Procedimiento para determinar la similitud de porciones de texto.
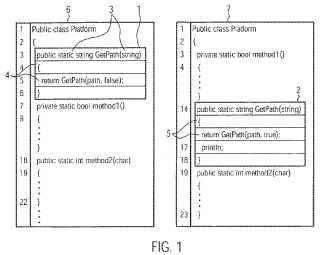
Procedimiento ejecutado informaticamente para determinar automaticamente Si una primera porción de texto (1)debe ser considerada como incluida o no en una segunda porción de texto (2),
en la que puede estar incluida en unaforma no modificada o modificada, estando ambas porciones de texto codificadas electrenicamente y estructuradasen un núero respectivo de una o mas lineas (4 5)
el procedimiento caracterizado por las etapas de
seleccionar una linea L, de la primera porcion de texto y una linea 4 de la segunda porción de texto, incluyendo lalinea L al menos una, dos, tres o mas palabra/s (3) e incluyendo la linea Z1 al menos una, dos, tres o mas palabra/s;aplicar un algoritmo L e ve n shte in modificado a la tupla que se compone de las lineas L, y Z, comparando el algoritmoLevenshtein cada palabra de la linea L, con una o algunas o cada palabra/s de la linea 4 para determinar si laspalabras comparadas son iguales o no, y calcular, utilizando el si las palabras comparadas son iguales o no, almenos un valor de resultado;
determinar, utilizando el al menos un valor de resultado, si la primera porción de texto ha de ser considerada o nocomo incluida en la segunda porción de texto; y
si la linea L, se considera como incluida en la linea 4 comparar la linea que sucede a L, de la primera porción detexto solo con las lineas que suceden a la linea 4 de la segunda porción de texto.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E10005512.
Solicitante: Códice Software S.L.
Nacionalidad solicitante: España.
Inventor/es: RUIZ,ARROYO BORJA, SANTOS LUACES,PABLO.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F17/22
PDF original: ES-2426327_T3.pdf
Fragmento de la descripción:
PROCEDIMIENTO PARA DETERMINAR LA SIMILITUD DE PORCIONES DE TEXTO
La presente invención proporciona un procedimiento para determinar si una primera porción de texto debe considerarse como incluida en una segunda porción de texto, en el que ésta puede estar incluida en una forma 5 modificada o no modificada. Este procedimiento puede ser implementado en una herramienta de soporte a un usuario en diferentes versiones de combinación de un documento de base electrónica.El proceso de edición de un documento electrónico por lo general incluye componer diferentes versiones del documento. Por ejemplo, un escritor del documento puede, en un momento dado, decidir reestructurar su versión actual al mismo tiempo que no desea abandonarla definitivamente. Por lo tanto, puede que desee mantener la versión antigua para un posible uso posterior. En consecuencia, existirían en paralelo una versión más nueva y una versión más antigua del documento electrónico. En otro ejemplo, varias personas pueden colaborar en la edición de documentos, posiblemente cada una modificando una versión base del mismo, componiendo así una respectiva versión propia del documento electrónico. Por ejemplo, cada uno de los compositores podría suprimir o añadir una porción de texto de la o a la versión base, o puede mover una porción a otra posición en el documento y así sucesivamente. En particular, en el campo de la ingeniería de software, el desarrollo concurrente y paralelo realizado por varios contribuyentes se ha convertido en un concepto básico de la producción de código de software.
En estos casos, las diversas versiones creadas están representadas cada una de ellas en un respectivo documento electrónico. Estos documentos pueden ser diferentes el uno del otro en el hecho de que las porciones de texto que aparecen en un primer documento no aparecen en un segundo documento, o aparecer en una formulación modificada, o aparecer en otra posición del segundo documento con respecto al primero, posiblemente además en una formulación modificada.
Se sabe que las operaciones de combinación son para conciliar los respectivos documentos y combinarlos en uno solo. Para este fin, se realiza un análisis de las diferencias. En una combinación dual, se comparan dos versiones de un archivo entre sí con el fin de generar una combinación. En una combinación triple, se considera además un archivo original común de las dos versiones.
En algunos casos, dicha operación de combinación se puede realizar de forma automática. Sin embargo, hay muchos casos en los que se requiere una intervención manual. En particular, los escenarios en los que el texto de un primer documento es modificado y movido en comparación con una segunda versión, por lo general terminan en una operación de combinación manual. Por ejemplo, este tipo de situaciones aparecen con frecuencia cuando se utiliza la refactorización de software, la cual se centra en la modificación de código existente para mejorar su legibilidad y por lo tanto su mantenimiento, sin necesidad de cambiar el comportamiento de la aplicación externa.
Con el fin de identificar dicho texto movido que ni siquiera podría ser completamente idéntico a su contraparte en otro documento, se debe realizar una evaluación de la similitud entre las porciones de texto. Un objeto de la presente invención es proporcionar un procedimiento para determinar si una primera porción de texto debe ser considerada como incluida en una segunda porción de texto, en el que (si es así) ésta puede estar incluida en una forma no modificada o modificada. Otro objeto de la invención es mejorar las herramientas automáticas de combinación mediante la implementación de dicho procedimiento en las mismas, con el fin de reducir la incidencia de la necesidad de intervenciones manuales, o para asistir y guiar a un usuario en un proceso manual de combinación.
Estos objetos se consiguen con el procedimiento de la reivindicación 1 y el medio legible informáticamente de la reivindicación 14. En las reivindicaciones dependientes se describen realizaciones preferidas.
US 2009/0089754 (ZEIDMAN) 2 de Abril de 2009 describe un procedimiento para comparar dos documentos con el fin de identificar plagio de software.
El procedimiento de la reivindicación 1 determina si una primera porción de texto debe ser considerada o no como incluida en una segunda porción de texto, en el que puede ésta puede estar incluida en una forma no modificada o modificada o de lo contrario diferente, y en el que las porciones de texto están codificadas y estructuradas 55 electrónicamente para tener un respectivo número de una O más líneas. El número puede ser predeterminado.
En este documento, el que una primera porción de texto está "incluida" en una segunda porción de texto deberia recoger el significado de que la primera porción de texto es en realidad la totalidad de la segunda porción de texto. Además, el término "similitud" (y sus derivados) ha de entenderse como que incluye el significado de igualdad (o sus derivadas) . Es decir, cualesquiera dos entidades clonadas también se denominan en este documento como similares.
De acuerdo con el procedimiento de la reivindicación 1, se selecciona una línea L¡ de la primera porción de texto y una linea Z¡ de la segunda porción de texto, en el que tanto la linea L; como la linea Zj incluyen al menos una palabra. En un ejemplo particular, la linea L, puede incluir múltiples palabras tales como dos, tres o más palabras. Adicional o alternativamente, la linea Z¡ puede incluir dos, tres o más palabras.
En este documento, una palabra se define como uno o varios caracteres consecutivos en un texto escrito informáticamente, que están entre dos caracteres consecutivos de un conjunto predeterminado de uno o más caracteres especiales, o que están entre el inicio de una linea y el primero del (o de los) carácter (es) especial (es) de la linea, o entre el último del (o de lOs) carácter (es) especial (es) de la linea y el final de la linea o, si en la linea no aparece carácter especial alguno, entre el inicio y el final de la linea. El (o los) carácter (es) especial (es) (que se utilizan como carácter (es) de separación de palabras) no forman parte de la palabra o palabras. Por ejemplo, si el conjunto de caracteres especiales se define compuesto de los caracteres a, Ü y , entonces la linea de texto escrita "hereaareñtheüwordsa!" estaría compuesta de las palabras "here", "are", "the", "words" y "!",
El conjunto de estos caracteres especiales puede incluir el carácter de espacio y/o signos de puntuación como la coma, el punto, el punto y coma, los dos puntos, el signo de exclamación, etc. Adicional o alternativamente, el conjunto de caracteres puede incluir diferentes tipos de paréntesis y/o signos de interrogación y/o signos de igualdad y/o signos de desigualdad, por ejemplo. El procedimiento puede incluir la etapa de recibir una selección del conjunto de caracteres especiales. En una forma de realización preferida, el conjunto de caracteres se compone únicamente del carácter de espacio " ".
La notación de "dos" (o más) palabras significa que las cadenas respectivas aparecen como diferentes representaciones de texto, como por ejemplo en dos documentos electrónicos (por ejemplo, guardados en diferentes lugares o en diferentes posiciones de un documento electrónico) . No se pretende que esto signifique que las palabras como tales tienen un aspecto o significado diferente. Se supone que se hace una comparación de palabras y la determinación de si son iguales por parejas. Es decir, si una palabra w se compara con varias palabras W1, ... , Wt entonces se determina para cada j = 1, ... , t si W es igualo no a Wj.
Como se mencionó anteriormente, se tienen en cuenta las porciones de texto para incluir una segmentación fija del texto incluido en unas entidades. Estas entidades se considera que son lineas. Las lineas de las porciones de texto, es decir, la segmentación de cada una de las porciones de texto en lineas, pueden ser independientes de las respectivas representaciones de las porciones de texto en uno o más visualizador (es) . Por ejemplo, las lineas pueden estar definidas en una respectiva codificación interna de las porciones de texto. Las lineas pueden estar separadas por un carácter de retorno de carro. Sin embargo, son concebibles otras particiones diferentes de las definidas por lineas, tales como, por ejemplo, segmentos definidos por el número de palabras que incluyen.
El procedimiento puede incluir la etapa de recibir una selección de la primera y segunda porciones de texto, y/o de un algoritmo predeterminado que se va a utilizar.
La etapa de selección de lineas Li y Zj puede incluir... [Seguir leyendo]
Reivindicaciones:
1. Procedimiento ejecutado informáticamente para determinar automáticamente si una primera porción de texto (1) debe ser considerada como incluida o no en una segunda porción de texto (2) , en la que puede estar incluida en una forma no modificada o modificada, estando ambas porciones de texto codificadas electrónicamente y estructuradas en un número respectivo de una o más lineas (4, 5) ,
el procedimiento caracterizado por las etapas de seleccionar una linea L¡ de la primera porción de texto y una linea Z¡ de la segunda porción de texto, incluyendo la linea L, al menos una, dos, tres o más palabra/s (3) e incluyendo la linea Z¡ al menos una, dos, tres o más palabra/s;
aplicar un algoritmo Levenshlein modificado a la tupla que se compone de las lineas L¡ y Z¡, comparando el algoritmo Levenshlein cada palabra de la linea L¡ con una o algunas o cada palabra/s de la linea Z¡ para determinar si las palabras comparadas son iguales o no, y calcular, utilizando el si las palabras comparadas son iguales o no, al menos un valor de resultado;
determinar, utilizando el al menos un valor de resultado, si la primera porción de texto ha de ser considerada o no como incluida en la segunda porción de texto; y
si la línea L¡ se considera como incluida en la linea Zj comparar la linea que sucede a L¡ de la primera porción de texto sólo con las lineas que suceden a la linea Z¡ de la segunda porción de texto.
2. Procedimiento de la reivindicación 1, en el que la determinación de si la primera porción de texto ha de ser considerada o no comO incluida en la segunda porción de texto incluye la etapa de determinar (31) si la linea L¡ ha de ser considerada como similar a la linea Zb que incluye comparar (23) el al menos un valor de resultado con un valor de umbral y determinar si las lineas L¡ y Z¡ han de ser consideradas o no como similares en base al resultado de la comparación,
en el que el procedimiento preferiblemente incluye además la etapa de recibir una selección del valor de umbral.
3. Procedimiento de la reivindicación 2, en el que la segunda porción de texto incluye varias lineas, y el procedimiento incluye además las etapas de seleccionar, en el caso de que la línea L¡ no se ha de considerar como similar a la línea Zj, una línea Zk diferente de Z¡ e incluida en la segunda porción de texto, comprendiendo la linea Z, al menos una, dos, tres o más palabra/s,
Y aplicar el algoritmo predeterminado a la tupla que se compone de la linea L¡ y la linea Z"
comparando el algoritmo cada palabra de la linea L¡ con una o algunas o cada palabra/s de la linea Z, para determinar si las palabras comparadas son iguales o no, y calcular, utilizando el si las palabras comparadas son iguales o no, al menos un valor de resultado adicional, y
en el que la determinación de si la primera porción de texto ha de ser considerada o no como incluida en la segunda porción de texto se basa además en el al menos un valor de resultado adicional.
4. Procedimiento de las reivindicaciones 2 ó 3, en el que la primera porción de texto y la segunda porción de texto ambas incluyen varias lineas, y el procedimiento incluye además las etapas de seleccionar, en el caso de que la línea l; se ha de considerar como similar a la línea Zj, una línea Lp incluida en la primera porción de texto y diferente de L¡, y una linea Z, incluida en la segunda porción de texto y diferente de Z¡, comprendiendo cada una de las lineas Lp y Z, al menos una, dos, tres o más palabra/s, y
aplicar el algoritmo predeterminado a la tupla que se compone de la linea Lp y la linea Z"
comparando el algoritmo cada palabra de la linea Lp con una o algunas o cada palabrals de la linea Z, para determinar si las palabras comparadas son iguales o no, y calcular por parte del algoritmo, utilizando el si las palabras comparadas son iguales o no, al menos un valor de resultado adicional, y
en el que la determinación de si la primera porción de texto ha de ser considerada o no como incluida en la segunda 5 porción de texto se basa además en el al menos un valor de resultado adicional.
5. Procedimiento de una de las reivindicaciones 2 a 4,
en el que el procedimiento comprende además determinar el número S de líneas de la primera porción de texto que han de ser consideradas como similares a una linea respectiva de la segunda porción de texto, y
calcular la ratio r del número S dividido por uno de los siguientes números 15 el número total de líneas de la primera porción de texto, o el número total de lineas de la segunda porción de texto, o la suma del número total de líneas de la primera porción de texto y el número total de líneas de la segunda porción de texto; y
en el que la determinación de si la primera porción de texto ha de ser considerada o no como incluida en la segunda porción de texto incluye la comparación (38) de la ratio r con un valor de umbral, y 25 en el que el procedimiento preferiblemente comprende además el paso de recibir una selección del valor de umbral.
6. El procedimiento de una de las reivindicaciones 1 a 5, en el que la segunda porción de texto se compone de un conjunto de una, dos, tres o más lineas incluidas en una tercera porción de texto (8) , comprendiendo el procedimiento además las etapas de seleccionar, si la primera porción de texto se ha determinado como que no ha de ser considerada como incluida en la segunda porción de texto (2a; 2b; 2c) , una nueva segunda porción de texto (2a'; 2b'; 2a"; 2b") que es otro conjunto de una o más líneas incluidas en la tercera porción de texto, y
determinar, mediante la aplicación del procedimiento de una de las reivindicaciones 1 a 5 a la primera y la nueva segunda porción de texto, si la primera porción de texto ha de ser considerada o no como incluida en la nueva segunda porción de texto.
7. El procedimiento de la reivindicación 6, en el que el número de lineas de la segunda porción de texto es igual al número de líneas de la primera porción de texto, y la nueva segunda porción de texto tiene el mismo número de líneas que la segunda porción de texto 45 o tiene al menos una linea más que la segunda porción de texto.
8. El procedimiento de una de las reivindicaciones 1 a 7, que comprende además la aplicación de una identificación, como por ejemplo resaltándolas en una representación en una pantalla, a la primera porción de texto y segunda porción de texto, si se determina que la primera porción de texto ha de considerarse incluida en el segunda porción de texto,
0, cuando el procedimiento incluye la característica de la reivindicación 2, si una o más líneas de la primera porción de texto se determinan como que son similares a una o más líneas respectivas de la segunda porción de texto, la aplicación de una identificación a la una o más líneas de cada una de la primera y segunda porciones de texto, como 55 por ejemplo, resaltándolas en una representación en una pantalla.
9. El procedimiento de una de las reivindicaciones 1 a 8, en el que la primera porción de texto es una porción de un primer documento electrónico (6) y la segunda porción de texto es una porción de un segundo documento electrónico (7) ,
en el que el primer y el segundo documentos electrónicos ambos son preferiblemente una respectiva versión modificada del mismo documento electrónico original, tal como un documento de código fuente de software.
10. El procedimiento de la reivindicación 9, en el que la primera y segunda porciones de texto se determinan, mediante un algoritmo de cálculo de diferencias aplicado al primer y segundo documento electrónico, como regiones de diferencias de los documentos electrónicos,
0, cuando se incluye la característica de la reivindicación 6, en el que la primera y tercera porciones de texto se determinan, mediante un algoritmo de cálculo de diferencias aplicado al primer y segundo documento electrónico, como regiones de diferencias de los documentos electrónicos.
11. Procedimiento para la detección de una operación de movimiento de código en un proceso de edición o combinación que involucra a unas versiones modificadas A y B de un mismo documento de base, incluyendo el procedimiento las etapas de aplicar un algoritmo de cálculo de diferencias a las versiones A y B, para determinar regiones de diferencias en estas versiones,
elegir una región de diferencias de cada una de las versiones A y B,
utilizar una región de diferencias elegida de una versión como una primera porción de texto y una región de diferencias elegida de la otra versión como la segunda porción de texto en la aplicación de uno de los procedimientos de las reivindicaciones 1 a 10;
o usar la región de diferencias elegida de una versión como una primera porción de texto, la región de diferencias elegida de la otra versión como la tercera porción de texto y una porción seleccionada de la tercera porción como la segunda porción de texto en la aplicación de uno de los procedimientos de las reivindicaciones 6 a 10 que incluye la característica de la reivindicación 6.
12. El procedimiento de la reivindicación 11, que comprende además determinar el número de líneas de cada una de las regiones de diferencias elegidas, determinar que una primera de las regiones de diferencias elegidas tiene un número de lineas más pequeño o igual
que el número de líneas de la otra región de diferencias elegida, y tener en cuenta la primera región de diferencias elegida como la primera porción de texto.
13. El procedimiento de una de las reivindicaciones 11 ó 12, que comprende además determinar que una región de diferencias incluye al menos un número de líneas mínimo predeterminado, incluyendo el procedimiento preferiblemente además recibir la selección del número de líneas mínimo.
14. Medio legible informáticamente que tiene almacenadas en el mismo unas instrucciones que realizan, cuando se ejecutan en un ordenador, uno o más de los procedimientos de las reivindicaciones 1 a 13.
-
=
=
=
=
=
Patentes similares o relacionadas:
Procedimiento para aplicar una marca de agua de libros digitales, del 1 de Abril de 2019, de VIACCESS: Un procedimiento para aplicar una marca de agua a libros digitales con parámetros unidos por una función biunívoca a identificadores respectivos, […]
Sistema y procedimiento de habilitación de enmascaramiento de datos para documentos web, del 20 de Febrero de 2019, de Tata Consultancy Services Limited: Un procedimiento que comprende: recibir una especificación de conversión asociada con múltiples documentos web de referencia y documentos web de referencia […]
Un método implementado por ordenador y sistema para una comunicación anónima y programa de ordenador para los mismos, del 15 de Febrero de 2017, de TELEFONICA DIGITAL ESPAÑA, S.L.U: Un método implementado por ordenador para una comunicación anónima, en el que se proporciona una comunicación entre un primer usuario que tiene un dispositivo de computación […]
Sistema de procesamiento de información y procedimiento de procesamiento de información para predicción de entrada de caracteres, del 28 de Diciembre de 2016, de OMRON CORPORATION: Un servidor de procesamiento de información para transmitir una candidata que puede ser incluida en una lista de candidatas de una palabra o frase correspondiente […]
 Método y aparato para introducir información, del 26 de Octubre de 2016, de Nokia Technologies OY: Un método para introducir información en un terminal de comunicación que tiene una pantalla; medios de navegación para navegar a través de los candidatos […]
Método y aparato para introducir información, del 26 de Octubre de 2016, de Nokia Technologies OY: Un método para introducir información en un terminal de comunicación que tiene una pantalla; medios de navegación para navegar a través de los candidatos […]
Sistema de identificación de pertenencias y método para dicho sistema, del 28 de Diciembre de 2015, de BETAFIX SERVICES S.L: Sistema de identificación de pertenencias que comprende: un servidor central , que a su vez comprende: una interfaz de entrada de […]
DISPOSICIÓN DE UNA ETIQUETA ELECTRÓNICA INFORMATIVA EN CAJA-CONTENEDOR, del 19 de Noviembre de 2013, de CARTONAJES LANTEGI, S.L.: 1. Disposición de una etiqueta electrónica informativa en caja-contenedor caracterizada porque la posición idónea de la etiqueta […]
COMPRESIÓN DE MODELOS DE LENGUAJE CON CODIFICACIÓN GOLOMB, del 27 de Enero de 2012, de MICROSOFT CORPORATION: Un procedimiento de compresión de un modelo de lenguaje que comprende: obtener valores numéricos mediante la aplicación de una función hash a n-gramas […]