Predicción lineal basada en esquema de codificación utilizando conformación de ruido de dominio espectral.
Codificador de audio que comprende
un descompositor espectral (10) para descomponer espectralmente,
usando un MDCT, una señal de audio de entrada (12) en un espectograma (14) de una secuencia de espectros;
una computadora de autocorrelación (50) configurada para calcular una autocorrelación de un espectro actual de la secuencia de espectros;
una computadora de coeficiente de predicción lineal (52) configurada para calcular coeficientes de predicción lineal en base a la correlación;
un formador de dominio espectral (22) configurado para formar espectralmente el espectro actual en base a los coeficientes de predicción lineal y
una etapa de cuantificación (24) configurada para cuantizar el espectro formado espectralmente;
en donde el codificador de audio está configurado para insertar información relativa al espectro formado espectralmente e información relativa a los coeficientes de predicción lineal en una corriente de datos, en donde la computadora de autocorrelación está configurada para, al calcular la autocorrelación del espectro actual, calcular el espectro de potencia del espectro actual y someter el espectro de potencia a una transformada de ODFT inversa.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2012/052455.
Solicitante: FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V..
Nacionalidad solicitante: Alemania.
Dirección: HANSASTRASSE 27C 80686 MUNCHEN ALEMANIA.
Inventor/es: RETTELBACH,NIKOLAUS, FUCHS,Guillaume, Helmrich,Christian, MARKOVIC,GORAN, SCHUBERT,BENJAMIN.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L19/012 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › Codificación del ruido de confort o el silencio.
PDF original: ES-2534972_T3.pdf
Fragmento de la descripción:
Predicción lineal basada en esquema de codificación utilizando conformación de ruido de dominio espectral
La presente invención se refiere a un códec [codificador–decodificador] de audio sobre la base de la predicción lineal usando la conformación de ruido en el dominio de la frecuencia, tal como el modo TCX [sigla en inglés de: excitación codificada de transformada] conocido de la USAC [sigla en inglés de: codificación de habla y audio unificada].
Como códec de audio relativamente nuevo, el USAC ha sido recientemente finalizado. El USAC es un códec que soporta el cambio entre varios modos de codificación, tales como un modo de codificación del tipo AAC [sigla en inglés de: codificación de audio avanzada], un modo de codificación en el dominio del tiempo usando la codificación de predicción lineal, a decir, ACELP [sigla en inglés de: Predicción Lineal excitada por código algebraico (algoritmo de codificación de habla) ], y la codificación de excitación codificada por transformada que forma un modo de codificación intermedio de acuerdo con el cual la conformación en el dominio espectral se controla usando los coeficientes de predicción lineal transmitidos por medio de la corriente de datos. En la solicitud WO 2011147950, se ha hecho una propuesta para tornar el esquema de codificación USAC más adecuado para aplicaciones de bajo retardo, mediante la exclusión del modo de codificación de tipo AAC de la disponibilidad, y la restricción de los modos de codificación solo a ACELP y TCX. Además, se ha propuesto reducir la longitud de trama.
Sin embargo, sería favorable contar con una posibilidad práctica de reducir la complejidad de un esquema de codificación sobre la base de la predicción lineal usando la conformación de dominio espectral, y a la vez, lograr una eficiencia de codificación similar en términos de, por ejemplo, el sentido de la relación de tasa/distorsión.
Por lo tanto, un objetivo de la presente invención es proporcionar dicho esquema de codificación sobre la base de la predicción lineal usando la conformación de dominio espectral, a fin de permitir una reducción de la complejidad, con una eficiencia de codificación comparable o aun mayor.
Este objetivo es logrado por el objeto del asunto de las reivindicaciones independientes pendientes.
Una idea básica que subyace a la presente invención es que un concepto de codificación que se basa en la predicción lineal y que utiliza la conformación de ruido de dominio espectral puede tornarse menos complejo con una eficiencia de codificación comparable en términos de, por ejemplo, la relación de tasa/distorsión, si la descomposición espectral de la señal de entrada de audio en un espectrograma que comprende una secuencia de espectros se usa tanto para el cómputo del coeficiente de predicción lineal como para la entrada para una conformación de dominio espectral sobre la base de los coeficientes de predicción lineal.
En este sentido, se ha hallado que la eficiencia de codificación permanece, aun si se usa dicha transformada superpuesta para la descomposición espectral que causa aliasing y necesita la cancelación del aliasing del tiempo, tal como transformadas superpuestas críticamente muestreadas, por ejemplo, una MDCT [sigla en inglés de: transformada de coseno discreta modificada].
Las implementaciones convenientes de los aspectos de la presente invención son el objeto de las reivindicaciones dependientes.
En particular, las realizaciones preferidas de la presente solicitud se describen con respecto a las figuras, en las cuales: la Fig. 1 muestra un diagrama de bloques de un codificador de audio de acuerdo con una comparación o realización; la Fig. 2 muestra un codificador de audio de acuerdo con una realización de la presente solicitud; la Fig. 3 muestra un diagrama de bloques de un posible decodificador de audio que se adapta al codificador de audio de laFig.2; y la Fig. 4 muestra un diagrama de bloques de un codificador de audio alternativo de acuerdo con una realización de la presente solicitud.
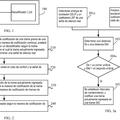
[00010] A fin de facilitar la comprensión de los principales aspectos y ventajas de las realizaciones de la presente invención que se describe adicionalmente a continuación, se hace referencia preliminar a la Fig. 1, que muestra un codificador de audio sobre la base de la predicción lineal usando la conformación de ruido de dominio espectral.
[00011] En particular, el codificador de audio de la Fig. 1 comprende un descomponedor espectral 10, para la descomposición espectral de una señal de audio de entrada 12 en un espectrograma que consiste en una secuencia de espectros, que se indica en 14 en la Fig. 1. Como se muestra en la Fig. 1, el descomponedor espectral 10 puede utilizar una MDCT a fin de transferir la señal de audio de entrada 10 del dominio del tiempo al dominio espectral. En particular, un ventaneador 16 precede el módulo MDCT 18 del descomponedor espectral 10, de manera de ventanear porciones de superposición mutua de la señal de audio de entrada 12, cuyas porciones ventaneadas son individualmente sometidas a la respectiva transformada en el módulo MDCT 18, a fin de obtener los espectros de la secuencia de espectros del espectrograma 14. Sin embargo, el descomponedor espectral 10, alternativamente,
puede utilizar cualquier otra transformada superpuesta que cause aliasing, tal como cualquier otra transformada superpuesta críticamente muestreada.
[00012] Asimismo, el codificador de audio de la Fig. 1 comprende un analizador de predicción lineal 20 para el análisis de la señal de audio de entrada 12, de manera de derivar de allí los coeficientes de predicción lineal. Un conformador de dominio espectral 22 del codificador de audio de la Fig. 1 está configurado para conformar espectralmente un espectro corriente de la secuencia de espectros del espectrograma 14, sobre la base de los coeficientes de predicción lineal proporcionados por el analizador de predicción lineal 20. En particular, el conformador de dominio espectral 22 está configurado para conformar espectralmente un espectro corriente que entra en el conformador de dominio espectral 22 de acuerdo con una función de transferencia que corresponde a una función de transferencia de filtro de análisis de predicción lineal mediante la conversión de los coeficientes de predicción lineal del analizador 20, en valores de peso espectrales y la aplicación de estos valores de peso como divisores, de manera de formar o conformar espectralmente el espectro corriente. El espectro conformado se somete a la cuantificación en un cuantificador 24 del codificador de audio de la Fig. 1. Debido a la conformación en el conformador de dominio espectral 22, el ruido de la cuantificación que resulta con la desconformación del espectro cuantificado del lado del decodificador es cambiado de modo de ocultarse, es decir, la codificación es lo más perceptivamente transparente posible.
[00013] Solo por razones de integridad, se observa que un módulo de conformación de ruido temporal 26 puede someter opcionalmente los espectros avanzados desde el descomponedor espectral 10 hacia el conformador de dominio espectral 22, a un conformador de ruido temporal, y un módulo de énfasis de baja frecuencia 28 puede filtrar adaptativamente cada salida de espectro conformado del conformador de dominio espectral 22, antes de la cuantificación 24.
[00014] El espectro cuantificado y espectralmente conformado se inserta en la corriente de datos 30 junto con información sobre los coeficientes de predicción lineal utilizados en la conformación espectral, de manera que, del lado de la decodificación, pueden efectuarse la desconformación y descuantificación.
[00015] La mayoría de las partes del códec de audio, excepto el módulo TNS [sigla en inglés de: conformación de ruido temporal] 26, que se muestran en la Fig. 1 son, por ejemplo, representadas y descriptas en el nuevo códec de audio USAC, y en particular, dentro de su modo TCX. Por lo tanto, para más detalles, se hace referencia ejemplarmente a las pautas USAC, por ejemplo, [1].
[00016] Sin embargo, se proporciona mayor énfasis en lo que sigue con respecto al analizador de predicción lineal
20. Como se expone en la Fig. 1, el analizador de predicción lineal 20 opera directamente sobre la señal de audio de entrada 12. Un módulo de preénfasis 32 prefiltra la señal de audio de entrada 12, por ejemplo, mediante la filtración FIR, y a continuación, se deriva en forma continua una autocorrelación por medio de una concatenación de un ventaneador 34, un autocorrelacionador 36 y ventaneador de demora 38. El ventaneador 34 forma porciones ventaneadas a partir de la señal de audio de entrada prefiltrada, cuyas... [Seguir leyendo]
Reivindicaciones:
1. Codificador de audio que comprende un descompositor espectral (10) para descomponer espectralmente, usando un MDCT, una señal de audio de entrada (12) en un espectograma (14) de una secuencia de espectros; una computadora de autocorrelación (50) configurada para calcular una autocorrelación de un espectro actual de la secuencia de espectros; una computadora de coeficiente de predicción lineal (52) configurada para calcular coeficientes de predicción lineal en base a la correlación; un formador de dominio espectral (22) configurado para formar espectralmente el espectro actual en base a los coeficientes de predicción lineal y una etapa de cuantificación (24) configurada para cuantizar el espectro formado espectralmente; en donde el codificador de audio está configurado para insertar información relativa al espectro formado espectralmente e información relativa a los coeficientes de predicción lineal en una corriente de datos, en donde la computadora de autocorrelación está configurada para, al calcular la autocorrelación del espectro actual, calcular el espectro de potencia del espectro actual y someter el espectro de potencia a una transformada de ODFT inversa.
2. El codificador de audio según la reivindicación 1, que comprende: un predictor de espectro (26) configurado para filtrar predictivamente el espectro actual a lo largo de una dimensión espectral, en donde el formador de dominio espectral está configurado para formar espectralmente el espectro actual filtrado predictivamente, y el codificador de audio está configurado para insertar información relativa a como invertir el filtrado predictivo en la corriente de datos.
3. El codificador de audio según la reivindicación 2, en donde el predictor de espectro está configurado para efectuar filtrado de predicción lineal en el espectro actual a lo largo de la dimensión espectral, en donde el formador de corriente de datos está configurado de tal manera que la información relativa a como invertir el filtrado predictivo comprende información relativa a coeficientes de predicción lineales adicionales subyacentes al filtrado de predicción lineal relativo al espectro actual a lo largo de la dimensión espectral.
4. El codificador de audio según la reivindicación 2 o 3, en donde el codificador de audio está configurado para decidir habilitar o deshabilitar el predictor de espectro dependiendo de la tonalidad o transitoriedad de la señal de entrada de audio o una ganancia de predicción de filtro, en donde el codificador de audio está configurado para insertar información relativa a la decisión.
5. El codificador de audio según cualquiera de las reivindicaciones 2 a 4, en donde la computadora de autocorrelación está configurada para calcular la autocorrelación del espectro actual filtrado predictivamente.
6. El codificador de audio según cualquiera de las reivindicaciones 2 a 5, en donde el descompositor espectral
(10) está configurado para conmutar entre diferentes longitudes de transformada al descomponer espectralmente de la señal de entrada de audio (12) de tal manera que los espectros son de resolución espectral diferente, en donde la computadora de autocorrelación (50) está configurada para calcular la autocorrelación del espectro actual filtrado predictivamente en caso de una resolución espectral del espectro actual que satisfaga un criterio predeterminado, o del espectro actual no filtrado predictivamente en caso de que la resolución espectral del espectro actual no satisfaga el criterio predeterminado.
7. El codificador de audio según la reivindicación 6, en donde la computadora de autocorrelación está configurada de tal manera que el criterio predeterminado se satisface si la resolución espectral del espectro actual es más alta que un umbral de resolución espectral.
8. El codificador de audio según cualquiera de las reivindicaciones 1 a 7, en donde la computadora de autocorrelación está configurada para, al calcular la autocorrelación del espectro actual, ponderar perceptualmente el espectro de potencia y someter el espectro de potencia a la transformada de ODFT inversa como ponderada perceptualmente.
9. El codificador de audio según la reivindicación 8, en donde la computadora de autocorrelación está configurada para cambiar una escala de frecuencia del espectro actual y para efectuar la ponderación perceptual del espectro de potencia en la escala de frecuencia cambiada.
10. El codificador de audio según cualquiera de las reivindicaciones 1 a 9, en donde el codificador de audio está configurado para insertar la información relativa a los coeficientes de predicción lineal en la corriente de datos de una forma cuantizada, en donde el formador de dominio espectral está configurado para formar espectralmente el espectro actual en base a los coeficientes de predicción lineales cuantizados.
11. El codificador de audio según la reivindicación 10, en donde el codificador de audio está configurado para insertar la información relativa a los coeficientes de predicción lineal en la corriente de datos de una forma de
acuerdo con la cual la cuantificación de los coeficientes de predicción lineal ocurre en el dominio LSF o LSP.
12. Método de codificación que comprende descomponer espectralmente, usando un MDCT, una señal de entrada de audio (12) en un espectograma (14) de una secuencia de espectros; calcular una autocorrelación de un espectro actual de la secuencia de espectros; calcular coeficientes de predicción lineal en base a la autocorrelación; formar espectralmente el espectro actual en base a los coeficientes de predicción lineal; cuantificar el espectro formado espectralmente; e
insertar información relativa al espectro formado espectralmente cuantizado e información relativa a los coeficientes de predicción lineal en una corriente de datos, en donde el cálculo de la autocorrelación del espectro actual comprende calcular el espectro de potencia del espectro actual y someter el espectro de potencia a una transformada de ODFT inversa.
13. Programa de computadora provistp de un código de programa pararealizar, cuando se ejecuta en una computadora, un método según la reivindicación 12.
Patentes similares o relacionadas:
 Método, dispositivo y sistema de transmisión de datos multimedia, del 24 de Junio de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de codificación de señales de audio que comprende:
en un caso en el cual una manera de codificación de una trama previa de una trama actualmente ingresada […]
Método, dispositivo y sistema de transmisión de datos multimedia, del 24 de Junio de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de codificación de señales de audio que comprende:
en un caso en el cual una manera de codificación de una trama previa de una trama actualmente ingresada […]
Aparato y método de selección de modo de generación de ruido de confort, del 6 de Mayo de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato para codificar información de audio, que comprende: un selector para seleccionar un modo de generación de ruido de confort […]
Método de generación y procesado de señal de ruido, codificador/decodificador y sistema de codificación/decodificación, del 22 de Abril de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de procesado de señal de ruido basado en predicción lineal, en donde el método comprende: adquirir (S51) una señal de ruido, y obtener un coeficiente de predicción […]
Método de procesamiento de señal de voz/audio y aparato de codificación, del 8 de Enero de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de procesamiento de señal de voz/audio, que comprende: si una primera señal de voz/audio de banda ancha es una señal armónica, ajustar una condición determinante […]
Método para estimar ruido en una señal de audio, estimador de ruido, codificador de audio, decodificador de audio, y sistema para transmitir señales de audio, del 20 de Noviembre de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Método para estimar ruido en una señal de audio, comprendiendo el método: determinar (S100) un valor de energía para la señal de audio; convertir […]
Métodos y aparatos para retención DTX en codificación de audio, del 12 de Junio de 2019, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método realizado por un codificador, el codificador funcionando para codificar la conversación y aplicar un esquema de transmisión discontinua, DTX, que […]
Codificación y decodificación de posiciones de impulso de pistas de una señal de audio, del 3 de Junio de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato para decodificar una señal de audio codificada, en el que una o más pistas se asocian con la señal de audio codificada, teniendo […]
Aparato y procedimiento para codificar una señal de audio usando una parte de anticipación alineada, del 10 de Abril de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato para codificar una señal de audio que presenta un flujo de muestras de audio , que comprende: un dispositivo de división en ventanas […]