Procedimiento y sistema para la activación por voz de páginas web.
Un procedimiento para proporcionar páginas web visuales con una interfaz de audio,
que comprende:
recibir, en un navegador (256), primeros datos de página web transmitidos desde un servidor (102), incluyendo los primeros datos de página web:
(a) primeros componentes de marcado que describen y pueden convertirse en una primera página web visual 5 que incluye enlaces representados visualmente que pueden seleccionarse cada uno por un usuario para navegar a otra página web respectiva; y
(b) segundos componentes de marcado diferentes de los primeros componentes de marcado y que describen y pueden convertirse en una primera gramática basada en reglas generada independientemente del contenido de los primeros componentes de marcado, donde:
la primera gramática basada en reglas define para cada uno de uno o más de los enlaces una regla respectiva que incluye una parte de comando y una parte de frase;
la parte de comando define un comando que puede ejecutarse para navegar hasta otra de las páginas web respectivas correspondientes a los enlaces; y
la parte de frase identifica una pluralidad de frases alternativas que (i) no se muestran en la página web visual, (ii) no están incluidas en los enlaces y (iii) cada una, cuando se pronuncia por un usuario, invoca por separado la ejecución del comando respectivo de la regla a la que pertenece la parte de frase;
convertir los primeros componentes de marcado en la primera página web visual;
recibir una entrada de voz que incluye una frase pronunciada;
hacer corresponder la frase pronunciada con una de las frases alternativas identificadas por una de las reglas definidas por los segundos componentes de marcado; y
como respuesta a la correspondencia, navegar desde la primera página web visual hasta la página web respectiva especificada por la parte de comando de la regla que identifica la frase con la que se hizo corresponder la frase pronunciada.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E07019562.
Solicitante: THE TRUSTEES OF COLUMBIA UNIVERSITY IN THE CITY OF NEW YORK.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 16TH STREET AND BROADWAY NEW YORK, NY 10027 ESTADOS UNIDOS DE AMERICA.
Inventor/es: CHARNEY,MICHAEL L, STARREN,JUSTIN.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L15/18 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad). › utilizando una modelización del lenguaje natural.
- G10L15/26 G10L 15/00 […] › Sistemas de síntesis de texto a partir de la voz (G10L 15/08 tiene prioridad).
- H04M3/493 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04M COMUNICACIONES TELEFONICAS (circuitos para el control de otros aparatos vía cable telefónico y que no implican aparatos de conmutación telefónica G08). › H04M 3/00 Centrales automáticas o semiautomáticas. › Servicios de información interactivos, p. ej. petición de información del directorio telefónico.
PDF original: ES-2391983_T3.pdf
Fragmento de la descripción:
Procedimiento y sistema para la activación por voz de páginas web.
Antecedentes de la invención
En la pasada década, los sistemas de reconocimiento automático de voz (ASR) han evolucionado hasta el punto que puede obtenerse un alto grado de precisión de reconocimiento por parte de los sistemas ASR instalados en ordenadores personales y estaciones de trabajo de precio moderado. Esto ha dado lugar a un aumento en el número de sistemas ASR disponibles para clientes y aplicaciones industriales.
Los sistemas ASR se basan en gramáticas de voz para reconocer comandos de voz introducidos mediante un micrófono y actuar sobre tales comandos. Las gramáticas de voz se dividen en dos categorías: gramáticas basadas en reglas y gramáticas de libre expresión (free speech grammar) . Las gramáticas basadas en reglas permiten el reconocimiento de un conjunto limitado de frases predefinidas. Cada gramática basada en reglas, si se invoca, hace que se produzca un evento o conjunto de eventos. Una gramática basada en reglas se invoca si una locución, introducida con un micrófono, coincide con una plantilla de voz correspondiente a una frase almacenada en el
conjunto de frases predefinidas. Por ejemplo, el usuario puede decir “guardar archivo” cuando edita un documento en un programa de procesamiento de texto para invocar el comando ‘guardar’. Por otro lado, las gramáticas de libre expresión reconocen grandes conjuntos de palabras en un dominio dado, tal como inglés financiero. Estas gramáticas se utilizan generalmente para aplicaciones de dictado, donde algunos ejemplos de estos sistemas son Dragon Naturally Speaking e IBM Viavoice 7 Millennium. Los sistemas ASR también tienen incorporadas capacidades de conversión de texto a voz (TTS) que permiten a los sistemas ASR reproducir oralmente un texto generado gráficamente utilizando una voz sintetizada. Por ejemplo, un sistema ASR puede leer en voz alta un párrafo resaltado en un procesador de texto a través de los altavoces.
Los sistemas ASR se han integrado en los navegadores web para crear navegadores web que soportan voz; véase, por ejemplo, el documento “Grammar Representation Requirements for Voice Markup Languages”, del W3C. Los navegadores web que soportan voz permiten al usuario navegar por Internet utilizando comandos de voz que invocan gramáticas basadas en reglas. Algunos de los comandos de voz utilizados por estos navegadores incluyen locuciones que hacen que el software ejecute comandos tradicionales utilizados por los navegadores web. Por ejemplo, si el usuario dice “página de inicio” con un micrófono, un navegador que soporta voz ejecutará las mismas rutinas que el navegador web que soporta voz ejecutaría si un usuario pulsase el botón “página de inicio” del
navegador web que soporta voz. Además, algunos navegadores web que soportan voz crean gramáticas basadas en reglas en función del contenido de páginas web. Cuando una página web se descarga y se muestra, algunos navegadores web que soportan voz crean gramáticas basadas en reglas en función de los enlaces contenidos en la página web. Por ejemplo, si la página web muestra el enlace “página de inicio de la empresa”, este tipo de navegador web que soporta voz creará una gramática basada en reglas, cuando se muestra la página web, de manera que si un usuario dice la frase “página de inicio de la empresa” con un micrófono, el navegador web que soporta voz mostraría la página web asociada al enlace. Un inconveniente de este enfoque es que las reglas generadas a partir del contenido de páginas web son fijas durante largos periodos de tiempo, ya que las páginas web no se rediseñan frecuentemente. Además, las gramáticas basadas en reglas se generan a partir del contenido de páginas web, lo que está orientado principalmente a la visualización. Además, estos sistemas hacen que el usuario se limite a decir lo que aparece en la pantalla.
Las páginas web también pueden incluir elementos de audio, los cuales generan una salida de sonido. Actualmente, las páginas web pueden incorporar elementos de audio en sus páginas web de dos maneras. La primera manera de incorporar un elemento de audio es utilizar el contenido de archivos de audio wav para proporcionar una voz humana en una página web. La utilización de archivos de audio wav permite al diseñador de páginas web diseñar las partes visuales y de audio de la página web de manera independiente, pero esta libertad y funcionalidad añadida tienen un alto precio. El ancho de banda requerido para transferir archivos de sonido binarios a través de Internet al usuario final es grande. La segunda manera de incorporar un elemento de audio es incorporar la funcionalidad de un sistema ASR. Los navegadores web que soportan voz pueden utilizar la funcionalidad TTS de un sistema ASR para que el ordenador “diga” el contenido de una página web. La utilización de este enfoque hace que el ancho de banda necesario para ver la página con o sin el elemento de audio sea aproximadamente el mismo, pero limita al contenido de la página web lo que el navegador web puede decir.
VoiceXML (VXML) es otra opción para un diseñador de páginas web. VXML permite a un usuario navegar por un sitio web solamente mediante la utilización de comandos de audio utilizados normalmente con un teléfono. VXML requiere que un conversor TTS lea una página web a un usuario convirtiendo la página web visual en una expresión de audio de la página web. El usuario navega por la web diciendo los enlaces a los que el usuario desea acceder. Con este enfoque, un usuario puede navegar por Internet utilizando solamente la voz del usuario, pero el contenido de audio se genera normalmente a partir del contenido de páginas web, el cual está diseñado principalmente para una interpretación visual, eliminándose la interfaz visual de la experiencia del usuario.
Por consiguiente, existe una constante necesidad de crear de manera independiente un componente de audio de una página web que no necesite una gran cantidad de ancho de banda de transmisión y que exista junto con el componente visual de una página web.
Sumario de la invención
La presente invención se define en las reivindicaciones independientes.
Breve descripción de los dibujos
Objetos, características y ventajas adicionales de la invención resultarán evidentes a partir de la siguiente descripción detallada tomada junto con las figuras adjuntas que muestran realizaciones ilustrativas de la invención, en las que:
La FIG. 1 es un diagrama de bloques que ilustra un sistema de la técnica anterior.
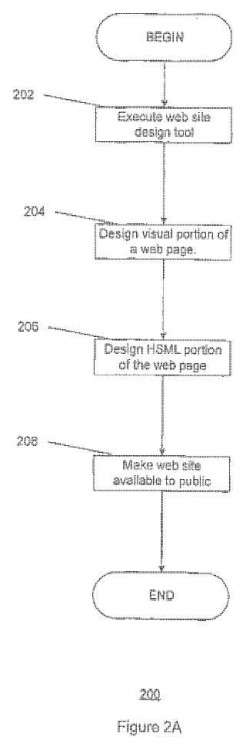
La FIG. 2A es un diagrama de flujo que ilustra un proceso de generación de contenido de páginas web según la presente invención.
La FIG. 2B es un diagrama de bloques de un sistema de navegador web que soporta un lenguaje de marcado de hipervoz (HSML) según la presente invención.
La FIG. 3A es un diagrama de flujo que ilustra un hilo (thread) que supervisa los mensajes enviados a un puerto particular de un ordenador según la presente invención.
La FIG. 3B es una tabla que ilustra las condiciones bajo las cuales una cabecera, un delimitador o un pie se añaden al principio o al final de los datos recibidos desde el servidor web según la presente invención.
La FIG. 4 es un diagrama de flujo que ilustra un hilo que recibe datos desde el navegador web y datos enviados al navegador web asociados a las páginas web que se invocaron por el navegador web según la presente invención.
La FIG. 5 es un diagrama de flujo que ilustra un hilo que es el procedimiento a través del cual el motor HSML reacciona para recibir una serie de etiquetas desde el motor ASR según la presente invención.
La FIG. 6 es un diagrama de flujo que ilustra un hilo que recibe etiquetas de subreglas desde el motor ASR y datos enviados al navegador web asociados a páginas web que se invocaron por el motor ASR según la presente invención.
La FIG. 7 es un diagrama de flujo que ilustra un proceso para crear, almacenar y transmitir gramáticas basadas en reglas y gramáticas TTS según la presente invención.
La FIG. 8 es un diagrama de flujo que ilustra un proceso para analizar sintácticamente conjuntos de bloques de gramáticas de lenguaje de marcado de hipervoz según la presente invención.
La FIG. 9 es un diagrama de flujo que ilustra... [Seguir leyendo]
Reivindicaciones:
1. Un procedimiento para proporcionar páginas web visuales con una interfaz de audio, que comprende:
recibir, en un navegador (256) , primeros datos de página web transmitidos desde un servidor (102) , incluyendo los primeros datos de página web:
(a) primeros componentes de marcado que describen y pueden convertirse en una primera página web visual que incluye enlaces representados visualmente que pueden seleccionarse cada uno por un usuario para navegar a otra página web respectiva; y
(b) segundos componentes de marcado diferentes de los primeros componentes de marcado y que describen y pueden convertirse en una primera gramática basada en reglas generada independientemente del contenido de los primeros componentes de marcado, donde:
la primera gramática basada en reglas define para cada uno de uno o más de los enlaces una regla
respectiva que incluye una parte de comando y una parte de frase; la parte de comando define un comando que puede ejecutarse para navegar hasta otra de las páginas web respectivas correspondientes a los enlaces; y
la parte de frase identifica una pluralidad de frases alternativas que (i) no se muestran en la página web visual, (ii) no están incluidas en los enlaces y (iii) cada una, cuando se pronuncia por un usuario, invoca por separado la ejecución del comando respectivo de la regla a la que pertenece la parte de frase;
convertir los primeros componentes de marcado en la primera página web visual; recibir una entrada de voz que incluye una frase pronunciada; hacer corresponder la frase pronunciada con una de las frases alternativas identificadas por una de las reglas
definidas por los segundos componentes de marcado; y como respuesta a la correspondencia, navegar desde la primera página web visual hasta la página web respectiva
especificada por la parte de comando de la regla que identifica la frase con la que se hizo corresponder la frase pronunciada. 2. El procedimiento según la reivindicación 1, en el que cada regla de la primera gramática basada en reglas incluye
además una primera parte de etiqueta que identifica de manera unívoca la regla respectiva de la primera gramática basada en reglas. 3. El procedimiento según la reivindicación 1, que comprende además: abrir una conexión al navegador (256) desde el servidor (102) ; y enviar la primera página web visual al navegador (256) a través de la conexión.
4. El procedimiento según la reivindicación 3, en el que la conexión es una conexión persistente. 5. El procedimiento según la reivindicación 4, en el que la navegación desde la primera página web visual hasta la página web respectiva incluye:
recibir segundos datos de página web desde el servidor (102) , especificando los segundos datos de página web una segunda página web visual y una segunda gramática basada en reglas asociada; y
enviar la segunda página web visual al navegador a través de la conexión. 6. El procedimiento según la reivindicación 1, en el que los primeros componentes de marcado están en forma de lenguaje de marcado de hipertexto.
7. El procedimiento según la reivindicación 1, en el que la primera gramática basada en reglas incluye una primera parte de prioridad de visualización. 8. El procedimiento según la reivindicación 1, que comprende además: proporcionar un nivel de audio de salida. 9. El procedimiento según la reivindicación 1, que comprende además: proporcionar como salida de manera audible contenido relacionado con la primera página web visual.
10. El procedimiento según la reivindicación 9, en el que la salida audible se produce como respuesta a la recepción de la entrada de voz.
11. El procedimiento según la reivindicación 1, en el que la conversión se produce en un navegador (256) .
12. El procedimiento según la reivindicación 1, en el que:
los segundos componentes de marcado se proporcionan en un lenguaje de marcado de voz;
comprendiendo además el procedimiento:
abrir una conexión entre el navegador (256) y un módulo que procesa la entrada de voz; y
enviar los primeros componentes de marcado al navegador (256) a través de la conexión; y
la primera página web visual y la página web respectiva hacia la que se navega desde la primera página web visual se muestran en el navegador (256) .
13. El procedimiento según la reivindicación 1, en el que la entrada de voz se procesa en un motor de reconocimiento automático de voz (258) .
14. El procedimiento según la reivindicación 1, en el que los primeros datos de página web incluyen datos que pueden convertirse en una primera gramática basada en voz, comprendiendo además el procedimiento proporcionar de manera audible una salida de voz basada en la primera gramática basada en voz.
15. El procedimiento según la reivindicación 14, en el que la salida audible se produce como respuesta a la entrada de voz recibida.
16. El procedimiento según la reivindicación 2, en el que:
los primeros datos de página web incluyen además terceros componentes de marcado que pueden convertirse en una gramática de voz que incluye reglas para proporcionar una salida de audio;
cada regla de la gramática de voz está asociada a una parte de etiqueta; y
una regla particular de la gramática de voz se carga en una memoria en asociación con una regla particular de la primera gramática basada en reglas mediante la utilización de una misma parte de etiqueta por parte de las reglas particulares de la gramática de voz y la primera gramática basada en reglas.
17. El procedimiento según la reivindicación 16, que comprende además:
como respuesta a la recepción, cuando la primera página web visual está activa, de una entrada de voz correspondiente a la parte de frase de la regla particular de la primera gramática basada en reglas, ejecutar el comando de la regla particular de la primera gramática basada en reglas y proporcionar como salida el audio de la regla particular de la gramática de voz.
18. El procedimiento según la reivindicación 1, que comprende además:
determinar si añadir una o más directivas a los datos de la primera página web recibidos y, si se determina que van a añadirse una o más directivas, si la una o más directivas se añaden al principio o al final, donde las determinaciones se basan en si los datos de la página web actualmente recibidos incluyen una gramática, en si los datos de una página web recibidos anteriormente incluyen una gramática, y en un procedimiento a través del cual se iniciaron los datos de la página web actualmente recibidos.
19. El procedimiento según la reivindicación 1, en el que los segundos componentes de marcado incluyen un componente que proporciona una instrucción de recarga invocada por voz para recargar la primera página web visual.
20. El procedimiento según la reivindicación 1, en el que cada una de al menos un subconjunto de reglas de la primera gramática basada en reglas incluye una etiqueta inicial, una asociación de un localizador uniforme de recursos, al menos un elemento de voz para invocar un comando y una etiqueta final.
21. El procedimiento según la reivindicación 1, en el que los componentes de gramática se proporcionan como datos binarios.
22. El procedimiento según la reivindicación 1, en el que la parte de frase identifica además una pluralidad de alternativas de entrada de voz correspondientes a variables respectivas.
23. El procedimiento según la reivindicación 1, en el que la parte de frase define además una sección de entrada de voz opcional que no afecta a la ejecución del comando respectivo de la regla que incluye la parte de frase.
24. Un sistema que proporciona páginas web visuales con una interfaz de audio, que comprende:
una disposición de entrada para recibir, desde un servidor (102) , primeros datos de página web que incluyen:
(a) primeros componentes de marcado que describen y pueden convertirse en una página web visual que incluye enlaces representados visualmente que pueden seleccionarse cada uno por un usuario para navegar a otra página web respectiva; y
(b) segundos componentes de marcado diferentes de los primeros componentes de marcado y que describen y pueden convertirse en una primera gramática basada en reglas generada independientemente del contenido de los primeros componentes de marcado, donde:
la primera gramática basada en reglas define para cada uno del uno o más de los enlaces una regla respectiva que incluye una parte de comando y una parte de frase;
la parte de comando define un comando que puede ejecutarse para navegar hasta una de las páginas web respectivas correspondientes a los enlaces; y
la parte de frase identifica una pluralidad de frases alternativas que (i) no se muestran en la página web visual, (ii) no están incluidas en los enlaces y (iii) cada una, cuando se pronuncia por un usuario, invoca por separado la ejecución del comando respectivo de la regla a la que pertenece la parte de frase;
un navegador (256) para convertir los primeros componentes de marcado en los primeros componentes de marcado en la primera página web visual;
un módulo para:
recibir una entrada de voz que incluye una frase pronunciada;
hacer corresponder la frase pronunciada con una de las frases alternativas identificadas por una de las reglas definidas por los segundos componentes de marcado; y
como respuesta a la correspondencia, navegar desde la primera página web visual hasta la página web respectiva especificada por la parte de comando de la regla que identifica la frase con la que se hizo corresponder la frase pronunciada; y
una base de datos para almacenar al menos una parte de la primera gramática basada en reglas con relación a la primera página web visual.
25. El sistema según la reivindicación 24, en el que los primeros componentes de marcado están en forma de lenguaje de marcado de hipertexto.
26. El sistema según la reivindicación 24, en el que la navegación incluye recibir segundos datos de página web que especifican una segunda página web visual y una segunda gramática basada en reglas asociada.
27. El sistema según la reivindicación 24, que comprende además:
una disposición configurada para proporcionar como salida de manera audible contenido relacionado con la primera página web visual.
28. El sistema según la reivindicación 27, en el que la salida audible se produce como respuesta a la recepción de la entrada de voz.
Patentes similares o relacionadas:
Aparato para responder a una llamada telefónica cuando un destinatario de la llamada telefónica decide que resulta inapropiado hablar y método relacionado, del 26 de Febrero de 2020, de Saronikos Trading and Services, Unipessoal Lda: Aparato (1a; 1b) para responder a una llamada telefónica cuando un destinatario de dicha llamada telefónica decide que resulta inapropiado hablar, […]
Procedimiento de asistencia en el seguimiento de una conversación para una persona con problemas de audición, del 5 de Diciembre de 2018, de Guedon, Christophe: Procedimiento de asistencia en el seguimiento de una conversación con una pluralidad de interlocutores para una persona con problemas […]
Procedimiento de sincronización entre una operación de procesamiento de reconocimiento vocal y una acción de activación de dicho procesamiento, del 4 de Abril de 2018, de Orange: Procedimiento de sincronización entre, por una parte, una operación de procesamiento por reconocimiento automático de la voz de una secuencia […]
MÉTODO DE INTERACCIÓN MEDIANTE VOZ PARA COMUNICACIÓN DURANTE CONDUCCIÓN DE VEHÍCULOS Y DISPOSITIVO QUE LO IMPLEMENTA, del 7 de Diciembre de 2017, de XESOL I MAS D MAS I, S.L: Se describe en este documento un procedimiento y un dispositivo que permiten llevar a cabo interacción mediante voz para comunicación durante […]
MÉTODO DE INTERACCIÓN MEDIANTE VOZ PARA COMUNICACIÓN DURANTE CONDUCCIÓN DE VEHÍCULOS Y DISPOSITIVO QUE LO IMPLEMENTA, del 30 de Noviembre de 2017, de XESOL I MAS D MAS I, S.L: Método de interacción mediante voz para comunicación durante conducción de vehículos y dispositivo que lo implementa. Se describe en este documento un procedimiento […]
Procedimiento y sistema para obtener información relevante de una comunicación por voz, del 6 de Abril de 2016, de TELEFONICA, S.A.: Procedimiento para obtener información relevante de una comunicación por voz proporcionada entre al menos dos usuarios, en el que la comunicación por voz comprende […]
 Sistema y método para realizar consultas textuales en comunicaciones de voz, del 6 de Enero de 2016, de JaJah Ltd: Un sistema para realizar consultas textuales en comunicaciones de voz, comprendiendo el sistema:
un servicio de índices para almacenar […]
Sistema y método para realizar consultas textuales en comunicaciones de voz, del 6 de Enero de 2016, de JaJah Ltd: Un sistema para realizar consultas textuales en comunicaciones de voz, comprendiendo el sistema:
un servicio de índices para almacenar […]
 Mezclador de pistas de audio semántico, del 16 de Diciembre de 2015, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Mezclador de audio para mezclar una pluralidad de pistas de audio para dar una senal de mezcla (MS), comprendiendo el mezclador de audio:
[…]
Mezclador de pistas de audio semántico, del 16 de Diciembre de 2015, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Mezclador de audio para mezclar una pluralidad de pistas de audio para dar una senal de mezcla (MS), comprendiendo el mezclador de audio:
[…]