resultantes son considerados como características distintivas. La identificación de un hablante se basa en una comparación de los contornos de grabación de audio de las grabaciones de audio obtenidas a partir de un hablante verificado y un hablante desconocido.
El punto débil de este procedimiento es que el resultado de la identificación depende de la calidad de grabaciones de audio obtenidas en un entorno de alta distorsión y ruido. Además, este procedimiento tiene un alto porcentaje de fallos de identificación, ya que requiere grabaciones de audio de un hablante verificado y un hablante desconocido con las mismas palabras.
Se conoce un procedimiento de identificación de un hablante basado en un análisis espectral-banda-temporal del habla oral espontánea (G.S. Ramishvili, G.B. Chikoidze Forensic examination of audio records and identification of a speaker. Tbilisi: "Mezniereba", 1991, p. 265).
Para eliminar la dependencia de los resultados de identificación de la semántica del habla, los elementos de habla sonora son seleccionados de la señal de voz, y sus valores de energía para los formantes superiores son promediados a lo largo de su vida en cada uno de los 24 filtros espectrales. El tono fundamental es determinado en base a la selección de la componente fundamental de la señal en el espectro. Se determina también el ritmo del
habla.
Los parámetros indicados anteriormente son usados como características distintivas.
Sin embargo, este procedimiento falla con grabaciones de audio obtenidas en entornos de alta distorsión de sonido en un canal de grabación de ruido y diferentes estados de los hablantes debido a que las características distintivas no pueden ser seleccionadas de manera fiable.
Se conocen un dispositivo y un procedimiento para el reconocimiento de un hablante, basados en la construcción y la comparación de modelos puramente estadísticos para características de señal cepstral de habla de hablantes conocidos y desconocidos (US 6.411.930). El reconocimiento del hablante se realiza mediante el uso de modelos Gaussianos discriminativos mixtos.
Este procedimiento, al igual que la mayoría de los enfoques puramente estadísticos para el reconocimiento del hablante, falla para mensajes de habla muy cortos (de 1 a 10 segundos), así como en las situaciones en las que los estados del hablante y/o los canales de grabación de las grabaciones de audio poseen propiedades fuertemente diferentes, o los hablantes están en estados emocionales diferentes.
Se conoce un procedimiento para el reconocimiento del hablante mediante el uso de sólo un enfoque estocástico (US 5.995.927).
Según el procedimiento, el reconocimiento del hablante se realiza mediante la construcción y la comparación de matrices de covarianza de descripción de características de una señal de voz de entrada y señales de voz de referencia de hablantes conocidos.
Este procedimiento falla también para mensajes de habla cortos (5 segundos o menos), y es muy sensible a una reducción significativa de la potencia de la señal en segmentos particulares del rango de frecuencias del habla debida al ruido ambiente, así como a una mala calidad de los micrófonos y los canales para la transmisión y la grabación de sonido.
Se conoce un procedimiento adaptable al hablante para el reconocimiento de palabras aisladas (RU 2047912). El procedimiento se basa en el muestreo de una señal de voz de entrada, sucesivamente la pre-enfatízacíón de la señal de voz, la segmentación posterior de la señal de voz, la codificación de los segmentos con elementos discretos, el cálculo del espectro de energía, la medición de las frecuencias de los formantes y la determinación de las amplitudes y las energías en diferentes bandas de frecuencia de la señal de voz, la clasificación de los eventos y los estados articulatorios, la definición y la clasificación de las muestras de palabras, el cálculo de los intervalos entre las muestras de palabras para actualizar la palabra reconocida, el reconocimiento o el fallo en el reconocimiento de la palabra, y la adición al diccionario de muestras durante la adaptación al hablante. La señal de voz de entrada es pre-enfatizada en el dominio del tiempo mediante suavización/diferenciación. El espectro de energía es cuantificado en partes discretas en función de la varianza del ruido del canal de comunicación. Las frecuencias de los formantes son determinadas buscando el máximo global del espectro logarítmico y restando una función predeterminada dependiente de la frecuencia del espectro indicado anteriormente. Durante la clasificación de eventos y estados articulatorios, se determinan las proporciones de fuentes de excitación periódicas y de ruido en comparación con el valor umbral de los coeficientes de autocorrelación de una secuencia de pulsos de onda cuadrada en múltiples bandas de frecuencia. El principio y el final de los movimientos articulatorios y sus procesos acústicos correspondientes se determinan contra el valor umbral de la función de probabilidad a partir de los coeficientes de autocorrelación, las frecuencias de los formantes y las energías en las bandas de frecuencia determinadas. La señal de voz es dividida en Intervalos de entre el principio... [Seguir leyendo]
Reivindicaciones:
1. Un procedimiento para la identificación de un hablante a partir de una grabación de audio de habla oral, en el que el procedimiento comprende:
evaluar la similitud entre una primera grabación de audio de un hablante y una segunda grabación de audio o muestra por una coincidencia de las frecuencias de los formantes en los fragmentos de referencia de la señal de voz seleccionada para la comparación a partir de la primera grabación de audio y la segunda grabación de audio, y comprende además:
seleccionar fragmentos de referencia de la señal de voz desde la primera grabación de audio y la segunda grabación de audio de manera que los fragmentos de referencia comprendan trayectorias de los formantes de al menos tres frecuencias de los formantes;
para cada fragmento de referencia de la primera grabación de audio, seleccionar un fragmento de referencia de la segunda grabación de audio para la comparación, de manera que los fragmentos de referencia a ser comparados tengan valores de frecuencia de formantes coincidentes para al menos dos frecuencias de los formantes;
evaluar la similitud de dichos fragmentos de referencia a ser comparados mediante la comparación de las frecuencias de los formantes restantes, en el que dichos fragmentos de referencia a ser comparados coinciden si sus frecuencias de los formantes restantes coinciden dentro de una desviación predeterminada,
en el que la similitud de las grabaciones de audio es reconocida si todos los fragmentos de referencia comparados coinciden.
2. Procedimiento según la reivindicación 1, en el que las frecuencias de los formantes en cada uno de los fragmentos de referencia seleccionados se calculan como valores medios durante los intervalos de tiempo de duración fija en los que las frecuencias de los formantes son relativamente invariables.
3. Procedimiento según la reivindicación 1, en el que se seleccionan y se comparan fragmentos de referencia en los que los valores de frecuencia para los dos primeros formantes coinciden, en el que los valores de frecuencia para los dos primeros formantes están dentro de un límite predeterminado de variabilidad típica de los valores de frecuencia de los formantes para el tipo correspondiente de fonemas de vocal en un idioma determinado.
4. Procedimiento según la reivindicación 1, en el que al menos dos fragmentos de referencia de la señal de voz son seleccionados para la comparación a partir de las grabaciones de audio, en el que los al menos dos fragmentos de referencia están relacionados con sonidos de una articulación de diferencia máxima con los valores de frecuencia máximo y mínimo para una grabación de audio determinada.
5. Procedimiento según cualquiera de las reivindicaciones 1-4, en el que,
antes de calcular los valores de las frecuencias de los formantes, el espectro de potencia de la señal de voz para cada grabación de audio es sometido a filtrado inverso,
en el que se calcula el promedio temporal para cada componente de frecuencia del espectro de potencia, al menos para fragmentos particulares de la grabación de audio, y a continuación
el valor original del espectro de potencia de la señal de la grabación de audio es dividido por su valor inverso medio para cada componente de frecuencia del espectro.
6. Procedimiento según cualquiera de las reivindicaciones 1-4, en el que,
antes de calcular los valores de las frecuencias de los formantes, el espectro de potencia de la señal de voz para cada grabación de audio es sometido a filtrado inverso,
en el que se calcula el promedio temporal para cada componente de frecuencia del espectro de potencia, al menos para fragmentos individuales de la grabación de audio, y a continuación
los espectros son sometidos a una etapa de cálculo de logaritmo, y el valor de logaritmo promedio del espectro de potencia de la señal de la grabación de audio para cada componente de frecuencia es restado de su logaritmo del valor original.
Patentes similares o relacionadas:
Método y sistema para verificación de orador, del 20 de Mayo de 2020, de BEIJING DIDI INFINITY TECHNOLOGY AND DEVELOPMENT CO., LTD: Un método de verificación de orador, que comprende: adquirir una grabación de audio; extraer señales de voz de la grabación de audio; extraer características […]
Procedimiento para verificar la identidad de un orador y medio legible por ordenador y ordenador relacionados, del 12 de Octubre de 2016, de AGNITIO, S.L.: Procedimiento para verificar la identidad de un orador en base a la voz de oradores, que comprende las etapas de: a) recibir una expresión de voz de una palabra o una […]
 Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz, del 3 de Diciembre de 2013, de UNIVERSIDAD DE LAS PALMAS DE GRAN CANARIA: Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz.
La presente […]
Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz, del 3 de Diciembre de 2013, de UNIVERSIDAD DE LAS PALMAS DE GRAN CANARIA: Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz.
La presente […]
Detección de falsificación por cortar y pegar por alineamiento temporal dinámico, del 27 de Noviembre de 2013, de AGNITIO, S.L.: Procedimiento para comparar expresiones de voz, comprendiendo el procedimiento las etapas de: extraer una pluralidad de rasgos de una primera expresión […]
Estimación de la fiabilidad del reconocimiento de un orador, del 12 de Octubre de 2016, de AGNITIO, S.L.: Procedimiento para estimar la fiabilidad de un resultado de un sistema de reconocimiento de un orador respecto a un audio de prueba o una impresión de […]