MÉTODO Y SISTEMA PARA REDUCIR LOS EFECTOS DE LOS ARTEFACTOS QUE PRODUCEN RUIDO.
Método de reducción del efecto de los artefactos que producen ruido en las zonas de silencio de una señal de habla para su utilización por un sistema de decodificación del habla,
comprendiendo el método: obtener una pluralidad de muestras entrantes de una subtrama del habla; sumar un valor absoluto de un nivel de energía para cada una de la pluralidad de muestras entrantes con el fin de generar un nivel de entrada total (gain_in); alisar el nivel de entrada total para generar un nivel alisado (Level_in_sm); determinar que la subtrama del habla está en una zona de silencio sobre la base del nivel de entrada total, el nivel alisado y un parámetro de inclinación; definir una ganancia utilizando k1 * (Level-in_sml1024) + (1-k1), en el que k1 es una función del parámetro de inclinación; y modificar un nivel de energía de la subtrama del habla utilizando la ganancia
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/US2006/041434.
Solicitante: MINDSPEED TECHNOLOGIES, INC.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 4000 MACARTHUR BLVD., EAST TOWER NEWPORT BEACH, CA 92660-3095 ESTADOS UNIDOS DE AMERICA.
Inventor/es: GAO,YANG, SHLOMOT,EYAL.
Fecha de Publicación: .
Fecha Solicitud PCT: 23 de Octubre de 2006.
Clasificación Internacional de Patentes:
- G10L21/02R
- H03G3/30N
- H03G3/34A
Clasificación PCT:
- G10L21/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 21/00 Tratamiento de la señal de la voz para producir otra señal audible o no audible, p. ej. visual o táctil, con el fin de modificar su calidad o su inteligibilidad (G10L 19/00 tiene prioridad). › Mejora de la inteligibilidad de la voz, p. ej. reducción de ruido o eliminación de ecos (reducción de efectos de eco en los sistemas de transmisión en línea H04B 3/20; supresión de eco en teléfonos de manos libres H04M 9/08).
- H03G3/20 ELECTRICIDAD. › H03 CIRCUITOS ELECTRONICOS BASICOS. › H03G CONTROL DE LA AMPLIFICACION (redes de impedancia, p. ej. atenuadores H03H; control de la transmisión en líneas H04B 3/04). › H03G 3/00 Control de la ganancia en los amplificadores o cambiadores de frecuencia (amplificadores controlados H03F 3/72; específicamente para los receptores de televisión H04N). › Control automático (combinado con la compresión o expansión de volumen H03G 7/00).
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia, Ex República Yugoslava de Macedonia, Albania.
PDF original: ES-2356503_T3.pdf
Fragmento de la descripción:
ANTECEDENTES DE LA INVENCIÓN
1. CAMPO DE LA INVENCIÓN
La presente invención se refiere en general a la codificación del habla. Más particularmente, la presente invención se refiere a la reducción de los efectos de los artefactos que producen ruido en un códec (codificador-5 decodificador) de voz.
2. ANTECEDENTES DE LA TÉCNICA
La compresión del habla se puede utilizar para reducir el número de bits que representan la señal de habla, reduciéndose así el ancho de banda necesario para la transmisión. No obstante, la compresión del habla puede producir el deterioro de la calidad del habla descomprimida. En general, una mayor velocidad binaria producirá una calidad 10 superior, mientras que una menor velocidad binaria producirá una calidad inferior. No obstante, las técnicas actuales de compresión del habla, tales como las técnicas de codificación, pueden producir un habla descomprimida de calidad relativamente alta a velocidades binarias relativamente bajas. En general, las técnicas de codificación actuales intentan representar las características de la señal del habla, importantes desde el punto de vista perceptivo, sin conservar la forma de onda real del habla. Los sistemas de compresión del habla, denominados comúnmente códecs, incluyen un 15 codificador y un decodificador, y se pueden utilizar para reducir la velocidad binaria de señales de habla digitales. Se han desarrollado numerosos algoritmos para códecs de habla, que reducen el número de bits requeridos para codificar digitalmente el habla original al mismo tiempo que se intenta mantener un habla reconstruida de alta calidad.
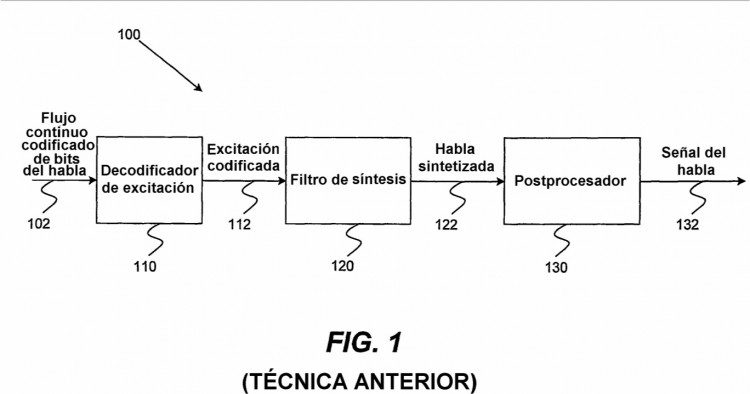
La figura 1 ilustra un sistema convencional de decodificación del habla 100, que incluye un decodificador de excitación 110, un filtro de síntesis 120 y un posprocesador 130. Tal como se muestra, el sistema de decodificación 100 20 recibe un flujo continuo codificado de bits de habla 102 a través de un medio de comunicación (no representado) desde un codificador, en el que el sistema de decodificación 100 puede formar parte de un dispositivo de comunicaciones móviles, una estación base u otro dispositivo de comunicaciones inalámbricas o por cable que pueda recibir el flujo continuo codificado de bits de habla 102. El sistema de decodificación 100 funciona de modo que decodifica el flujo continuo codificado de bits de habla 102 y genera una señal de habla 132 en forma de una señal digital. A continuación, 25 la señal de habla 132 se puede convertir en una señal analógica por medio de un conversor digital-a-analógico (no representado). La salida analógica del conversor digital-a-analógico puede ser recibida por un receptor (no representado) que puede ser un oído humano, un grabador de cintas magnéticas, o cualquier otro dispositivo que pueda recibir una señal analógica. Alternativamente, la señal del habla 132 puede ser recibida por un dispositivo de grabación digital, un dispositivo de reconocimiento del habla, o cualquier otro dispositivo que pueda recibir una señal digital. 30
El decodificador de excitación 110 decodifica el flujo continuo codificado de bits del habla 102 según el algoritmo de codificación y la velocidad binaria del flujo continuo codificado de bits del habla 102, y genera una excitación decodificada 112. El filtro de síntesis 120 puede ser un filtro de predicción a corto plazo que genera habla sintetizada 122 basándose en la excitación decodificada 112. El posprocesador 130 puede incluir filtrado, aumento de la señal, reducción del ruido, amplificación, corrección de la inclinación (tilt correction) y otras técnicas similares que 35 pueden mejorar la calidad de percepción del habla sintetizada 122. El posprocesador 130 puede reducir el ruido audible sin deteriorar perceptiblemente el habla sintetizada 122. La reducción del ruido audible se puede lograr realzando la estructura de los formantes del habla sintetizada 122 ó suprimiendo el ruido en las regiones de frecuencia que no son relevantes desde el punto de vista de la percepción, para el habla sintetizada 122.
En los codificadores del habla de velocidad variable, las partes del habla importantes desde el punto de vista de 40 la percepción (por ejemplo, voz sonora, oclusivas, o comienzos sonoros) se codifican con un número mayor de bits, y las partes menos importantes del habla (por ejemplo, partes sordas o silencio entre palabras) se codifican con un número menor de bits. La supresión del ruido hace que mejore la calidad de la señal de voz reconstruida y ayuda a que los codificadores del habla de velocidad variable distingan partes de voz con respecto a partes de ruido. La supresión del ruido ayuda también a que los codificadores del habla de baja velocidad binaria produzcan una salida de mayor calidad 45 mejorando la calidad de percepción del habla. Típicamente, las técnicas de supresión del ruido eliminan el ruido por métodos de sustracción espectral en el dominio de la frecuencia. Un detector de actividad vocal (VAD) determina en el dominio del tiempo si una trama de la señal incluye habla o ruido. Las tramas de ruido se analizan en el dominio de la frecuencia para determinar las características de la señal de ruido. A partir de estas características, los espectros de tramas de ruido se restan de los espectros de las tramas de habla, proporcionando una señal de habla limpia en las 50 tramas de habla.
Además, se puede aplicar una atenuación del ruido en el dominio del tiempo para mejorar la calidad de una señal de habla. Por ejemplo, en un sistema de codificación del habla con atenuación del ruido en el dominio del tiempo, descrito en el documento US 2002/00354 70 A1, las ganancias de la codificación del habla con predicción lineal se ajustan por medio de un factor de ganancia para suprimir el ruido de fondo. Tal como se describe en dicho documento, 55 el sistema de codificación del habla utiliza una supresión del ruido en el dominio de la frecuencia junto con una atenuación de la voz en el dominio del tiempo para reducir adicionalmente el ruido de fondo. Después de que una señal analógica se haya convertido en una señal digitalizada, un preprocesador suprime el ruido en la señal digitalizada
utilizando un VAD y supresión del ruido en el dominio de la frecuencia. Cuando el VAD identifica una trama asociada a solamente ruido (sin habla), una trama con ventana que incluye la trama identificada de aproximadamente 10 ms se transforma al dominio de la frecuencia. A continuación, se modifican magnitudes espectrales de la señal del habla con ruido para reducir el nivel de ruido según una SNR estimada, y las magnitudes espectrales modificadas se combinan con las fases espectrales sin modificar. A continuación, el espectro modificado se transforma de nuevo al dominio del 5 tiempo. Un esquema de análisis-por-síntesis selecciona la mejor representación para varios parámetros, tales como una ganancia ajustada de libro de códigos fijo, un índice de libro de códigos fijo, un parámetro de retardo, y el parámetro de ganancia ajustada del predictor a largo plazo. Las ganancias se pueden ajustar con un factor de ganancia antes de la cuantificación. El factor de ganancia Gf puede suprimir el ruido de fondo en el dominio del tiempo al mismo tiempo que manteniendo la señal del habla, en el que Gf es definida por Gf= 1 - C.NSR, en el que NSR es la relación ruido/señal 10 basada en tramas, y C es una constante en el intervalo de entre 0 y 1 y controla el grado de reducción del ruido. NSR representa un valor de aproximadamente 1 cuando en la trama se detecta únicamente ruido de fondo, y cuando se detecta habla en la trama, NSR es la raíz cuadrada de la energía de ruido del fondo dividida por la energía de la señal en la trama. Los documentos US5550924 y US6453289 dan a conocer métodos de reducción de ruido para la mejora del habla. 15
No obstante, los planteamientos existentes no plantean correctamente la reducción de efectos de los artefactos que producen ruido en las zonas de silencio de una señal de habla, y especialmente cuando no se encuentra disponible un VAD. En las zonas de silencio, los valores de las muestras son bastante pequeños y sus errores de cuantificación son relativamente muy elevados. Los efectos de estos errores son agravados adicionalmente por la implementación de coma fija de un algoritmo de codificación del habla con su precisión limitada por el uso de valores enteros, lo cual da 20 como resultado que los errores de cuantificación relativos de las zonas de silencio resulten mucho mayores, provocando así una mayor energía de salida en comparación con la energía de entrada original de silencio, y un ruido más audible.... [Seguir leyendo]
Reivindicaciones:
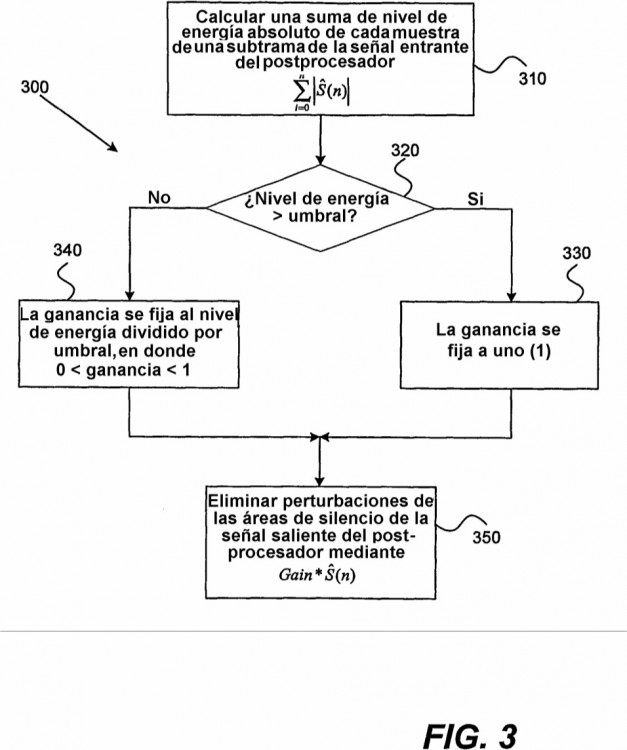
1. Método de reducción del efecto de los artefactos que producen ruido en las zonas de silencio de una señal de habla para su utilización por un sistema de decodificación del habla, comprendiendo el método: obtener una pluralidad de muestras entrantes de una subtrama del habla; sumar un valor absoluto de un nivel de energía para cada una de la pluralidad de muestras entrantes con el fin de generar un nivel de entrada total (gain_in); alisar el nivel de 5 entrada total para generar un nivel alisado (Level_in_sm); determinar que la subtrama del habla está en una zona de silencio sobre la base del nivel de entrada total, el nivel alisado y un parámetro de inclinación; definir una ganancia utilizando k1 * (Level-in_sml1024) + (1-k1), en el que k1 es una función del parámetro de inclinación; y modificar un nivel de energía de la subtrama del habla utilizando la ganancia.
2. Método según la reivindicación 1, en el que el alisado se realiza utilizando: Level_in_sm = 0,75 * 10 Level_in_sm + 0,25 * gain_in y/o la determinación se realiza utilizando: (Level_in_sm<1024) && (gain_in<2*Level_in_sm)&& (parcor0 <512/32768).
3. Método según la reivindicación 1, que comprende además: asignar Level_in_sm a gain_in (gain_in = Level_in_sm) si Level_in_sm < gain_in, comprendiendo además opcionalmente: sumar un valor absoluto de un nivel de energía para cada una de la pluralidad de muestras salientes, antes de la modificación, con el fin de generar un nivel de 15 salida total (gain_out); determinar una ganancia inicial utilizando (gain_in / gain_out); y modificar la ganancia utilizando la ganancia inicial para generar una ganancia modificada (g0), opcionalmente además
en el que la modificación comprende multiplicar sig_out para cada una de la pluralidad de muestras salientes por una ganancia alisada (g_sm), en el que g_sm se obtiene utilizando iteraciones desde 0 a n-1 de (g_sm previa * 0,95 + g0*0,05), en el que n es el número de muestras, y g_sm previa es cero (0) antes de la primera 20 iteración.
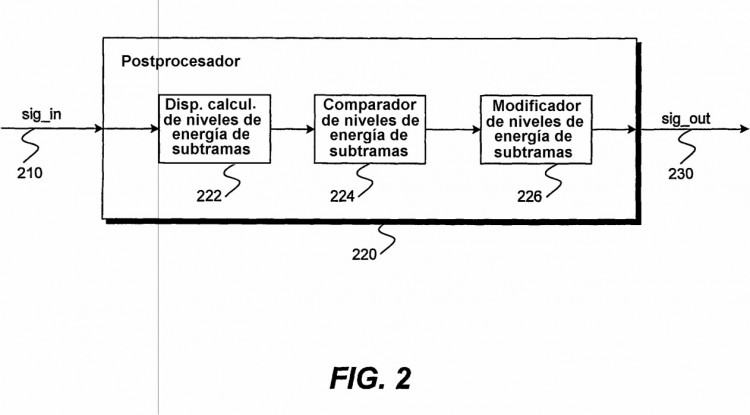
4. Sistema de decodificación del habla para reducir el efecto de los artefactos que producen ruido en las zonas de silencio de una señal de habla, comprendiendo el sistema de decodificación del habla: un calculador del nivel de energía de subtrama configurado para obtener una pluralidad de muestras entrantes de una subtrama del habla, y configurado para sumar un valor absoluto de un nivel de energía para cada una de la pluralidad de muestras entrantes 25 con el fin de generar un nivel de entrada total (gain_in), y configurado además para alisar el nivel de entrada total con el fin de generar un nivel alisado (Level_in_sm); un comparador de nivel de energía de subtrama configurado para determinar que la subtrama del habla se encuentra en una zona de silencio sobre la base del nivel de entrada total, el nivel alisado y un parámetro de inclinación; y un modificador del nivel de energía de subtrama configurado para definir una ganancia utilizando k1*(Level_in_sml1024) + (1-k1), en el que k1 es una función del parámetro de inclinación, y 30 configurado además para modificar un nivel de energía de la subtrama del habla utilizando la ganancia.
5. Sistema de decodificación del habla según la reivindicación 4, en el que:
el calculador de nivel de energía de subtrama alisa el nivel de entrada total utilizando: Level_in_sm = 0,75 * Level_in_sm + 0,25 * gain_in.
6. Sistema de decodificación del habla según la reivindicación 4, en el que el comparador de nivel de energía 35 de subtrama determina que la subtrama del habla está en la zona de silencio utilizando:
(Level_in_sm<1024)&&(gain_in<2*Level_in_sm)&&(parcor0<512/32768).
7. Sistema de decodificación del habla según la reivindicación 4, en el que el modificador del nivel de energía de subtrama asigna Level_in_sm a gain_in (gain_in = Level_in_sm) si Level_in_sm < gain_in.
8. Sistema de decodificación del habla según la reivindicación 7, en el que el calculador del nivel de energía 40 de subtrama está configurado además para sumar un valor absoluto de un nivel de energía para cada una de la pluralidad de muestras salientes, antes de la modificación por parte del modificador del nivel de energía de subtrama, con el fin de generar un nivel de salida total (gain_out), y el modificador del nivel de energía de subtrama está configurado además para determinar una ganancia inicial utilizando (gain_in / gain_out) y modificar la ganancia utilizando la ganancia inicial con el fin de generar una ganancia modificada (g0). 45
9. Sistema de decodificación del habla según la reivindicación 8, en el que el modificador del nivel de energía de subtrama modifica el nivel de energía de subtramas del habla multiplicando sig_out para cada una de la pluralidad de muestras salientes por una ganancia alisada (g_sm), en el que g_sm se obtiene utilizando iteraciones desde 0 a n-1 de (g_sm previa * 0,95 + g0*0,05), en el que n es el número de muestras, y la g_sm previa es cero (0) antes de la primera iteración. 50
Patentes similares o relacionadas:
 CONTROL DE GANANCIA DE AUDIO USANDO DETECCIÓN DE EVENTOS AUDITIVOS BASADA EN LA SONORIDAD ESPECÍFICA, del 27 de Mayo de 2011, de DOLBY LABORATORIES LICENSING CORPORATION: Método para modificar un parámetro de procesamiento dinámico de audio, que comprende: detectar cambios en las características espectrales con respecto […]
CONTROL DE GANANCIA DE AUDIO USANDO DETECCIÓN DE EVENTOS AUDITIVOS BASADA EN LA SONORIDAD ESPECÍFICA, del 27 de Mayo de 2011, de DOLBY LABORATORIES LICENSING CORPORATION: Método para modificar un parámetro de procesamiento dinámico de audio, que comprende: detectar cambios en las características espectrales con respecto […]
 MEJORA DE LA EFICIENCIA DE AMPLIFICADORES DE POTENCIA EN DISPOSITIVOS QUE UTILIZAN LA CONFORMACION DE HAZ, del 15 de Octubre de 2010, de IPR LICENSING, INC.: Un método para optimizar la eficiencia de cada uno de una pluralidad de amplificadores de potencia (110[1]-110[N]), que amplifican las correspondientes […]
MEJORA DE LA EFICIENCIA DE AMPLIFICADORES DE POTENCIA EN DISPOSITIVOS QUE UTILIZAN LA CONFORMACION DE HAZ, del 15 de Octubre de 2010, de IPR LICENSING, INC.: Un método para optimizar la eficiencia de cada uno de una pluralidad de amplificadores de potencia (110[1]-110[N]), que amplifican las correspondientes […]
SISTEMA Y DISPOSITIVO INALÁMBRICO Y PONIBLE PARA REGISTRO, PROCESAMIENTO Y REPRODUCCIÓN DE SONIDOS EN PERSONAS CON DISTROFIA EN EL SISTEMA RESPIRATORIO, del 5 de Marzo de 2020, de ARAGÓN HAN, Daniel: La invención se refiere a un sistema y dispositivo para el registro, procesamiento y reproducción de sonidos en personas con distrofia en el […]
Métodos, aparatos y sistema para codificar y decodificar una señal, del 8 de Enero de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método para codificar una señal, que comprende: realizar un proceso de decisión de clasificación sobre una señal de banda de alta frecuencia de una señal […]
Métodos para codificar y decodificar una señal de audio, decodificador de audio y codificador de audio, del 1 de Enero de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un método para codificar una señal de audio, comprendiendo el método: (a) recibir una señal de audio ; (b) generar una señal de audio codificada; […]
Método y aparato para la mejora multisensorial del habla en un dispositivo móvil, del 13 de Noviembre de 2019, de Zhigu Holdings Limited: Un dispositivo móvil de mano, que comprende: un micrófono de conducción de aire que está configurado para convertir ondas acústicas en una señal […]
Método y dispositivo de enriquecimiento espectral, del 14 de Junio de 2019, de Orange: Procedimiento de enriquecimiento del contenido espectral de una señal que tiene un espectro incompleto incluyendo una primera banda espectral, comprendiendo […]
Transposición armónica basada en bloque de sub bandas mejorada, del 22 de Mayo de 2019, de DOLBY INTERNATIONAL AB: Un sistema configurado para generar una señal transpuesta en frecuencia y/o extendida en el tiempo a partir de una señal de entrada de audio, […]