Sistema de reconocimiento conductual.
Un procedimiento para procesar un flujo de tramas de vídeo que registra sucesos dentro de una escena,
comprendiendo el procedimiento:
recibir una primera trama del flujo (210, 215), en el que la primera trama incluye datos para una pluralidad de píxeles incluidos en la trama;
identificar uno o más grupos de píxeles en la primera trama, en el que cada grupo representa un objeto dentro de la escena (225);
generar un modelo de búsqueda que almacena una o más características asociadas con cada objeto identificado;
clasificar cada uno de los objetos usando un clasificador entrenado (235);
rastrear, en una segunda trama, cada uno de los objetos identificados en la primera trama usando el modelo de búsqueda (230);
suministrar la primera trama, la segunda trama y las clasificaciones de objetos a un motor de aprendizaje automático; y
generar, por el motor de aprendizaje automático, una o más representaciones semánticas de conducta en la que toman parte los objetos en la escena a lo largo de una pluralidad de tramas (245), en el que el motor de aprendizaje automático está configurado para aprender patrones de conducta observada en la escena a lo largo de la pluralidad de tramas (255) y para identificar apariciones de los patrones de conducta en la que toman parte los objetos clasificados (260).
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/US2008/053457.
Solicitante: BEHAVIORAL RECOGNITION SYSTEMS, INC.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 2100 WEST LOOP S., 9TH FLOOR HOUSTON, TX 77027 ESTADOS UNIDOS DE AMERICA.
Inventor/es: YANG,Tao, EATON,JOHN ERIC, COBB,WESLEY KENNETH, URECH,DENNIS GENE, BLYTHE,BOBBY ERNEST, FRIEDLANDER,DAVID SAMUEL, GOTTUMUKKAL,RAJKIRAN KUMAR, RISINGER,LON WILLIAM, SAITWAL,KISHOR ADINATH, SEOW,MING-JUNG, SOLUM,DAVID MARVIN, XU,GANG.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F15/18
PDF original: ES-2522589_T3.pdf


Fragmento de la descripción:
Sistema de reconocimiento conductual Antecedentes de la invención Campo de la invención
La presente invención se refiere, en general, al análisis de vídeo, y más en particular a analizar y aprender una conducta en base a la generación de una corriente de datos de vídeo.
Descripción de la técnica relacionada
Algunos sistemas de vídeo vigilancia actualmente disponibles tienen unas capacidades de reconocimiento simples. No obstante, muchos sistemas de vigilancia de este tipo requieren un conocimiento avanzado (antes de que se haya desarrollado un sistema) de las acciones y / o los objetos que los sistemas han de ser capaces de buscar. Debe desarrollarse un código de aplicación subyacente dirigido a conductas "anormales" específicas para que estos sistemas de vigilancia sean operativos y lo bastante funcionales. Dicho de otra forma, a menos que el código subyacente al sistema incluya descripciones de determinadas conductas, el sistema será incapaz de reconocer tales conductas. Además, para conductas distintas, a menudo es necesario desarrollar unos productos de soporte lógico independientes. Esto hace que los sistemas de vigilancia con capacidades de reconocimiento sean laboriosos y prohibitivamente costosos. Por ejemplo, supervisar entradas de aeropuertos en busca de criminales al acecho e identificar nadadores que no se están moviendo en una piscina son dos situaciones distintas y, por lo tanto, pueden requerir el desarrollo de dos productos de soporte lógico distintos que tengan sus respectivas conductas "anormales" previamente codificadas.
Los sistemas de vigilancia también pueden diseñarse para memorizar escenas normales y generar una alarma siempre que cambie lo que se considera normal. No obstante, estos tipos de sistemas de vigilancia han de estar preprogramados para saber cuánto de anormal es el cambio. Además, tales sistemas no pueden caracterizar con precisión lo que ha tenido lugar en realidad. En su lugar, estos sistemas determinan que algo previamente considerado "normal" ha cambiado. Por lo tanto, los productos desarrollados de tal forma están configurados para detectar solo un margen limitado de un tipo previamente definido de conducta.
El documento W26 / 12645 describe un sistema sensitivo que combina detección, rastreo y visualización envolvente de un entorno atestado y abarrotado, tal como un edificio de oficinas, una terminal, u otro sitio cerrado usando una red de cámaras estereoscópicas. Un vigilante supervisa el sitio usando un modelo en 3D en directo, que se actualiza a partir de diferentes direcciones usando los múltiples flujos de vídeo.
Sumario de la invención
Realizaciones de la presente invención proporcionan un procedimiento y un sistema para analizar y aprender una conducta basándose en un flujo adquirido de tramas de vídeo. Los objetos representados en el flujo se determinan basándose en un análisis de las tramas de vídeo. Cada objeto puede tener un modelo de búsqueda correspondiente, que se usa para rastrear los movimientos de los objetos trama a trama. Se determinan las clases de los objetos y se generan representaciones semánticas de los objetos. Las representaciones semánticas se usan para determinar las conductas de los objetos y para aprender acerca de conductas que tienen lugar en un entorno representado por los flujos de vídeo adquiridos. De esta forma, el sistema aprende con rapidez y en tiempo real conductas normales y anormales para cualquier entorno mediante el análisis de movimientos o actividades o ausencia de las mismas en el entorno e identifica y predice una conducta anormal y sospechosa basándose en lo que se ha aprendido.
Una realización particular de la invención incluye un procedimiento para procesar un flujo de tramas de vídeo que registran sucesos dentro de una escena. El procedimiento puede incluir en general recibir una primera trama del flujo. La primera trama incluye datos para una pluralidad de píxeles incluidos en la trama. El procedimiento puede incluir además identificar uno o más grupos de píxeles en la primera trama. Cada grupo representa un objeto dentro de la escena. El procedimiento puede incluir todavía adicionalmente generar un modelo de búsqueda que almacena una o más características asociadas con cada objeto identificado, clasificar cada uno de los objetos usando un clasificador entrenado, rastrear, en una segunda trama, cada uno de los objetos identificados en la primera trama usando el modelo de búsqueda, y suministrar la primera trama, la segunda trama y las clasificaciones de objeto a un motor de aprendizaje automático. El procedimiento puede incluir todavía adicionalmente generar, por el motor de aprendizaje automático, una o más representaciones semánticas de conducta en la que toman parte los objetos en la escena a lo largo de una pluralidad de tramas. El motor de aprendizaje automático puede configurarse en general para aprender patrones de conducta observada en la escena a lo largo de la pluralidad de tramas y para identificar apariciones de los patrones de conducta en la que toman parte los objetos clasificados.
Breve descripción de los dibujos
Para que la forma en la que las características, ventajas y objetos que se han enunciado en lo que antecede de la
presente invención se obtengan y puedan entenderse con detalle, una descripción más particular de la invención, que se ha resumido brevemente en lo que antecede, puede tenerse por referencia a las realizaciones que se ilustran en los dibujos adjuntos.
Ha de observarse, no obstante, que los dibujos adjuntos ilustran solo realizaciones típicas de la presente invención y, por lo tanto, no han de considerarse limitantes de su ámbito, ya que la invención puede admitir otras realizaciones igualmente eficaces.
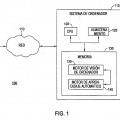
La figura 1 es un diagrama de bloques de alto nivel de un sistema de reconocimiento de conducta, de acuerdo con una realización de la presente invención.
La figura 2 ¡lustra un diagrama de flujo de un procedimiento para analizar y aprender una conducta basándose en un flujo de tramas de vídeo, de acuerdo con una realización de la presente Invención.
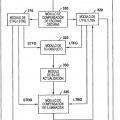
La figura 3 ¡lustra un módulo de segundo plano - primer plano de un motor de visión de ordenador, de acuerdo con una realización de la presente invención.
La figura 4 ¡lustra un módulo para rastrear objetos de interés en un motor de visión de ordenador, de acuerdo con una realización de la presente invención.
La figura 5 ¡lustra un módulo de estimador / identificador de un motor de visión de ordenador, de acuerdo con una realización de la presente invención.
La figura 6 ¡lustra un componente de procesador de contexto de un motor de visión de ordenador, de acuerdo con una realización de la presente invención.
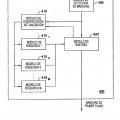
La figura 7 ¡lustra un módulo de análisis semántico de un motor de aprendizaje automático, de acuerdo con una realización de la presente invención.
La figura 8 ¡lustra un módulo de percepción de un motor de aprendizaje automático, de acuerdo con una realización de la presente invención.
Las figuras 9A-9C ilustran una secuencia de unas tramas de vídeo en la que un sistema de reconocimiento de conducta detecta una conducta anormal y emite una alerta, de acuerdo con una realización de la presente
invención.
Descripción detallada de las realizaciones preferentes
Los sistemas de reconocimiento de conducta de aprendizaje automático, tal como las realizaciones de la invención que se describe en el presente documento, aprenden conductas basándose en información adquirida con el tiempo. En el contexto de la presente invención, se analiza Información a partir de un flujo de vídeo (es decir, una secuencia de tramas de vídeo individuales). La presente divulgación describe un sistema de reconocimiento de conducta que aprende a identificar y distinguir entre una conducta normal y anormal dentro de una escena mediante el análisis de movimientos y / o actividades (o ausencia de las mismas) con el tiempo. Las conductas normales / anormales no están previamente definidas o son de codificación fija. En su lugar, el sistema de reconocimiento de conducta que se describe en el presente documento aprende con rapidez lo que es "normal" para cualquier entorno e identifica una conducta anormal y sospechosa basándose en lo que se aprende a través de la supervisión de la ubicación, es decir, mediante el análisis del contenido de video registrado trama a trama.
A continuación, se hace referencia a realizaciones de la Invención. No obstante, debería entenderse que la invención no se limita a realización alguna descrita de manera especifica. En su lugar, se contempla cualquier combinación de las siguientes características y elementos, ya estén... [Seguir leyendo]
Reivindicaciones:
1. Un procedimiento para procesar un flujo de tramas de vídeo que registra sucesos dentro de una escena, comprendiendo el procedimiento:
recibir una primera trama del flujo (21, 215), en el que la primera trama incluye datos para una pluralidad de pfxeles incluidos en la trama;
identificar uno o más grupos de píxeles en la primera trama, en el que cada grupo representa un objeto dentro de la escena (225);
generar un modelo de búsqueda que almacena una o más características asociadas con cada objeto identificado;
clasificar cada uno de los objetos usando un clasificador entrenado (235);
rastrear, en una segunda trama, cada uno de los objetos identificados en la primera trama usando el modelo de búsqueda (23);
suministrar la primera trama, la segunda trama y las clasificaciones de objetos a un motor de aprendizaje automático; y
generar, por el motor de aprendizaje automático, una o más representaciones semánticas de conducta en la que toman parte los objetos en la escena a lo largo de una pluralidad de tramas (245), en el que el motor de aprendizaje automático está configurado para aprender patrones de conducta observada en la escena a lo largo de la pluralidad de tramas (255) y para identificar apariciones de los patrones de conducta en la que toman parte los objetos clasificados (26).
2. El procedimiento de la reivindicación 1, que comprende además emitir al menos una alerta que indica una aparición de uno de los patrones identificados de conducta por uno de los objetos rastreados.
3. El procedimiento de la reivindicación 1, en el que cada modelo de búsqueda es generado como uno de un modelo de apariencia y un modelo basado en características.
4. El procedimiento de la reivindicación 1, en el que la etapa de rastrear, en la segunda trama, cada uno de los objetos identificados en la primera trama usando el modelo de búsqueda comprende:
ubicar los objetos identificados dentro de la segunda trama; y actualizar el modelo de búsqueda respectivo para cada objeto identificado.
5. El procedimiento de la reivindicación 1, en el que el clasificador entrenado está configurado para clasificar cada objeto como uno de un ser humano, un coche, u otro.
6. El procedimiento de la reivindicación 1, en el que la etapa de identificar uno o más grupos de píxeles en la primera trama comprende:
identificar al menos un grupo de píxeles que representan una región de primer plano de la primera trama y al menos un grupo de píxeles que representan una región de segundo plano de la primera trama; segmentar regiones de primer plano en manchas de primer plano, en el que cada mancha de primer plano representa un objeto representado en la primera trama; y
actualizar una imagen de segundo plano de la escena basándose en las regiones de segundo plano identificadas en la primera trama.
7. El procedimiento de la reivindicación 6, que comprende además:
actualizar un mapa con comentarios de la escena representada por el flujo de vídeo usando los resultados de las etapas de generar un modelo de búsqueda que almacena una o más características asociadas con cada objeto identificado;
clasificar cada uno de los objetos usando un clasificador entrenado; y
rastrear, en una segunda trama, cada uno de los objetos identificados en la primera trama usando el modelo de búsqueda, en el que el mapa con comentarios describe una geometría tridimensional de la escena que incluye una posición tridimensional estimada de los objetos identificados y una posición tridimensional estimada de una pluralidad de objetos representados en la Imagen de segundo plano de la escena, y en el que la etapa de construir representaciones semánticas comprende además analizar las representaciones semánticas construidas para patrones de conducta reconocibles usando análisis semántico latente.
8. Un sistema, que comprende:
una fuente de entrada de vídeo (15);
un procesador (12); y
una memoria (13) que almacena:
un motor de visión de ordenador (135), en el que el motor de visión de ordenador está configurado para:
recibir, a partir de la fuente de entrada de vídeo, una primera trama de un flujo de vídeo, en el que la primera trama incluye datos para una pluralidad de píxeles incluidos en la trama,
Identificar uno o más grupos de píxeles en la primera trama, en el que cada grupo representa un objeto dentro de la escena (225),
generar un modelo de búsqueda que almacena una o más características asociadas con cada objeto identificado,
clasificar cada uno de los objetos usando un clasificador entrenado (235),
rastrear, en una segunda trama, cada uno de los objetos identificados en la primera trama usando el modelo de búsqueda (23), y
suministrar la primera trama, la segunda trama y las clasificaciones de objetos a un motor de aprendizaje automático; y
el motor de aprendizaje automático, en el que el motor de aprendizaje automático está configurado para generar una o más representaciones semánticas de conducta en la que toman parte los objetos en la escena a lo largo de una pluralidad de tramas (245) y está configurado además para aprender patrones de conducta observada en la escena a lo largo de la pluralidad de tramas (255) y para identificar apariciones de los patrones de conducta en la que toman parte los objetos clasificados (26).
9. El sistema de la reivindicación 8, en el que el motor de aprendizaje automático está configurado además para emitir al menos una alerta que indica una aparición de uno de los patrones identificados de conducta por uno de los objetos rastreados.
1. El sistema de la reivindicación 8, en el que cada modelo de búsqueda es generado como uno de un modelo de apariencia y un modelo basado en características.
11. El sistema de la reivindicación 8, en el que la etapa de rastrear, en la segunda trama, cada uno de los objetos identificados en la primera trama usando el modelo de búsqueda comprende:
ubicar los objetos identificados dentro de la segunda trama; y actualizar el modelo de búsqueda respectivo para cada objeto identificado.
12. El sistema de la reivindicación 8, en el que el clasificador entrenado está configurado para clasificar cada objeto como uno de un ser humano, un coche, u otro.
13. El sistema de la reivindicación 12, en el que el clasificador entrenado está configurado además para estimar al menos uno de una postura, una ubicación, y un movimiento para al menos uno de los objetos clasificados, basándose en cambios en el grupo de píxeles que representan el objeto a lo largo de una pluralidad de tramas sucesivas.
14. El sistema de la reivindicación 8, en el que el motor de visión de ordenador está configurado para identificar el uno o más grupos de píxeles en la primera trama realizando las etapas de:
identificar al menos un grupo de píxeles que representan una región de primer plano de la primera trama y al menos un grupo de píxeles que representan una región de segundo plano de la primera trama; segmentar regiones de primer plano en manchas de primer plano, en el que cada mancha de primer plano representa un objeto representado en la primera trama; y
actualizar una imagen de segundo plano de la escena basándose en las regiones de segundo plano identificadas en la primera trama.
15. El sistema de la reivindicación 14, en el que el motor de visión de ordenador está configurado además para:
actualizar un mapa con comentarios de la escena representada por el flujo de vídeo usando los resultados de las etapas de generar un modelo de búsqueda que almacena una o más características asociadas con cada objeto identificado;
clasificar cada uno de los objetos usando un clasificador entrenado; y
rastrear, en una segunda trama, cada uno de los objetos identificados en la primera trama usando el modelo de búsqueda, en el que el mapa con comentarios describe una geometría tridimensional de la escena que incluye una posición tridimensional estimada de los objetos identificados y una posición tridimensional estimada de una pluralidad de objetos representados en la imagen de segundo plano de la escena, y en el que la etapa de construir representaciones semánticas comprende además analizar las representaciones semánticas construidas para patrones de conducta reconocibles usando análisis semántico latente.
Patentes similares o relacionadas:
PROCEDIMIENTO Y SISTEMA DE VISIÓN ARTIFICIAL PARA LA DESCRIPCIÓN Y CLASIFICACIÓN AUTOMÁTICA DE TEJIDOS NO PATOLÓGICOS DEL SISTEMA CARDIOVASCULAR HUMANO, del 2 de Octubre de 2018, de UNIVERSIDAD DE LEON: Procedimiento y sistema de visión artificial para la descripción y clasificación automática de tejidos no patológicos del sistema cardiovascular humano. Se describe […]
Sistemas y métodos de verificación y autenticación, del 24 de Febrero de 2016, de EQUIFAX, INC: Un método de controlar el acceso por un usuario a sistemas de tecnología de información de vendedor online usando un motor de verificación/autenticación, que comprende: […]
 Procedimiento de coordinación de flotas para la asistencia de eventos en entornos dinámicos, del 3 de Marzo de 2014, de UNIVERSIDAD REY JUAN CARLOS: Procedimiento de coordinación de flotas para la asistencia de eventos en entornos dinámicos, tales como servicios de emergencias médicas, bomberos […]
Procedimiento de coordinación de flotas para la asistencia de eventos en entornos dinámicos, del 3 de Marzo de 2014, de UNIVERSIDAD REY JUAN CARLOS: Procedimiento de coordinación de flotas para la asistencia de eventos en entornos dinámicos, tales como servicios de emergencias médicas, bomberos […]
 PROCEDIMIENTO DE COORDINACIÓN DE FLOTAS PARA LA ASISTENCIA DE EVENTOS EN ENTORNOS DINÁMICOS, del 6 de Febrero de 2014, de UNIVERSIDAD REY JUAN CARLOS: La invención consiste de un modelo de coordinación para cualquier tipo de servicio cuyo objetivo es atender eventos que puedan surgir de forma imprevista […]
PROCEDIMIENTO DE COORDINACIÓN DE FLOTAS PARA LA ASISTENCIA DE EVENTOS EN ENTORNOS DINÁMICOS, del 6 de Febrero de 2014, de UNIVERSIDAD REY JUAN CARLOS: La invención consiste de un modelo de coordinación para cualquier tipo de servicio cuyo objetivo es atender eventos que puedan surgir de forma imprevista […]
DISPOSITIVO DE GESTIÓN Y CONTROL DE RUTINAS CONDUCTUALES, del 13 de Marzo de 2012, de CRAMBO, S.A: Dispositivo de gestión y control de rutinas conductuales que comprende, al menos unos primeros medios de adquisición de un comportamiento o actividad […]
CODIFICADOR SENSOMOTOR ADAPTABLE PARA PROTESIS OCULAR O AUDITIVA., del 1 de Mayo de 2007, de ECKMILLER, ROLF: La invención se refiere a un codificador sensor-motor adaptativo para prótesis visuales o acústicas. El codificador tiene una unidad central de comprobación […]
METODO PARA ESTIMAR UNA MEDIDA DE LA POTENCIA DE CODIGO DE SEÑAL DE INTERFERENCIA, EQUIPO DE USUARIO Y ESTACION BASE CORRESPONDIENTE AL METODO., del 16 de Marzo de 2007, de FOSTER-MILLER, INC.: Un método para estimar una medida de la potencia de código de señal de interferencia, a la que de aquí en adelante se hará referencia como ISCP en la presente memoria, […]
 ANALISIS DE IMAGENES ASISTIDO POR ORDENADOR, del 27 de Abril de 2010, de HEALTH DISCOVERY CORPORATION: Un procedimiento implementado por ordenador para el análisis de una imagen digitalizada, comprendiendo el procedimiento:
(a) ingresar un conjunto de entrenamiento […]
ANALISIS DE IMAGENES ASISTIDO POR ORDENADOR, del 27 de Abril de 2010, de HEALTH DISCOVERY CORPORATION: Un procedimiento implementado por ordenador para el análisis de una imagen digitalizada, comprendiendo el procedimiento:
(a) ingresar un conjunto de entrenamiento […]