CODIFICACION DE AUDIO CON DIFERENTES LONGITUDES DE TRAMA DE CODIFICACION.
Procedimiento para soportar una codificación de una señal de audio,
en el que al menos una sección de dicha señal de audio va a codificarse con un modelo de codificación que permite la utilización de diferentes longitudes de trama de codificación, comprendiendo dicho procedimiento:
- determinar al menos un parámetro de control en base a, al menos parcialmente, características de señal de dicha señal de audio;
- limitar dichas opciones de longitudes de trama de codificación posibles para dicha al menos una sección mediante dicho al menos un parámetro de control; y
- en caso de que haya más de una opción de longitudes de trama de codificación posibles después de dicha limitación, seleccionar una longitud de trama de codificación para dicha sección a partir de dichas opciones limitadas
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/IB2004/001585.
Solicitante: NOKIA CORPORATION.
Nacionalidad solicitante: Finlandia.
Dirección: KEILALAHDENTIE 4,02150 ESPOO.
Inventor/es: MAKINEN, JARI.
Fecha de Publicación: .
Fecha Concesión Europea: 10 de Febrero de 2010.
Clasificación Internacional de Patentes:
- G10L19/02B
Clasificación PCT:
- G10L19/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › utilizando análisis espectrales, p. ej. codificadores vocales de transformación o codificadores vocales subbanda.
Clasificación antigua:
- G10L19/02 G10L 19/00 […] › utilizando análisis espectrales, p. ej. codificadores vocales de transformación o codificadores vocales subbanda.
Fragmento de la descripción:
Codificación de audio con diferentes longitudes de trama de codificación.
Campo de la invención
La invención se refiere a un procedimiento para soportar una codificación de una señal de audio, en el que al menos una sección de dicha señal de audio va a codificarse con un modelo de codificación que permite la utilización de diferentes longitudes de trama de codificación. La invención también se refiere a un módulo correspondiente, a un dispositivo electrónico correspondiente, a un sistema correspondiente y a un producto de programa de software correspondiente.
Antecedentes de la invención
Se conoce la codificación de señales de audio para permitir una transmisión y/o un almacenamiento eficaz de señales de audio.
Una señal de audio puede ser una señal de voz u otro tipo de señal de audio, tal como música, y para diferentes tipos de señales de audio pueden ser apropiados diferentes modelos de codificación.
Una técnica utilizada ampliamente para la codificación de señales de voz es la codificación de predicción lineal excitada por código algebraico (ACELP). La ACELP modela el sistema de producción de voz humana y es muy adecuada para codificar la periodicidad de una señal de voz. Como resultado, puede conseguirse una gran calidad de voz con velocidades binarias muy bajas. La banda ancha adaptable a múltiples velocidades (AMR-WB), por ejemplo, es un códec de voz basado en la tecnología ACELP. La AMR-WB está descrita, por ejemplo, en la especificación técnica 3GPP TS 26.190: "Speech Codec speech processing functions; AMR Wideband speech codec; Transcoding functions", V5.1.0 (2001-12). Sin embargo, los códecs de voz basados en el sistema de producción de voz humana no funcionan normalmente de manera óptima para otros tipos de señales de audio, tales como música.
Una técnica utilizada ampliamente para la codificación de señales de audio distintas a la voz es la codificación por transformada (TCX). La superioridad de la codificación por transformada para señales de audio se basa en un enmascaramiento perceptivo y en una codificación en el dominio de frecuencia. La calidad de la señal de audio resultante puede mejorarse adicionalmente seleccionando una longitud de trama de codificación adecuada para la codificación por transformada. Pero aunque las técnicas de codificación por transformada dan como resultado una alta calidad para señales de audio distintas a la voz, su rendimiento no es bueno para señales de voz periódicas. Por lo tanto, la calidad de la voz codificada por transformada es normalmente bastante baja, especialmente con longitudes de trama TCX largas.
El códec AMR-WB extendido (AMR-WB+) codifica una señal de audio estéreo como una señal mono de una alta velocidad binaria y proporciona una cierta cantidad de información conexa para una extensión estéreo. El códec AMR-WB+ utiliza tanto codificación ACELP como modelos TCX para codificar la señal mono principal en una banda de frecuencia de 0 Hz a 6400 Hz. Para el modelo TCX se utiliza una longitud de trama de codificación de 20 ms, de 40 ms o de 80 ms.
Puesto que un modelo ACELP puede degradar la calidad de audio y la codificación por transformada no tiene normalmente un funcionamiento óptimo para la voz, especialmente cuando se utilizan largas tramas de codificación, debe seleccionarse el mejor modelo de codificación respectivo. La selección del modelo de codificación que vaya a utilizarse finalmente puede llevarse a cabo de varias maneras.
En sistemas que requieren técnicas poco complejas, tales como los servicios multimedia móviles (MMS), normalmente se utilizan algoritmos de clasificación de música/voz para seleccionar el modelo de codificación óptimo. Estos algoritmos clasifican toda la señal fuente como música o como voz basándose en un análisis de la energía y de la frecuencia de la señal de audio.
Si una señal de audio consiste solamente en voz o solamente en música, será satisfactorio utilizar el mismo modelo de codificación para toda la señal en base a tal clasificación de música/voz. Sin embargo, en muchos otros casos, la señal de audio que va a codificarse es un tipo mixto de señal de audio. Por ejemplo, la voz puede estar presente al mismo tiempo que la música y/o alternarse con música en la señal de audio.
En estos casos, una clasificación de todas las señales fuente en la categoría de música o en la categoría de voz es un enfoque muy limitado. La conmutación entre los modelos de codificación durante la codificación de la señal de audio solo puede maximizar entonces la calidad de audio global. Es decir, el modelo ACELP también se utiliza en parte para codificar una señal fuente clasificada como una señal de audio en lugar de voz, mientras que el modelo TCX también se utiliza en parte para una señal fuente clasificada como una señal de voz.
El códec AMR-WB extendido (AMR-WB+) también está diseñado para codificar tales tipos mixtos de señales de audio con modelos de codificación mixtos trama a trama.
La selección de los modelos de codificación en AMR-WB+ puede llevarse a cabo de varias maneras.
En el enfoque más complejo, la señal se codifica en primer lugar con todas las posibles combinaciones de modelos ACELP y TCX. A continuación, la señal se sintetiza de nuevo para cada combinación. Después se selecciona la mejor excitación en base a la calidad de las señales de voz sintetizadas. La calidad de la voz sintetizada generada mediante una combinación específica puede medirse, por ejemplo, determinando su relación de señal a ruido (SNR). Este tipo de enfoque de análisis por síntesis proporciona buenos resultados. Sin embargo, en algunas aplicaciones no es factible debido a su gran complejidad. La complejidad se debe en gran parte a la codificación ACELP, que es la parte más compleja de un codificador.
En sistemas como MMS, por ejemplo, el enfoque de análisis por síntesis en bucle cerrado es demasiado complejo de realizar. Por lo tanto, en un codificador MMS se utiliza un procedimiento en bucle abierto poco complejo para determinar si se selecciona un modelo de codificación ACELP o un modelo TCX para codificar una trama particular.
La AMR-WB+ ofrece dos enfoques diferentes de bucle abierto poco complejos para seleccionar el modelo de codificación respectivo para cada trama. Ambos enfoques de bucle abierto evalúan las características de señal fuente y los parámetros de codificación para seleccionar un modelo de codificación respectivo.
En el primer enfoque de bucle abierto, una señal de audio se divide en primer lugar dentro de cada trama en varias bandas de frecuencia y se analiza la relación entre la energía en las bandas de frecuencia inferiores y la energía en las bandas de frecuencia superiores, así como las variaciones de nivel de energía en esas bandas. Después, el contenido de audio en cada trama de la señal de audio se clasifica como un contenido de música o como un contenido de voz en base a las dos mediciones realizadas o a las diferentes combinaciones de estas mediciones utilizando diferentes ventanas de análisis y valores umbral de decisión.
En el segundo enfoque de bucle abierto, que también se denomina como refinamiento de clasificación de modelo, la selección del modelo de codificación se basa en una evaluación de la periodicidad y en las propiedades estacionarias del contenido de audio en una trama respectiva de la señal de audio. La periodicidad y las propiedades estacionarias se evalúan más específicamente determinando parámetros de correlación, de predicción a largo plazo (LTP) y mediciones de la distancia espectral.
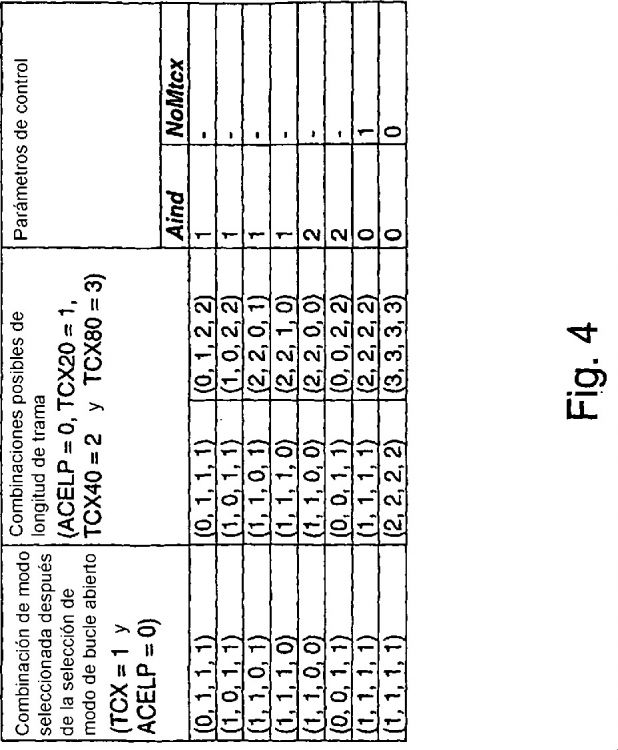
Si las propiedades de señal se analizan con un enfoque de bucle abierto para seleccionar ACELP o TCX, y se selecciona TCX para la codificación, todavía es necesario definir si se utilizará una la longitud de trama TCX de 20 ms, de 40 ms o de 80 ms. Sin embargo, es muy difícil seleccionar la longitud de trama óptima para TCX en base a las características de señal en un enfoque de bucle abierto.
Por lo tanto, es posible seleccionar solamente las longitudes de trama TCX en el enfoque de análisis por síntesis mencionado anteriormente. Sin embargo, en sistemas que requieren técnicas poco complejas, el enfoque de análisis por síntesis es demasiado complejo, incluso si solo se utiliza para la selección de las longitudes de trama TCX.
El documento US 2004/0088160 AI se refiere a la codificación de audio digital utilizando un modelo psicoacústico avanzado. Una unidad de conmutación de ventana...
Reivindicaciones:
1. Procedimiento para soportar una codificación de una señal de audio, en el que al menos una sección de dicha señal de audio va a codificarse con un modelo de codificación que permite la utilización de diferentes longitudes de trama de codificación, comprendiendo dicho procedimiento:
2. Procedimiento según la reivindicación 1, que comprende además determinar el dicho al menos un parámetro de control en base a al menos uno de los siguientes parámetros:
3. Procedimiento según la reivindicación 1 ó 2, que comprende además:
4. Procedimiento según la reivindicación 3, en el que una longitud de trama de codificación que dé como resultado la sección mejor descodificada se determina comparando una relación de señal a ruido resultante para cada una de dichas longitudes de trama de codificación.
5. Procedimiento según la reivindicación 4, en el que para dicha relación de señal a ruido de una señal de audio obtenida con una longitud de trama de codificación particular, en primer lugar se determina por separado una relación de señal a ruido segmentaria para una pluralidad de subtramas en una trama de codificación respectiva, y en el que posteriormente se calcula la media de dichas relaciones de señal a ruido segmentarias de dichas subtramas de una trama de codificación para toda la trama de codificación para obtener dicha relación de señal a ruido para dicha al menos una sección.
6. Procedimiento según al menos una de las reivindicaciones anteriores, que comprende además una etapa para determinar para cada sección de dicha señal de audio, en base a características de señal de audio para una sección respectiva, si va a utilizarse dicho modelo de codificación u otro modelo de codificación, en el que dicho al menos un parámetro de control comprende una indicación de las secciones para las que se ha seleccionado dicho otro modelo de codificación.
7. Procedimiento según la reivindicación 6, en el que dicho modelo de codificación es un modelo de codificación por transformada y en el que dicho otro modelo de codificación es un modelo de codificación de predicción lineal excitada por código algebraico.
8. Procedimiento según la reivindicación 6 ó 7, en el que cada sección de dicha señal de audio tiene una longitud predeterminada y en el que dicha indicación de las secciones para las que se ha seleccionado dicho otro modelo de codificación se proporciona para una supersección respectiva que comprende un número predeterminado de dichas secciones.
9. Procedimiento según al menos una de las reivindicaciones anteriores, en el que cada sección de dicha señal de audio tiene una longitud predeterminada, en el que un número predeterminado de secciones consecutivas, respectivamente, forman una supersección respectiva, y en el que dichas opciones de longitud de trama de codificación para una sección particular están limitadas por los límites de la supersección a la que pertenece dicha sección.
10. Procedimiento según la reivindicación 7, en el que cada sección de dicha señal de audio tiene una longitud de 20 ms, en el que cuatro secciones consecutivas, respectivamente, forman una supersección, en el que dicho modelo de codificación por transformada permite la utilización de longitudes de trama de codificación de 20 ms, 40 ms y 80 ms, y en el que dichas opciones de longitud de trama de codificación para una sección está limitadas por los límites de la supersección a la que pertenece dicha sección.
11. Procedimiento según al menos una de las reivindicaciones anteriores, en el que dicho al menos un parámetro de control comprende un indicador que indica si va a utilizarse una longitud de trama de codificación más corta o más larga, donde una indicación de que va a utilizarse una longitud de trama de codificación más corta excluye al menos la opción de longitud de trama de codificación más larga y una indicación de que va a utilizarse una longitud de trama de codificación más larga excluye al menos la opción de longitud de trama de codificación más corta.
12. Componente (10, 11) para soportar una codificación de una señal de audio, en el que al menos una sección de dicha señal de audio va a codificarse con un modelo de codificación que permite la utilización de diferentes longitudes de trama de codificación, comprendiendo dicho componente:
13. Componente (10, 11) según la reivindicación 12, en el que dicha parte (12, 13) de selección de parámetro está adaptada para determinar dicho al menos un parámetro de control en base a al menos uno de los siguientes parámetros:
14. Componente (10, 11) según la reivindicación 12 ó 13, en el que dicha parte (14) de selección de longitud de trama está adaptada además para codificar dicha al menos una sección con cada una de dichas longitudes de trama de codificación restantes, en caso de que haya más de una opción de longitudes de trama de codificación posibles después de dicha limitación, para descodificar de nuevo dichas secciones codificadas con la trama de codificación utilizada respectivamente y para seleccionar para dicha al menos una sección una longitud de trama de codificación que dé como resultado la señal de audio mejor descodificada en dicha al menos una sección.
15. Componente (10, 11) según la reivindicación 14, en el que dicha parte (14) de selección de longitud de trama está adaptada para determinar una longitud de trama de codificación que dé como resultado la sección mejor descodificada comparando una relación de señal a ruido resultante para cada una de dichas longitudes de trama de codificación.
16. Componente (10, 11) según la reivindicación 15, en el que para determinar dicha relación de señal a ruido de una señal de audio obtenida con una longitud de trama de codificación particular, dicha parte (14) de selección de longitud de trama está adaptada para determinar en primer lugar una relación de señal a ruido segmentaria por separado para una pluralidad de subtramas en una trama de codificación respectiva, y para obtener la media de dichas relaciones de señal a ruido segmentarias de dichas subtramas de una trama de codificación para toda la trama de codificación para obtener dicha relación de señal a ruido para dicha al menos una sección.
17. Componente (10, 11) según al menos una de las reivindicaciones 12 a 16, en el que dicha parte (12, 13) de selección de parámetro está adaptada además para determinar al menos para algunas secciones de una señal de audio, en base a características de señal de audio para una sección respectiva de dicha señal de audio, si va a utilizarse dicho modelo de codificación u otro modelo de codificación y para proporcionar como uno de dicho al menos un parámetro de control una indicación de las secciones para las que se ha seleccionado dicho otro modelo de codificación.
18. Componente (10, 11) según la reivindicación 17, en el que dicho modelo de codificación es un modelo de codificación por transformada y en el que dicho otro modelo de codificación es un modelo de codificación de predicción lineal excitada por código algebraico.
19. Componente (10, 11) según la reivindicación 17 o 18, en el que cada sección de dicha señal de audio tiene una longitud predeterminada y en el que dicha parte (12, 13) de selección de parámetro está adaptada para proporcionar una indicación de las secciones para las que se ha seleccionado dicho otro modelo de codificación para una supersección respectiva que comprende un número predeterminado de dichas secciones.
20. Componente (10, 11) según una de las reivindicaciones 12 a 19, en el que cada sección de dicha señal de audio tiene una longitud predeterminada, en el que un número predeterminado de secciones consecutivas, respectivamente, forman una supersección respectiva, y en el que dicha parte (14) de selección de longitud de trama está adaptada para limitar las opciones de longitud de trama de codificación para una sesión particular basándose en los límites de la supersección a la que pertenece dicha sección.
21. Componente (10, 11) según la reivindicación 20, en el que cada sección de dicha señal de audio tiene una longitud de 20 ms, en el que cuatro secciones consecutivas, respectivamente, forman una supersección, en el que dicho modelo de codificación por transformada permite la utilización de longitudes de trama de codificación de 20 ms, 40 ms y 80 ms, y en el que dicha parte (14) de selección de longitud de trama está adaptada para limitar las opciones de longitud de trama de codificación para una sección basándose en los límites de la supersección a la que pertenece dicha sección.
22. Componente (10, 11) según una de las reivindicaciones 12 a 21, en el que dicha parte (12, 13) de selección de parámetro está adaptada para proporcionar como uno de dicho al menos un parámetro de control un indicador que indica si va a utilizarse una longitud de trama de codificación más corta o más larga, donde una indicación de que va a utilizarse una longitud de trama de codificación más corta excluye al menos la opción de longitud de trama de codificación más larga y una indicación de que va a utilizarse una longitud de trama de codificación más larga excluye al menos la opción de longitud de trama de codificación más corta.
23. Dispositivo (1) electrónico que comprende un componente (10, 11) según una de las reivindicaciones 12 a 21.
24. Dispositivo (1) electrónico según la reivindicación 23, que comprende además medios para transmitir tramas codificadas.
25. Sistema (1, 2) de codificación de audio que comprende un componente (10, 11) según al menos una de las reivindicaciones 12 a 18 y un descodificador (20) para descodificar señales de audio que se han codificado con longitudes de trama de codificación variables.
26. Sistema (1, 2) de codificación de audio según la reivindicación 25, que comprende además determinar al menos un parámetro de control en base a, al menos parcialmente, características de señal de dicha señal de audio.
27. Sistema (1, 2) de codificación de audio según la reivindicación 25, que comprende además limitar dichas opciones de longitudes de trama de codificación posibles mediante dicho al menos un parámetro de control.
28. Sistema (1, 2) de codificación de audio según al menos una de las reivindicaciones 26 y 27, que comprende además
29. Un código de software para soportar una codificación de una señal de audio, en el que al menos una sección de dicha señal de audio va a codificarse con un modelo de codificación que permite la utilización de diferentes longitudes de trama de codificación, realizando dicho código de software el procedimiento según una de las reivindicaciones 1 a 11 cuando se ejecuta en un componente (11) de procesamiento de un codificador (10).
30. Un producto de programa de software en el que está almacenado un código de software según la reivindicación 29.
Patentes similares o relacionadas:
BANCO DE FILTROS DE ANÁLISIS, BANCO DE FILTROS DE SÍNTESIS, CODIFICADOR, DESCODIFICADOR, MEZCLADOR Y SISTEMA DE CONFERENCIA, del 13 de Febrero de 2012, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Banco de filtros de síntesis para filtrar una pluralidad de tramas de entrada, comprendiendo cada trama de entrada M valores de entrada ordenados yk ,...,yk(M-1), […]
CODIFICACIÓN POR TRANSFORMADA, UTILIZANDO VENTANAS DE PONDERACIÓN Y CON RETARDO PEQUEÑO, del 10 de Junio de 2011, de FRANCE TELECOM: Método de decodificación, por transformada, de una señal representada por una sucesión de tramas que han sido codificadas utilizando al […]
 METODOS Y DISPOSICIONES PARA UN EMISOR Y RECEPTOR DE CONVERSACION/AUDIO, del 11 de Agosto de 2010, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un emisor de audio/conversación que comprende un codificador de núcleo adaptado a una banda de frecuencia de una señal de audio/conversación […]
METODOS Y DISPOSICIONES PARA UN EMISOR Y RECEPTOR DE CONVERSACION/AUDIO, del 11 de Agosto de 2010, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un emisor de audio/conversación que comprende un codificador de núcleo adaptado a una banda de frecuencia de una señal de audio/conversación […]
PROCEDIMIENTO PARA LA TRASMISION DE SEÑALES DE AUDIO SEGUN EL PROCEDIMEINTO DE TRANSMISION DE PIXELS SEGUN PRIORIDAD, del 18 de Mayo de 2010, de T-MOBILE DEUTSCHLAND GMBH: Procedimiento para la transmisión de señales de audio entre un transmisor y, como mínimo, un receptor, mediante un método de transmisión de píxels según priorización, […]
 APARATO Y METODO PARA GENERAR VALORES DE SUBBANDA DE AUDIO Y APARATO YMETODO PARA GENERAR MUESTRAS DE AUDIO DE DOMINIO DE TIEMPO, del 10 de Noviembre de 2009, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Aparato para generar valores de subbanda de audio en canales de subbanda de audio, que comprende: un divisor en ventanas de análisis para dividir en ventanas una trama […]
APARATO Y METODO PARA GENERAR VALORES DE SUBBANDA DE AUDIO Y APARATO YMETODO PARA GENERAR MUESTRAS DE AUDIO DE DOMINIO DE TIEMPO, del 10 de Noviembre de 2009, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Aparato para generar valores de subbanda de audio en canales de subbanda de audio, que comprende: un divisor en ventanas de análisis para dividir en ventanas una trama […]
Aparato de codificación de señal de audio, dispositivo de decodificación de señal de audio y métodos del mismo, del 15 de Julio de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato de codificación de señal de audio, que comprende: un transformador de tiempo-frecuencia que genera un espectro que comprende realizar […]
Sistema de filtro que comprende un convertidor de filtro y un compresor de filtro y método de funcionamiento del sistema de filtro, del 15 de Julio de 2020, de DOLBY INTERNATIONAL AB: Compresor de filtro para generar respuestas a los impulsos del filtro de subbanda comprimida de las respuestas a los impulsos del filtro de subbanda […]
Aparato, método y programa informático para decodificar una señal de audio codificada, del 8 de Julio de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Aparato para decodificar una señal de audio codificada que comprende una señal central codificada y datos paramétricos , que comprende: un decodificador […]