Cálculo de máscara de escalado selectivo basado en detección de pico.
Un aparato que descodifica una señal de audio, que comprende:
un descodificador de vector de ganancia de un descodificador de capa de mejora que recibe un vector de audioreconstruido S y un índice representativo de un vector de ganancia,
en donde un selector de ganancia deldescodificador de vector de ganancia recibe el índice representativo del vector de ganancia;
un selector de ganancia del descodificador de vector de ganancia que detecta un conjunto de picos en el vectorde audio reconstruido, genera una máscara de escalado Ψ ( Š ) basada en el conjunto de picos detectados, ygenerar el vector de ganancia g* en base a al menos la máscara de escalado y el índice representativo del vectorde ganancia;
una unidad de escalado del descodificador de vector de ganancia que escala el vector de audio reconstruido conel vector de ganancia para producir una señal de audio reconstruida escalada.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/US2009/066627.
Solicitante: Motorola Mobility LLC .
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 600 North US Highway 45 Libertyville, IL 60048 ESTADOS UNIDOS DE AMERICA.
Inventor/es: ASHLEY,JAMES P, MITTAL,UDAR.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L19/14
PDF original: ES-2430414_T3.pdf
Fragmento de la descripción:
Cálculo de máscara de escalado selectivo basado en detección de pico Referencia a las solicitudes relacionadas La presente solicitud está relacionada con las siguientes solicitudes de patente europeas de propiedad común junto con esta solicitud por Motorola, Inc.: Solicitud EP 2 382 621 A0, titulada “METHOD AND APPARATUS FOR GENERATING AN ENHANCEMENT LAYER WITHIN A MULTIPLE-CHANNEL AUDIO CODING SYSTEM”; Solicitud EP 2 382 627 A0, titulada “SELECTIVE SCALING MASK COMPUTATION BASED ON PEAK DETECTION”; y Solicitud EP 2 382 622 A0, titulada “METHOD AND APPARATUS FOR GENERATING AN ENHANCEMENT LAYER WITHIN A MULTIPLE-CHANNEL AUDIO CODING SYSTEM”
Campo de la descripción La presente invención se refiere, en general, a sistemas de comunicación y, más particularmente, a codificar señales de habla y audio en tales sistemas de comunicación.
Antecedentes La compresión de señales de habla y audio es bien conocida. Se requiere generalmente compresión para transmitir señales eficientemente sobre un canal de comunicaciones, o para almacenar señales comprimidas en un dispositivo de medios digital, tal como un dispositivo de memoria de estado sólido o disco duro de ordenador. Aunque hay muchas técnicas de compresión (o “codificación”) , un método que ha permanecido muy popular para codificación de habla digital se conoce como Predicción Lineal Excitada de Código (CELP) , que es uno de una familia de algoritmos de codificación de “análisis por síntesis”. Análisis por síntesis se refiere de manera general a un proceso de codificación por el cual se usan múltiples parámetros de un modelo digital para sintetizar un conjunto de señales candidatas que se comparan con una señal de entrada y analizan para distorsión. Un conjunto de parámetros que producen la distorsión más baja entones o bien se transmiten o bien se almacenan, y eventualmente se usan para reconstruir una estimación de la señal de entrada original. CELP es un método de análisis por síntesis particular que usa uno o más libros de códigos cada uno que comprende esencialmente conjuntos de vectores de código que se recuperan del libro de códigos en respuesta a un índice de libro de códigos.
En los codificadores CELP modernos, hay un problema con el mantenimiento de una reproducción de habla y audio de elevada calidad a tasas de datos razonablemente bajas. Esto es verdadero especialmente para música u otras señales de audio genéricas que no cumplen muy bien el modelo de habla CELP. En este caso, el desajuste del modelo puede causar una calidad de audio severamente degradada que puede ser inaceptable para un usuario final del equipo que emplea tales métodos. Por lo tanto, sigue habiendo una necesidad de mejorar el rendimiento de los codificadores de habla tipo CELP a tasas de bit bajas, especialmente para música y otras entradas no de tipo habla.
Un documento de la técnica anterior en el campo de la codificación de habla/audio es RAMPRASHAD S A: “A two stage hybrid embedded speach/audio coding structure” PROCESAMIENTO ACÚSTICO, DE HABLA Y SEÑAL, 1998. ACTAS DE LA CONFERENCIA INTERNACIONAL DEL IEEE DE 1998 EN SEATTLE, WA, EE.UU. 12 – 15 DE MAYO DE 1998, NUEVA YORK, NY, EE.UU., IEEE, US, vol. 1, 12 de mayo de 1998 () , páginas 337-340, XP010279163 ISBN: 978-0-7803-4428-0.
Los objetivos antes mencionados se resuelven por las reivindicaciones de la presente invención.
Breve descripción de los dibujos Las figuras anexas, donde números de referencia iguales se refieren a elementos idénticos o de similar funcionalidad en todas las vistas separadas, las cuales junto con la descripción detallada de más adelante se incorporan en y forman parte de la especificación y sirven para ilustrar además diversas realizaciones de conceptos que incluyen la invención reivindicada, y para explicar diversos principios y ventajas de esas realizaciones.
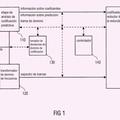
La FIG. 1 es un diagrama de bloques de un sistema de compresión de habla/audio integrado de la técnica anterior.
La FIG. 2 es un ejemplo más detallado del codificador de capa de mejora de la FIG. 1
La FIG. 3 es un ejemplo más detallado del codificador de capa de mejora de la FIG. 1
La FIG. 4 es un diagrama de bloques de un codificador y descodificador de capa de mejora.
La FIG. 5 es un diagrama de bloques de un sistema de codificación integrado de múltiples capas.
La FIG. 6 es un diagrama de bloques de un codificador y descodificador de capa 4.
La FIG. 7 es un diagrama de flujo que muestra la operación de los codificadores de la FIG. 4 y la FIG. 6.
La FIG. 8 es un diagrama de bloques de un sistema de compresión de habla/audio integrado de la técnica anterior.
La FIG. 9 es un ejemplo más detallado del codificador de capa de mejora de la FIG. 8.
La FIG. 10 es un diagrama de bloques de un codificador y descodificador de capa de mejora, según diversas realizaciones.
La FIG. 11 es un diagrama de bloques de un codificador y descodificador de capa de mejora, según diversas realizaciones.
La FIG. 12 es un diagrama de flujo de codificación de señal de audio de múltiples canales, según diversas realizaciones.
La FIG. 13 es un diagrama de flujo de codificación de señal de audio de múltiples canales, según diversas realizaciones.
La FIG. 14 es un diagrama de flujo de descodificación de una señal de audio de múltiples canales, según diversas realizaciones.
La FIG. 15 es un gráfico de frecuencia de detección de pico basado en generación de máscara, según diversas realizaciones.
La FIG. 16 es un gráfico de frecuencia de escalado de capa central que usa generación de máscara pico, según diversas realizaciones.
Las FIG. 17-19 son diagramas de flujo que ilustran la metodología para codificar y descodificar usando generación de máscara basada en detección de pico, según diversas realizaciones.
Los expertos apreciarán que los elementos en las figuras se ilustran por simplicidad y claridad y no han sido dibujados necesariamente a escala. Por ejemplo, las dimensiones de algunos de los elementos en las figuras pueden estar exageradas con respecto a otros elementos para ayudar a mejorar la compresión de diversas realizaciones. Además, la descripción y los dibujos no requieren necesariamente el orden ilustrado. Se apreciará además que se pueden describir o representar ciertas acciones y/o pasos en un orden particular de aparición aunque los expertos en la técnica entenderán que tal especificidad con respecto a la secuencia no se requiere realmente. Los componentes del aparato y método se han representado donde sea adecuado mediante símbolos convencionales en los dibujos, mostrando solamente aquellos detalles específicos que son pertinentes para la comprensión de las diversas realizaciones para no oscurecer la descripción con detalles que serán fácilmente evidentes a aquellos expertos en la técnica que tienen el beneficio de la descripción de la presente memoria. De esta manera, se apreciará que por simplicidad y claridad de ilustración, elementos comunes y bien conocidos que son útiles o necesarios en una realización comercialmente factible pueden no estar representados a fin de facilitar una visión menos obstruida de estas diversas realizaciones.
Descripción detallada A fin de abordar la necesidad anteriormente mencionada, se describe en la presente memoria un método y aparato para generar una capa de mejora dentro de un sistema de codificación de audio. Durante la operación se recibe y codifica una señal de entrada a ser codificada para producir una señal de audio codificada. La señal de audio codificada entonces se escala con una pluralidad de valores de ganancia para producir una pluralidad de señales de audio codificadas escaladas, cada una que tiene un valor de ganancia asociado y se determina que existen una pluralidad de valores de error entre la señal de entrada y cada una de la pluralidad de señales de audio codificadas escaladas. Se elige entonces un valor de ganancia que está asociado con una señal de audio codificada escalada provocando un valor de error bajo que existe entre la señal de entrada y la señal de audio codificada escalada. Finalmente, el valor de error bajo se transmite junto con el valor de ganancia como parte de una capa de mejora a la señal de audio codificada.
Un sistema de compresión de habla/audio integrado de la técnica anterior se muestra en la FIG. 1. El audio de entrada s (n) se procesa en primer lugar por un codificador de capa central 120, que para estos propósitos puede ser un algoritmo de codificación de habla de tipo CELP. El flujo de bits codificado se transmite al canal 125, además de ser introducido... [Seguir leyendo]
Reivindicaciones:
1. Un aparato que descodifica una señal de audio, que comprende:
un descodificador de vector de ganancia de un descodificador de capa de mejora que recibe un vector de audio reconstruido S y un índice representativo de un vector de ganancia, en donde un selector de ganancia del descodificador de vector de ganancia recibe el índice representativo del vector de ganancia;
un selector de ganancia del descodificador de vector de ganancia que detecta un conjunto de picos en el vector de audio reconstruido, genera una máscara de escalado ) ( Sˆ ) basada en el conjunto de picos detectados, y generar el vector de ganancia g* en base a al menos la máscara de escalado y el índice representativo del vector de ganancia;
una unidad de escalado del descodificador de vector de ganancia que escala el vector de audio reconstruido con el vector de ganancia para producir una señal de audio reconstruida escalada.
2. El aparato de la reivindicación 1, que además comprende: un descodificador de señal de error que genera una mejora al vector de audio reconstruido; y un combinador de señal del descodificador de capa de mejora que combina la señal de audio reconstruida
escalada y la mejora al vector de audio reconstruido para generar una señal descodificada mejorada.
3. El aparato de la reivindicación 1, en donde el selector de ganancia detecta el conjunto de picos según una función de detección de picos dada como:
donde ! es un valor umbral.
4. El aparato de la reivindicación 1, en donde la señal de audio está integrada en múltiples capas.
5. El aparato de la reivindicación 1, en donde el vector de audio reconstruido S está en el dominio de la frecuencia y el conjunto de picos son picos en el dominio de la frecuencia.
6. El aparato de la reivindicación 1, que además comprende:
un descodificador que recibe una señal de audio codificada, un factor de equilibrio codificado y un valor de ganancia codificado;
en donde el descodificador de vector de ganancia de un descodificador de capa de mejora que genera un valor de ganancia descodificado a partir del valor de ganancia descodificado;
en donde la unidad de escalado del descodificador de capa de mejora que escala la señal de audio codificada con el valor de ganancia descodificado para generar una señal de audio escalada; y
que además comprende:
un combinador de señal que aplica el factor de equilibrio codificado a la señal de audio escalada para generar una señal de audio de múltiples canales descodificada y saca la señal de audio de múltiples canales descodificada.
7. Un método para descodificar una señal de audio, el método que comprende:
recibir un vector de audio reconstruido Sˆ y un índice representativo de un vector de ganancia;
detectar un conjunto de picos en el vector de audio reconstruido;
generar una máscara de escalado ) ( Sˆ ) basada en el conjunto de picos detectados; generar el vector de ganancia g* basado en al menos la máscara de escalado y el índice representativo del vector de ganancia; y
escalar el vector de ganancia reconstruido con el vector de ganancia para producir una señal de audio reconstruida escalada.
8. El método de la reivindicación 7, que además comprende: 20
generar una mejora al vector de audio reconstruido; y combinar la señal de audio reconstruida escalada y la mejora al vector de audio reconstruido para generar una señal descodificada mejorada.
9. El método de la reivindicación 7, en donde detectar el conjunto de picos además comprende una función de detección de picos dada como:
donde ! es un valor umbral.
10. El método de la reivindicación 7, que además comprende: recibir una señal de audio codificada, un factor de equilibrio codificado y un valor de ganancia codificado; generar un valor de ganancia descodificado a partir del valor de ganancia codificado; escalar la señal de audio codificada con el valor de ganancia descodificado para generar una señal de audio
escalada;
aplicar un factor de equilibrio codificado a la señal de audio escalada para generar una señal de audio de múltiples canales descodificada; y sacar la señal de audio de múltiples canales descodificada.
11. Un método para codificar una señal de audio, el método que comprende: recibir una señal de audio; codificar la señal de audio para generar un vector de audio reconstruido S;
detectar un conjunto de picos en el vector de audio reconstruido Sˆ de una señal de audio recibida;
generar una máscara de escalado ) ( Sˆ ) basada en el conjunto de picos detectados;
generar una pluralidad de vectores de ganancia gj basados en la máscara de escalado;
escalar el vector de audio reconstruido con la pluralidad de vectores de ganancia para producir la pluralidad de señales de audio reconstruidas escaladas; generar una pluralidad de distorsiones basadas en la señal de audio y una pluralidad de señales de audio
reconstruidas escaladas; elegir un vector de ganancia de la pluralidad de vectores de ganancia en base a la pluralidad de distorsiones; y sacar para al menos uno de transmisión y almacenamiento el índice representativo del vector de ganancia.
12. El método de la reivindicación 11, en donde el vector de ganancia se elige que corresponda con una distorsión mínima de la pluralidad de distorsiones.
13. El método de la reivindicación 11, en donde detectar el conjunto de picos además comprende una función de detección de picos dada como:
donde ! es un valor umbral.
14. El método de la reivindicación 11, en donde la señal de audio está integrada en múltiples capas. 21
15. El método de la reivindicación 11, en donde el vector de audio reconstruido Sˆ está en el dominio de la frecuencia y el conjunto de picos son picos en el dominio de la frecuencia.
Patentes similares o relacionadas:
Decodificación de audio estéreo paramétrico, del 9 de Enero de 2019, de DOLBY INTERNATIONAL AB: Receptor, que comprende: un demultiplexor para desmultiplexar un flujo de bits para obtener una señal mono y parámetros de amplitud estéreo; […]
Receptor y método para decodificar flujo de datos codificado estéreofónico paramétrico, del 20 de Septiembre de 2017, de DOLBY INTERNATIONAL AB: Receptor, que comprende: un demultiplexor configurado para extraer una señal monofónica codificada y parámetros de amplitud estereofónica […]
Método de codificación, método de descodificación, codificador, descodificador, programa y medio de grabación, del 29 de Marzo de 2017, de NIPPON TELEGRAPH AND TELEPHONE CORPORATION: Un método de codificación de voz o de señales acústicas que comprende adquirir códigos correspondientes a residuos de predicción obtenidos según […]
Dispositivo de codificación de sonido y procedimiento de codificación de sonido, del 25 de Enero de 2017, de III Holdings 12, LLC: Un aparato de codificación de voz que comprende: una sección de análisis de parámetro de predicción que calcula una diferencia de retardo y una relación […]
 Codificador y decodificador de audio para codificar tramas de señales de audio muestreadas, del 2 de Febrero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio adaptado para codificar tramas de una señal de audio muestreada para obtener tramas codificadas, en el que una […]
Codificador y decodificador de audio para codificar tramas de señales de audio muestreadas, del 2 de Febrero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio adaptado para codificar tramas de una señal de audio muestreada para obtener tramas codificadas, en el que una […]
Codificador y descodificador de audio para codificar y descodificar muestras de audio, del 6 de Enero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio para codificar muestras de audio, que comprende: un primer codificador de introducción de distorsión por repliegue del espectro […]
Códec de audio sin pérdidas escalable y herramienta de autoría, del 6 de Mayo de 2015, de DTS, INC: Un método para codificar un flujo de bits sin pérdidas escalable para muestras de audio de PCM de M-bits para decodificar mediante un decodificador sin […]
Codificador de extensión de ancho de banda, descodificador de extensión de ancho de banda y vocoder de fase, así como métodos correspondientes y programa de computadora, del 25 de Marzo de 2015, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de extensión de ancho de banda para codificar una señal de audio , la señal de audio que comprende una señal […]