SUPRESIÓN DE LA ACTUALIZACIÓN DE UN REGISTRO DEL HISTÓRICO DE RAMIFICACIONES POR RAMIFICACIONES DE FIN DE BUCLE.
Procedimiento de predicción de ramificación, caracterizado porque comprende la supresión de una actualización de un Registro de Histórico de Ramificación (BHR) durante la ejecución de una instrucción de ramificación,
en respuesta a la determinación de que la instrucción de ramificación es una instrucción de ramificación de fin de bucle
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/US2006/006531.
Solicitante: QUALCOMM INCORPORATED.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 5775 MOREHOUSE DRIVE SAN DIEGO, CA 92121 ESTADOS UNIDOS DE AMERICA.
Inventor/es: RYCHLIK,BOHUSLAV.
Fecha de Publicación: .
Fecha Solicitud PCT: 24 de Febrero de 2006.
Fecha Concesión Europea: 29 de Septiembre de 2010.
Clasificación Internacional de Patentes:
- G06F9/32B6
- G06F9/38E2D
- G06F9/38F2B
Clasificación PCT:
- G06F9/38 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 9/00 Disposiciones para el control por programa, p. ej. unidades de control (control por programa para dispositivos periféricos G06F 13/10). › Ejecución simultánea de instrucciones, p. ej. segmentación, anticipación.
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia, Ex República Yugoslava de Macedonia, Albania.
Fragmento de la descripción:
Antecedentes
La presente invención se refiere generalmente al campo de los procesadores y en particular a un procedimiento para mejorar la predicción de ramificaciones suprimiendo la actualización de un registro del histórico de ramificaciones por una instrucción de ramificaciones de fin de bucle.
Los microprocesadores llevan a cabo tareas computacionales en una amplia variedad de aplicaciones. La prestación mejorada de los procesadores es casi siempre deseable, para permitir un funcionamiento más rápido y/o una mayor funcionalidad a través de los cambios de software. En muchas aplicaciones integradas, tales como dispositivos electrónicos portátiles, conservar la energía es también un objetivo den la implementación y diseño de los procesadores.
Muchos procesadores de módem emplean arquitectura canalizada donde se ejecutan instrucciones secuencias, teniendo cada una múltiples etapas de ejecución. Para un rendimiento mejorado, las instrucciones deberían fluir continuamente a través de la línea de ensamble. Cualquier situación que hace que las instrucciones pierdan velocidad en la línea de ensamble puede influir negativamente sobre el rendimiento. Si las instrucciones se descartan de la línea de ensamble y a continuación se vuelven a extraer, sufren tanto el rendimiento como el consumo de energía.
La mayoría de los programas incluyen instrucciones de ramificación condicional, cuyo propio comportamiento de ramificación es desconocido hasta que se evalúa la instrucción tarde en la línea de ensamble. Para evitar la pérdida de velocidad que se produciría de la espera de la propia evaluación de la instrucción de ramificación, los procesadores módem pueden emplear alguna forma de predicción de ramificación, con lo cual el comportamiento de ramificación de las instrucciones de ramificación condicional se predice pronto en la línea de ensamble. Basado en la evaluación de ramificación predicha, el procesador extrae especulativamente (preextrae) y ejecuta instrucciones de una dirección predicha – bien la dirección diana de ramificación (si se predice que se ha de tomar la ramificación) o la siguiente dirección secuencia después de la instrucción de ramificación (si se predice que la ramificación no se ha de tomar). Cuando se determina el propio comportamiento de ramificación, si la ramificación se ha predicho erróneamente, las instrucciones extraídas de manera especulativa se deben descartar de la línea de ensamble, y se extraen nuevas instrucciones de la siguiente dirección correcta. Preextraer instrucciones en respuesta a una predicción de ramificación errónea puede incidir negativamente sobre el rendimiento y el consumo de energía del procesador. En consecuencia, mejorar la precisión de la predicción de ramificación es un objetivo importante de diseño.
Las técnicas conocidas de predicción de ramificación incluyen tanto predicciones estáticas como dinámicas. El probable comportamiento de algunas instrucciones de ramificación se puede predecir estáticamente mediante un programador y/o un compilador. Un ejemplo de predicción de ramificación es una rutina de verificación de errores. Comúnmente el código ejecuta apropiadamente, y los errores son raros. De este modo, la instrucción de ramificación que ejecuta una función “ramificación en error” evaluará “no tomada” un porcentaje muy elevado del tiempo. Tal instrucción puede incluir un bit de predicción de ramificación estática en el código operacional, establecido por un programador o compilador con conocimiento del resultado más probable de la condición de ramificación.
La predicción dinámica se basa generalmente en el histórico de evaluación de ramificación (y en algunos casos el histórico de precisión de predicción de ramificación) de la instrucción de ramificación que se está prediciendo y/o otras instrucciones de ramificación en el mismo código. El análisis exhaustivo del propio código indica que modelos de evaluación de ramificaciones en un pasado reciente pueden ser un buen indicador de la evaluación de futuras instrucciones de ramificación.
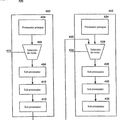
Una forma conocida de predicción de ramificación dinámica, representada en la figura 1 utiliza un Registro de Histórico de Ramificaciones (BHR) 100 para poner en memoria las n pasadas evaluaciones de ramificación. En una ejecución sencilla, el BHR 30 comprende un registro de desplazamiento. El resultado de evaluación de ramificación más reciente se desplaza en (por ejemplo, un 1 que indica una ramificación tomada y un 0 que indica una ramificación no tomada), con la evaluación más antigua en el registro desplazada. Un procesador puede mantener un BHR local 100 para cada instrucción de ramificación. Alternativamente (o adicionalmente), un BHR 100 puede contener las evaluaciones de pasado reciente de todas las instrucciones de ramificación condicional, a veces conocidas en la técnica como BHR global, o GHR. Tal como se usa en la presente memoria descriptiva, BHR se refiere tanto a registros del histórico de ramificaciones locales como globales.
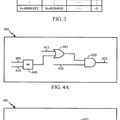
Tal como se representa en la figura 1, el BHR 100 puede indexar una Tabla de Predictor de Ramificación (BPT), que de nuevo puede ser local o global. El BHR puede indexar la BPT 102 directamente, o se puede combinar con otra información, tal como el Contador de Programa (PC) de la instrucción de ramificación en la lógica de índice BPT 104. Se pueden utilizar adicionalmente otras entradas en la lógica de índice BPT 102. La lógica de índice BPT 104 puede concatenar las entradas (comúnmente conocidas en la técnica como gselect), aplicar la función XOR a las entradas (gshare), llevar a cabo una función hash o combinar o transformar las entradas de varias maneras.
A modo de ejemplo, la BPT 102 puede comprender una pluralidad de contadores de saturación, cuyos MSBs sirven de predictores de tramificaciones bimodales. Por ejemplo, cada entrada de tabla puede comprender un contador de 2 bits que asume uno de cuatro estados, cada uno asignado a un valor de predicción ponderado, tal como
11 –predicho fuertemente tomado
10. predicho débilmente tomado
01. predicho débilmente no tomado
00 –predicho fuertemente no tomado
El contador se incrementa cada vez que una instrucción correspondiente de ramificación evalúa “tomado” y se reduce cada vez que la instrucción evalúa “no tomado”. El MSB del contador es un predicor de ramificación bimodal; predecirá que una rama sea tomada o no tomada, sin tener en cuenta la fuerza o el peso de la predicción subyacente. Un contador de saturación reduce el error de predicción de una evaluación de ramificación infrecuente. Una ramificación que evalúa consistentemente de una manera saturará el contador. Una evaluación infrecuente de la otra manera alterará el valor de contador (y la fuerza, de la predicción) pero no el valor de predicción bimodal. De este modo una evaluación infrecuente solamente predecirá erróneamente una vez, no dos. La tabla de contadores de saturación es un ejemplo ilustrativo solamente; en general, una BHT puede indexar una tabla que contiene varios mecanismos de predicción de ramificaciones.
Con independencia del mecanismo empleado de predicción de ramificación en la BPT 102, el BHR 100, bien solo o en combinación con otra información tal como el PC de instrucción de ramificación – indexa la BPT 102 para obtener predicciones de ramificación. Poniendo en memoria las evaluaciones de ramificación anteriores en el BHR 100 y usando las evaluaciones en la predicción de ramificación, la instrucción de ramificación predica se correlaciona con el comportamiento pasado de ramificaciones – su propio comportamiento pasado en el caso de un BHR local 100 y el comportamiento de otras instrucciones de ramificación en el caso de un BHR global 100. Esta correlación puede ser la clave para precisar predicciones de ramificación, al menos en el caso de un código altamente repetitivo.
Obsérvese que la figura 1 representa evaluaciones de ramificaciones puestas en memoria en el BHR 100, es decir, la propia evaluación de una instrucción de ramificación condicional, que solamente se puede conocer tarde en la línea de ensamble, tal como en una etapa de línea de ejecución. Mientras este es el resultado final, en la práctica, muchos procesadores de alto rendimiento memorizan la evaluación de ramificación predicha a partir de la BPT 102 en el BHR 100, y corrigen el BHR 100 más tarde como parte de una operación de...
Reivindicaciones:
1. Procedimiento de predicción de ramificación, caracterizado porque comprende la supresión de una actualización de un Registro de Histórico de Ramificación (BHR) durante la ejecución de una instrucción de ramificación, en respuesta a la determinación de que la instrucción de ramificación es una instrucción de ramificación de fin de bucle.
2. Procedimiento según la reivindicación 1, en el cual la etapa de determinación comprende asumir que una ramificación hacia atrás es una ramificación de fin de bucle.
3. Procedimiento según la reivindicación 1, en el cual el PC de la instrucción de ramificación coincide con el contenido de un registro de PC de Última Ramificación (LBPC) que pone en memoria el PC de la última instrucción de instrucciones de ramificación para actualizar el BHR (30).
4. Procedimiento según la reivindicación 3, en el cual el PC de la instrucción de ramificación coincide con el contenido de cualquiera de una pluralidad de registros LBPC (38) que pone en memoria los PC de la última pluralidad de instrucciones de ramificación para actualizar el BHR (30).
5. Procedimiento según la reivindicación 1, en el cual la etapa de determinación comprende la determinación de que la instrucción de ramificación es una instrucción de ramificación única generada por una compilador para terminar ramificaciones o que la instrucción de ramificación incluye uno o más bits que indican que es una instrucción de ramificación de fin de bucle.
6. Procedimiento según cualquier reivindicación que comprende, además, la determinación de una ramificación de fin de bucle.
7. Procesador (10) que comprende:
un predictor de ramificación (26) operativo para predecir la evaluación de instrucciones de ramificación coadicional;
una línea de ensamble (12) de ejecución de instrucciones operativa para extraer y ejecutar de manera especulativa instrucciones basadas en una predicción procedente del predictor de ramificación; un Registro de Histórico de Ramificación (BHR) operativo para poner en memoria la evaluación de instrucciones de ramificación condicional; y caracterizado por:
un circuito de control operativo para suprimir la puesta en memoriza de la evaluación de una instrucción de ramificación condicional en respuesta a la determinación de que la instrucción de ramificación es una instrucción de ramificación de fin de bucle.
8. Procesador según la reivindicación 7 que comprende, además, un registro de Última Ramificación (LBPC) (38) operativo para poner en memoria el PC de una instrucción de ramificación que actualiza el BHR (30), y en el cual el circuito de control es operativo para suprimir la puesta en memoria de la evaluación de una instrucción de ramificación condicional si el PC de la instrucción de ramificación coincide con el contenido del registro LBPC (38).
9. Procesador según la reivindicación 8, que comprende, además, una pluralidad de registros LBPC (38) operativos para poner en memoria los PC de una pluralidad de instrucciones de ramificación que actualizan el BHR (30), y en el cual el circuito de control es operativo para suprimir la puesta en memoria de la evaluación de una instrucción de ramificación condicional si el PC de la instrucción de ramificación coincide con el contenido de cualquier registro LBPC (38)
10. Procesador según la reivindicación 7, en el cual el circuito de control es operativo para suprimir la puesta en memoria de la evaluación de una instrucción de ramificación condicional si la instrucción de ramificación comprende una indicación de que es una instrucción de fin de bucle u operativo para suprimir la puesta en memoria de la evaluación de una instrucción de ramificación condicional si la dirección diana de la instrucción de ramificación es inferior al PC de la instrucción de ramificación.
11. El procesador según la reivindicación 10 en el cual la indicación de que la instrucción de ramificación es una instrucción de fin de bucle es el tipo de instrucción.
Patentes similares o relacionadas:
 METODOS Y APARATO PARA LA EJECUCION MULTIPROCESO DE INSTRUCCIONES INFORMATICAS, del 9 de Diciembre de 2009, de SONY COMPUTER ENTERTAINMENT INC.: Un sistema informático multiproceso, que comprende: un procesador principal operable para gestionar el procesado de bucles de instrucciones […]
METODOS Y APARATO PARA LA EJECUCION MULTIPROCESO DE INSTRUCCIONES INFORMATICAS, del 9 de Diciembre de 2009, de SONY COMPUTER ENTERTAINMENT INC.: Un sistema informático multiproceso, que comprende: un procesador principal operable para gestionar el procesado de bucles de instrucciones […]
 PROCEDIMIENTO Y APARATO PARA RECONOCER UNA LLAMADA A UNA SUBRUTINA, del 11 de Febrero de 2011, de QUALCOMM INCORPORATED: Un procedimiento de reconocimiento de una llamada a una subrutina, que comprende: la detección de un cambio no secuencial en el flujo de un programa; […]
PROCEDIMIENTO Y APARATO PARA RECONOCER UNA LLAMADA A UNA SUBRUTINA, del 11 de Febrero de 2011, de QUALCOMM INCORPORATED: Un procedimiento de reconocimiento de una llamada a una subrutina, que comprende: la detección de un cambio no secuencial en el flujo de un programa; […]
Control de ejecución de hilos en un procesador multihilo, del 24 de Junio de 2020, de INTERNATIONAL BUSINESS MACHINES CORPORATION: Un método para controlar la ejecución de hilos en un entorno informático, comprendiendo dicho método: detener , mediante un hilo […]
Arquitectura e instrucciones flexibles para el estándar de cifrado avanzado (AES), del 27 de Mayo de 2020, de INTEL CORPORATION: Un procesador que comprende: una pluralidad de núcleos; una caché de instrucciones de nivel 1, L1, para almacenar una pluralidad de instrucciones […]
Predicados uniformes en sombreadores para unidades de procesamiento de gráficos, del 11 de Diciembre de 2019, de QUALCOMM INCORPORATED: Un procedimiento para procesar datos, comprendiendo el procedimiento: recibir una indicación de que todos los subprocesos de una urdimbre […]
Aumento de protocolo de coherencia para indicar estado de transacción, del 4 de Diciembre de 2019, de INTERNATIONAL BUSINESS MACHINES CORPORATION: Un método implementado por ordenador para implementar un protocolo de coherencia, comprendiendo el método: enviar , por un procesador (112a) solicitante, […]
Método y aparato para un acceso a memoria basado en hilos en un procesador multihilo, del 11 de Septiembre de 2019, de QUALCOMM INCORPORATED: Método para acceder a una memoria por un procesador multihilo , comprendiendo el método: determinar un identificador de hilo asociado a un […]
Procedimientos y aparatos para predecir la no ejecución de instrucciones de no bifurcación condicional, del 15 de Mayo de 2019, de QUALCOMM INCORPORATED: Un procedimiento para manejar una instrucción de no bifurcación condicional, que comprende: identificar una instrucción […]