Sistema y método para reconocer un comando de voz de usuario en un entorno con ruido.
Sistema automático de reconocimiento de voz para reconocer un comando de voz de usuario (2) en un entorno con ruido,
que comprende:
- unos medios de concordancia para hacer concordar unos elementos recuperados a partir de unas unidades de habla que forman dicho comando, con unas plantillas de una biblioteca de plantillas (44);
- unos medios de procesado (32, 36, 38) que incluyen un Perceptrón Multicapa (38) para calcular plantillas a posteriori P(Oplantilla(q)) almacenadas como dichas plantillas en dicha biblioteca de plantillas (44);
- unos medios para recuperar unos vectores a posteriori P(Oprueba(q)) a partir de dichas unidades de habla, siendo dichos vectores a posteriori usados como dichos elementos;
- unos medios de cálculo para seleccionar automáticamente unas plantillas a posteriori almacenadas en dicha biblioteca de plantillas (44);
- caracterizado por que dichos medios de cálculo están adaptados para usar un enfoque de grafos, tal como el enfoque de Gabriel o el enfoque de vecinos relativos para la selección de dichas plantillas a posteriori a partir de unas plantillas de entrenamiento, comprendiendo dicha selección:
- determinar los vecinos de Gabriel/relativos mediante el cálculo de una matriz de distancias entre la totalidad de dichas plantillas de entrenamiento,
- visitar cada plantilla de entrenamiento,
- marcar una plantilla de entrenamiento si la totalidad de sus vecinos es de la misma clase que la plantilla de entrenamiento actual,
- eliminar todas las plantillas de entrenamiento marcadas.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2011/064588.
Solicitante: Veovox SA.
Nacionalidad solicitante: Suiza.
Dirección: Chemin des Roches 10, CP 508 1009 Pully SUIZA.
Inventor/es: MASSON, OLIVIER, DINES,JOHN, CARMONA,JORGE, ARADILLA,GUILLERMO.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L15/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad). › Extracción de características para el reconocimiento de la voz; Selección de la unidad de reconocimiento.
- G10L15/06 G10L 15/00 […] › Creación de plantillas de referencia; Entrenamiento de sistemas de reconocimiento de la voz, p. ej. adaptación a las características de la voz de la persona que habla (G10L 15/14 tiene prioridad).
- G10L15/16 G10L 15/00 […] › utilizando redes neuronales artificiales.
PDF original: ES-2540995_T3.pdf
Fragmento de la descripción:
Sistema y método para reconocer un comando de voz de usuario en un entorno con ruido.
Campo de la invención La presente invención se refiere a un método y a un sistema para introducir y reconocer comandos de voz de usuario en entornos con ruido.
Descripción de la técnica relacionada Se conocen sistemas de Reconocimiento Automático de Voz (ASR) para reconocer palabras pronunciadas de señales de audio.
El ASR se usa, por ejemplo, en centros de atención telefónica. Cuando un usuario necesita cierta información, por ejemplo la hora de salida de un tren desde una estación de ferrocarril determinada, el mismo puede solicitar oralmente la información deseada a un centro de atención telefónica utilizando un teléfono o teléfono móvil. El usuario habla y solicita información, y un sistema reconoce las palabras pronunciadas para recuperar datos. Otro ejemplo de ASR es una guía telefónica automática. Un usuario puede llamar a un número y solicitar oralmente el número de teléfono de una persona que viva en una ciudad.
En estos dos ejemplos, la voz del usuario se reconoce y se convierte en una señal eléctrica usada por un sistema para recuperar la información deseada. En ambos casos, el canal de comunicaciones entre el usuario y el sistema es conocido. Puede ser un par trenzado en el caso de un teléfono fijo o el canal del operador en el caso de un teléfono móvil. Además, el ruido del canal se puede modelar con modelos conocidos.
Por otra parte, dichas aplicaciones implican típicamente un número elevado de palabras posibles que pueden ser usadas por un hablante. Por ejemplo, el número de posibles estaciones de ferrocarril diferentes, el número de las ciudades de un país o el número de los nombres de las personas que viven en una cuidad dada es habitualmente muy elevado. No obstante, el diccionario de palabras a reconocer no requiere una actualización frecuente, ya que las mismas no cambian muy a menudo; habitualmente, cada palabra del diccionario permanece sin variaciones en este diccionario durante semanas, meses o incluso años.
Además de aquellas aplicaciones conocidas para las cuales se han desarrollado la mayoría de ASR, en ocasiones son necesarios otros ASR en entornos con ruido, tales como (sin carácter limitativo) bares, restaurantes, discotecas, hoteles, hospitales, industria del entretenimiento, tiendas de comestibles, etcétera, para coger, reconocer y transmitir pedidos por voz. Por ejemplo, resultaría útil disponer, en un bar o restaurante, de un ASR con el cual un camarero que coge pedidos de los clientes sentados en una mesa pudiera repetir cada pedido y pronunciarlo a un micrófono de un dispositivo móvil. A continuación, la señal de voz recibida desde un punto de acceso se podría convertir en comandos de texto mediante un servidor de reconocimiento de voz que ejecuta un algoritmo de reconocimiento de voz. El punto de acceso puede pertenecer a una red de área local (LAN) , a la cual se conectan otros diversos equipos, tales como el servidor.
En dichos entornos, el reconocimiento de voz resulta difícil ya que la relación de señal/ruido puede ser insuficiente. Por otra parte el ruido del entorno no es conocido y el mismo puede cambiar en función de la gente que haya en el bar o restaurante. Las palabras posibles pronunciadas por el hablante pueden ser, por ejemplo, las palabras contenidas en el menú del día. En ese caso, el número de palabras está limitado normalmente a por ejemplo, unos cuantos cientos de palabras como mucho. Por otra parte estas palabras pueden cambiar cada día - en el caso del menú del día - o, por ejemplo, cada semana o dos veces por mes. Por lo tanto, los requisitos de un sistema de reconocimiento de voz en un entorno del tipo mencionado o para una aplicación del tipo mencionado son muy diferentes con respecto a los requisitos en los que se basan la mayoría de sistemas de ASR disponibles comercialmente.
Es por lo tanto una finalidad de la presente invención desarrollar un método y un aparato de ASR nuevos que estén adaptados más adecuadamente a esos requisitos tan específicos e inhabituales (relación deficiente de señal/ruido, diccionario limitado, diccionario que varía rápidamente, precisión de reconocimiento muy alta, tiempo de respuesta inmediato, idioma de usuario, independencia con respecto a la pronunciación y el acento, robustez frente al entorno y el hablante) .
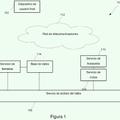
Se conocen diferentes sistemas de ASR. La Figura 1 muestra un ASR por concordancia de plantillas, que es uno de los primeros sistemas de ASR. El mismo usa ejemplos de unidades de habla como base para reconocimiento. Cada ejemplo actúa como una plantilla o secuencia de plantillas 14 para una unidad de habla o secuencia de prueba específica 12 que va a ser reconocida. Puede haber múltiples plantillas 14 para cada unidad 12 con el fin de incrementar la robustez del sistema. Habitualmente, estas unidades se representan en forma de secuencias de características espectrales a corto plazo, tales como Coeficientes Cepstrales en frecuencia Mel (MFCCs) . El Cepstrum en Frecuencia Mel (MFC) es una representación particular del espectro de potencia a corto plazo de un
sonido utilizado en el procesado del mismo. Se basa en una transformada discreta de coseno de un espectro de potencia logarítmico representado en la escala Mel de frecuencia.
Un decodificador 10 lleva a cabo una comparación entre observaciones acústicas de plantillas 140, 142, 144 y secuencias de prueba 12. La similitud acústica se deduce habitualmente a partir de medidas de la distancia entre la característica acústica de la plantilla Oplantilla y la característica acústica de la secuencia de prueba Oprueba. En el ASR convencional por concordancia de plantillas, se usa un parámetro de distancia para medir la similitud de vectores acústicos. Los parámetros de distancia adecuados se basan normalmente en la distorsión espectral. La medida de la distancia puede ser, por ejemplo, euclídea:
DE = Ioplantilla oprueba I
o Mahalanobis:
DM=. (oplantilla oprueba) TS-l (oplantilla oprueba)
en donde S representa la matriz de covarianza de los vectores acústicos.
La suposición de fondo del ASR basado en la concordancia de plantillas es que las ejecuciones de sonidos sean suficientemente similares, de tal manera que una comparación entre observaciones acústicas de plantillas correctas 14 y secuencias de prueba 12 proporcione una coincidencia relativamente buena en comparación con el cálculo de plantillas incorrectas. En el caso de un usuario dado y/o de condiciones de grabación estables, puesto que cada usuario proporciona normalmente sus propias plantillas las cuales contienen su propia pronunciación específica, el ASR basado en la concordancia de plantillas es independiente de pronunciaciones e idiomas.
En el caso de una pluralidad de usuarios y/o de condiciones de grabación diferentes, lo mencionado anteriormente en realidad no se cumple normalmente debido a posibles variaciones en la pronunciación para la misma palabra. Estas variaciones pueden ser generadas por diferencias de pronunciación entre hablantes y/o discordancias entre condiciones de grabación.
La ventaja del ASR por concordancia de plantillas es su sencillez de implementación. Por otra parte, no requiere la especificación de un diccionario de pronunciación, ya que éste está implícito en la plantilla 14. Las desventajas incluyen la sensibilidad antes mencionada a diferencias en grabaciones de plantillas/pronunciaciones de prueba en el caso de una pluralidad de usuarios y/o de condiciones de grabación diferentes. Por otra parte, el algoritmo de reconocimiento puede ser costoso desde el punto de vista computacional cuando se utiliza un número elevado de plantillas.
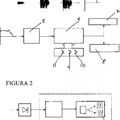
La decodificación en el ASR con concordancia de plantillas se lleva a cabo frecuentemente utilizando un decodificador de Alineamiento Dinámico Temporal (DTW) 10. El mismo implementa un algoritmo de programación dinámico que efectúa una búsqueda sobre la secuencia de prueba, donde se consideran todas las secuencias de plantillas posibles. Durante esta búsqueda se permite cierta deformación temporal de plantillas, y de aquí el aspecto de "alineamiento temporal" de este algoritmo. La plantilla reconocida q es q =argminÆDÆÆÆoplantilla (Æ) , opruebaÆ
donde DTW (·, ·) es la distancia de alineamiento dinámico temporal entre dos secuencias, la secuencia de plantillas 14 Oplantilla (q) de la biblioteca de plantillas y la secuencia de prueba 12 Oprueba .
Se ilustra un ejemplo del procedimiento de búsqueda de DTW en la Figura 2, en la que se calcula una puntuación local 16 en cada nodo del gráfico entre una secuencia de prueba 12 y la plantilla correspondiente 14. La puntuación... [Seguir leyendo]
Reivindicaciones:
1. Sistema automático de reconocimiento de voz para reconocer un comando de voz de usuario (2) en un entorno con ruido, que comprende:
- unos medios de concordancia para hacer concordar unos elementos recuperados a partir de unas unidades de habla que forman dicho comando, con unas plantillas de una biblioteca de plantillas (44) ;
- unos medios de procesado (32, 36, 38) que incluyen un Perceptrón Multicapa (38) para calcular plantillas a posteriori P (Oplantilla (q) ) almacenadas como dichas plantillas en dicha biblioteca de plantillas (44) ;
- unos medios para recuperar unos vectores a posteriori P (Oprueba (q) ) a partir de dichas unidades de habla, siendo dichos vectores a posteriori usados como dichos elementos;
- unos medios de cálculo para seleccionar automáticamente unas plantillas a posteriori almacenadas en dicha biblioteca de plantillas (44) ;
- caracterizado por que dichos medios de cálculo están adaptados para usar un enfoque de grafos, tal como el enfoque de Gabriel o el enfoque de vecinos relativos para la selección de dichas plantillas a posteriori a partir de unas plantillas de entrenamiento, comprendiendo dicha selección:
- determinar los vecinos de Gabriel/relativos mediante el cálculo de una matriz de distancias entre la totalidad de dichas plantillas de entrenamiento, -visitar cada plantilla de entrenamiento, -marcar una plantilla de entrenamiento si la totalidad de sus vecinos es de la misma clase que la plantilla de entrenamiento actual, -eliminar todas las plantillas de entrenamiento marcadas.
2. Sistema según la reivindicación 1, que comprende asimismo: un decodificador de DTW (40) para hacer concordar vectores a posteriori con plantillas a posteriori.
3. Sistema según la reivindicación 2, que comprende asimismo -un detector de actividad vocal (34, 42) ; y -un diccionario (46) .
4. Sistema según una de las reivindicaciones 1 a 3, en el que dicho Perceptrón Multicapa (38) es multilingüe.
5. Sistema según una de las reivindicaciones 1 a 3, que comprende por lo menos dos Perceptrones Multicapa (38) , siendo cada uno de dichos Perceptrones Multicapa (38) usado para un idioma específico.
6. Sistema según una de las reivindicaciones 1 a 5, en el que dicha biblioteca de plantillas (44) es una biblioteca de plantillas preexistente generada a partir de unas plantillas de entrenamiento pronunciadas por otro usuario.
7. Sistema según una de las reivindicaciones 1 a 6, que comprende unos medios para crear dicha biblioteca de plantillas (44) a partir de un diccionario de pronunciación.
8. Sistema según la reivindicación 7, en el que dichos medios comprenden un parámetro de divergencia de KL.
9. Sistema según una de las reivindicaciones 1 a 8, que comprende unos medios para adaptar automáticamente dicha biblioteca de plantillas (44) , incluyendo la adaptación la activación/desactivación y/o adición y/o eliminación y/o sustitución de dichas plantillas a posteriori.
10. Sistema según la reivindicación 9, en el que dicha adaptación usa una retroalimentación de entrada de dicho usuario (2) en un dispositivo de usuario (1) .
11. Sistema según una de las reivindicaciones 1 a 10, que comprende una gramática (48) .
12. Sistema según una de las reivindicaciones 1 a 11, que comprende unos medios de detector de actividad vocal que pueden ser seleccionados y deseleccionados por dicho usuario (2) .
13. Sistema según la reivindicación 12, en el que dicha gramática (48) es seleccionada por medio de dichos medios de detector de actividad vocal.
14. Sistema según una de las reivindicaciones 2 a 13, en el que dicho decodificador de DTW (40) incorpora una 5 penalización de inserción, un factor de escala y un silencio de filtro.
15. Sistema según una de las reivindicaciones 10 a 14, que comprende: -dicho dispositivo de usuario (1) adaptado para permitir que un usuario (2) introduzca dichos comandos de voz; -unos medios de preprocesado en dicho dispositivo de usuario (1) , adaptados para preprocesar dichos comandos de voz introducidos; -unos medios de conexión (7, 8) para transmitir unas señales preprocesadas a un servidor central (6) en un bar, 15 restaurante u hotel; -software de gestión de restaurantes, bares u hoteles (5) para gestionar pedidos de bares, restaurantes u hoteles, introducidos por dicho usuario (2) a través de dichos comandos de voz.
16. Método de reconocimiento automático de la voz para reconocer un comando de voz pronunciado por un usuario (2) en un entorno con ruido, comprendiendo dicho método:
- hacer concordar unos elementos recuperados a partir de unidades de habla que forman dicho comando, con unas plantillas de una biblioteca de plantillas (44) .
25. determinar una secuencia de plantillas que minimiza la distancia entre dichos elementos y dichas plantillas;
- siendo dichas plantillas unas plantillas a posteriori P (Oplantilla (q) ) y siendo dichos elementos recuperados a partir de unidades de habla unos vectores a posteriori P (Oprueba (q) ) ;
- siendo dichas plantillas a posteriori y dichos vectores a posteriori generados con por lo menos un Perceptrón MultiCapa (38) ;
- caracterizado por que incluye una etapa para seleccionar dichas plantillas a posteriori a partir de plantillas de 35 entrenamiento usando un enfoque de grafos, tal como el enfoque de Gabriel, o el enfoque de vecinos relativos, comprendiendo dicha etapa:
- determinar los vecinos de Gabriel/relativos mediante el cálculo de una matriz de distancias entre la totalidad de dichas plantillas de entrenamiento, -visitar cada plantilla de entrenamiento, - marcar una plantilla de entrenamiento si la totalidad de sus vecinos es de la misma clase que la plantilla de entrenamiento actual.
45. eliminar todas las plantillas de entrenamiento marcadas.
17. Método según la reivindicación 16, en el que se usa un decodificador de DTW (40) para hacer concordar vectores a posteriori con plantillas a posteriori.
18. Método según una de las reivindicaciones 16 a 17, que comprende asimismo: -introducir dichos comandos de voz correspondientes a pedidos de bares, restaurantes u hoteles en un dispositivo de usuario (1) ;
-preprocesar dichos comandos de voz en dicho dispositivo de usuario (1) ; -transmitir (7, 8) unas señales preprocesadas a un servidor (6) ; -convertir dichas señales preprocesadas en pedidos de texto en dicho servidor (6) ; -visualizar dichos pedidos de texto; -comunicar dichos pedidos a software y/o sistemas usados por dicho bar, dicho restaurante o dicho hotel.
19. Método según una de las reivindicaciones 16 a 18, que comprende asimismo:
- grabar continuamente dicho comando de voz por medio de un sistema de adquisición de audio, -seleccionar unos medios de detector de actividad vocal, -deseleccionar dichos medios de detector de actividad vocal, -procesar dicho comando de voz un tiempo antes de seleccionar dichos medios de detector de actividad vocal y un tiempo después de deseleccionar dichos medios de detector de actividad vocal.
Patentes similares o relacionadas:
Método y aparato para reconocimiento de voz automático, del 3 de Abril de 2019, de Oxford University Innovation Limited: Método de reconocimiento de voz automático, comprendiendo el método las etapas de: recibir una señal de voz , dividir la señal de voz en ventanas de tiempo, […]
SISTEMA DE IDENTIFICACIÓN DE SONIDOS MEDIANTE CLASIFICACIÓN PARAMÉTRICA DE SERIES DERIVADAS, del 17 de Mayo de 2018, de UNIVERSIDAD DE SEVILLA: La presente invención tiene por objeto un sistema de identificación de sonidos que se basa en la descripción y selección de unos pocos parámetros […]
Sistema de identificación de sonidos mediante clasificación paramétrica de series derivadas, del 11 de Mayo de 2018, de UNIVERSIDAD DE SEVILLA: La presente invención tiene por objeto un sistema de identificación de sonidos que se basa en la descripción y selección de unos pocos parámetros […]
 Sistema y método para realizar consultas textuales en comunicaciones de voz, del 6 de Enero de 2016, de JaJah Ltd: Un sistema para realizar consultas textuales en comunicaciones de voz, comprendiendo el sistema:
un servicio de índices para almacenar […]
Sistema y método para realizar consultas textuales en comunicaciones de voz, del 6 de Enero de 2016, de JaJah Ltd: Un sistema para realizar consultas textuales en comunicaciones de voz, comprendiendo el sistema:
un servicio de índices para almacenar […]
 Procedimiento y dispositivo para generar una huella digital y procedimiento y dispositivo para identificar una señal de audio, del 15 de Junio de 2012, de M2ANY GMBH: Procedimiento para generar una huella digital de una señal de audio utilizando información de modo, que define una pluralidad de modos de huella […]
Procedimiento y dispositivo para generar una huella digital y procedimiento y dispositivo para identificar una señal de audio, del 15 de Junio de 2012, de M2ANY GMBH: Procedimiento para generar una huella digital de una señal de audio utilizando información de modo, que define una pluralidad de modos de huella […]
PROCEDIMIENTO DE RECONOCIMIENTO DE VOZ., del 1 de Septiembre de 2006, de PROUS SCIENCE, S.A.: Procedimiento de reconocimiento de voz, que comprende: (a) una etapa de descomposición de una señal de voz digitalizada en una pluralidad de fracciones, (b) una etapa de representación […]
EXTRACCION ADAPTABLE DE ONDICULAS PARA RECONOCIMIENTO DE VOZ., del 16 de Octubre de 2005, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.: Método para extraer características para el reconocimiento automático de la voz, que comprende las etapas de: descomponer una señal acústica […]
 MÉTODO PARA EL RECONOCIMIENTO DE UNA SEÑAL DE SONIDO IMPLEMENTADO MEDIANTE MICROCONTROLADOR, del 17 de Marzo de 2011, de BILOOP TECNOLOGIC, S.L: Método para el reconocimiento de señales, siempre que la señal esté limitada en el tiempo y sea periódica, que comprende la obtención de la envolvente, la toma de muestras […]
MÉTODO PARA EL RECONOCIMIENTO DE UNA SEÑAL DE SONIDO IMPLEMENTADO MEDIANTE MICROCONTROLADOR, del 17 de Marzo de 2011, de BILOOP TECNOLOGIC, S.L: Método para el reconocimiento de señales, siempre que la señal esté limitada en el tiempo y sea periódica, que comprende la obtención de la envolvente, la toma de muestras […]