Método y sistema para la clasificación de datos utilizando un mapa auto-organizativo.
Un método (220) implementado en un ordenador, de etiquetar datos para el entrenamiento de un clasificador,
quecomprende:
obtener datos, comprendiendo los datos datos etiquetados (410) y datos no etiquetados (420);
generar (225) un mapa auto-organizativo de los datos; y
y etiquetar (230) al menos algunos de los datos no etiquetados (510) sobre la base de la proximidad de los datos noetiquetados (510) a los datos etiquetados (501, 502, 503) dentro del mapa auto-organizativo (540) para generardatos auto-etiquetados (520);
donde el etiquetado (230) comprende etiquetar datos no etiquetados asociados con cada uno de una pluralidad denodos (513, 511) en el mapa auto-organizativo (540) con una etiqueta de datos etiquetados asociados con el nodorespectivo (513, 511);
el etiquetado (230) comprende también, para cada vecindad alrededor de un nodo asociado con datos etiquetados,determinar (320) si los datos asociados con nodos dentro de una profundidad de vecindad predeterminada tienendiferentes etiquetas y, si no, etiquetar (325) todos los datos no etiquetados asociados con nodos en la respectivavecindad con la etiqueta de los datos etiquetados en esa vecindad.;
donde el etiquetado (230) comprende también, donde se determina que los nodos dentro de una misma vecindad deprofundidad uno tienen datos etiquetados de manera diferente, no etiquetar (335) datos no etiquetados dentro de losnodos que están dentro de la citada vecindad de profundidad uno,
y si no, si se determina que los nodos dentro de una misma vecindad de profundidad uno no tienen datosetiquetados de manera diferente, entonces donde se determina que los nodos dentro de una misma vecindad que noes de profundidad uno tienen datos etiquetados de manera diferente, etiquetar (340) datos no etiquetados dentro denodos que son adyacentes sólo a uno de los nodos dentro de la misma vecindad que no es de profundidad uno quese ha determinado que tiene datos etiquetados, de manera que a los datos no etiquetados se les asigna la etiquetade los datos etiquetados dentro de un nodo adyacente.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E06119599.
Solicitante: Motorola Mobility LLC .
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 600 North US Highway 45 Libertyville, IL 60048 ESTADOS UNIDOS DE AMERICA.
Inventor/es: DARA,ROZITA A, KHAN,MOHAMMAD TAUSEEF, AZIM,JAWAD, CICCHELLO,ORLANDO, CORT,GARY P.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06K9/62 FISICA. › G06 CALCULO; CONTEO. › G06K RECONOCIMIENTO DE DATOS; PRESENTACION DE DATOS; SOPORTES DE REGISTROS; MANIPULACION DE SOPORTES DE REGISTROS (impresión per se B41J). › G06K 9/00 Métodos o disposiciones para la lectura o el reconocimiento de caracteres impresos o escritos o el reconocimiento de formas, p. ej. de huellas dactilares (métodos y disposiciones para la lectura de grafos o para la conversión de patrones de parámetros mecánicos, p.e. la fuerza o la presencia, en señales eléctricas G06K 11/00; reconocimiento de la voz G10L 15/00). › Métodos o disposiciones para el reconocimiento que utilizan medios electrónicos.
PDF original: ES-2452735_T3.pdf
Fragmento de la descripción:
Método y sistema para la clasificación de datos utilizando un mapa auto-organizativo La presente descripción se refiere en general a métodos y sistemas para la clasificación de datos utilizando un mapa auto-organizativo. En particular, algunas realizaciones utilizan un mapa auto-organizativo para etiquetar al menos algunos datos no etiquetados dentro de un conjunto de datos.
Se ha mostrado que los algoritmos que aprenden de máquinas resultan ser métodos prácticos para problemas de reconocimiento del mundo real. Se ha probado también que son eficientes en dominios que son altamente dinámicos con respecto a muchos valores y condiciones. Algunos algoritmos que aprenden de máquinas son adecuados para clasificación (o modelización predictiva) , mientras que otros han sido desarrollados para propósitos de agrupamiento (o modelización descriptiva) . El agrupamiento se utiliza para generar una visión global de la relación de los registros de datos. La salida de tales algoritmos pueden ser varios grupos, donde cada grupo contiene un conjunto de registros homogéneos. Tal como se aplica a la gestión de relación de abonado (CRM Customer Relationship Management, en inglés) analítica, por ejemplo, los grupos pueden comprender grupos de registros de abonado con características similares. Para agrupamiento, no se necesita ningún dato etiquetado. En clasificación, por otro lado, se necesita un conjunto de categorías conocidas, fijas y un grupo de registros etiquetados (conocidos como datos de entrenamiento) para construir un modelo de clasificación. Los modelos de clasificación pueden ser ampliamente utilizados en los sistemas de CRM analíticos para organizar en categorías los registros de usuario en clases predefinidas.
Uno de los obstáculos para la clasificación es la falta de datos etiquetados disponibles. Un problema que aparece en varios dominios de aplicación es la disponibilidad de grandes cantidades de datos no etiquetados en comparación con los relativamente escasos datos etiquetados. Recientemente, se ha propuesto un aprendizaje semi-supervisado con la promesa de resolver este problema y de acelerar la capacidad de los algoritmos de aprendizaje. El aprendizaje semi-supervisado utiliza datos tanto etiquetados como no etiquetados y puede ser aplicado para mejorar el rendimiento del algoritmo de clasificación y de agrupamiento.
Los datos no etiquetados pueden ser recogidos mediante un medio automatizado de varias bases de datos, mientras que los datos etiquetados pueden requerir la introducción de expertos humanos u otros recursos de categorización limitados o costosos. El hecho de que los datos no etiquetados estén fácilmente disponibles, o no sean costosos de recoger, puede resultar atractivo y puede ser deseable el utilizarlos. No obstante, a pesar del natural atractivo de utilizar datos no etiquetados, no es obvio cómo pueden los registros sin etiquetas ayudar a desarrollar un sistema para el propósito de predecir las etiquetas.
Se presta atención a un artículo titulado "A SOM/MLP Hybrid Network that uses Unlabeled Data to Improve Classification Performance", por Stacey et al publicado en Smart Engineering System Design: Neural Networks, Fuzzy Logic, Evolutionar y Programming, data Mining and Complex Systems Proceedings of the Artificial Neural Networks in Engineering Conference, XX, XX, vol 10, 5 Noviembre de 2000 páginas 179-184, XP008073219. Este documento describe un planteamiento para utilizar datos no etiquetados para ayudar en el entrenamiento de una red neural supervisada, que implica el uso de un mapa auto-organizativo (SOM Self Organizing Map, en inglés) . Los datos son asignados a nodos utilizando el SOM y donde todos los datos etiquetados asignados a un grupo tienen la misma etiqueta, y entonces a los datos no etiquetados asignados al mismo grupo se les da la misma etiqueta. En el caso de nodos ambiguos, los nodos vecinos pueden ser consultados.
DESCRIPCIÓN DE REALIZACIONES PREFERIDAS
Las realizaciones descritas en esta memoria se refieren en general a sistemas y métodos para generar datos de entrenamiento utilizando un mapa auto-organizativo. Los datos de entrenamiento pueden entonces ser utilizados para entrenar a un clasificador para la clasificación de datos. Los datos utilizados para rellenar el mapa autoorganizativo consisten en una pequeña cantidad de datos etiquetados y en una relativamente mucho mayor cantidad de datos no etiquetados. Mediante proximidad de los datos no etiquetados a los datos etiquetados en nodos del mapa auto-organizativo, pueden asignarse etiquetas a los datos no etiquetados. Las realizaciones implementan un modelo de red neural híbrido para combinar un gran conjunto de datos no etiquetados con un pequeño conjunto de registros etiquetados para su uso en clasificación. Pueden aplicarse realizaciones a CRM analítica o en sistemas que rastrean grandes cantidades de datos de usuario, por ejemplo para funciones de auto-rellenado o autoselección.
Pueden aplicarse también realizaciones a varios usos que pueden ser categorizados como aplicaciones de predicción, regresión o modelización. Pueden utilizarse realizaciones en campos en medicina, previsión (por ejemplo, negocios o el tiempo) , ingeniería de software (por ejemplo predicción de defectos de software o modelización de fiabilidad de software) , fabricación (por ejemplo optimización y resolución de problemas) y extracción de datos. Pueden también utilizarse realizaciones en áreas financieras, tal como para calificación crediticia y detección de fraude. Pueden también utilizarse realizaciones en campos de bioinformática, tales como análisis de alineamiento de estructura proteica, estudios de genoma y análisis de micro-matriz.
Algunos usos específicos de realizaciones en el campo de la medicina pueden incluir: localización de características comunes relacionadas con la salud en grandes cantidades de datos; previsión mejorada de resultados sobre la base de los datos existentes, tal como tiempo de recuperación de un paciente o cambios en los ajustes de un dispositivo; predicción de la progresión probable de datos médicos a lo largo del tiempo, tal como el crecimiento de una célula o la dispersión de una enfermedad; identificación de características específicas en imágenes médicas, tal como detección de características de ultrasonidos o de rayos-X; y agrupamiento de datos médicos sobre la base de características claves, tales como condiciones demográficas y pre-existentes.
Ciertas realizaciones pueden referirse a un método de etiquetar datos para entrenamiento de un clasificador, que comprende obtención de datos, comprendiendo los datos datos etiquetados y datos no etiquetados; generar un mapa auto-organizativo de los datos; y etiquetar al menos algunos de los datos no etiquetados sobre la base de la proximidad de los datos no etiquetados a datos etiquetados dentro del mapa auto-organizativo para generar datos auto-etiquetados; donde el etiquetado comprende etiquetar datos no etiquetados asociados con cada uno de una pluralidad de nodos en el mapa auto-organizativo con una etiqueta de datos etiquetados asociados con el nodo respectivo; donde el etiquetado comprende también, para cada vecindad alrededor de un nodo asociado con datos etiquetados, determinar si los datos asociados con nodos dentro de una profundidad de vecindad predeterminada tienen diferentes etiquetas; donde el etiquetado comprende también, donde se determina que los nodos dentro de una misma vecindad de profundidad uno están asociados con diferentes datos etiquetados, no etiquetando datos no etiquetados asociados con nodos que son adyacentes a cualquiera de los nodos dentro de la misma vecindad de profundidad uno que se ha determinado que están asociados con los datos etiquetados; donde el etiquetado comprende también, si no se determina que los nodos dentro de una misma vecindad de profundidad uno están asociados con diferentes datos etiquetados, entonces donde se determina que los nodos dentro de una misma vecindad que no es de profundidad uno están asociados con diferentes datos etiquetados, etiquetar datos no etiquetados asociados con nodos que son adyacentes a sólo uno de los nodos dentro de la misma vecindad que no es de profundidad uno que se determina que están asociados con datos etiquetados, de manera que a los datos no etiquetados se les asigna la etiqueta de los datos etiquetados asociados con el un nodo adyacente. El método puede también comprender entrenar a un clasificador basándose en los datos etiquetados y auto etiquetados.
El etiquetado puede estar basado en una relación de proximidad de datos no etiquetados y etiquetados dentro de una vecindad de nodos del mapa auto-organizativo. La cantidad de datos etiquetados puede ser incrementada añadiendo los datos auto-etiquetados... [Seguir leyendo]
Reivindicaciones:
1. Un método (220) implementado en un ordenador, de etiquetar datos para el entrenamiento de un clasificador, que comprende:
obtener datos, comprendiendo los datos datos etiquetados (410) y datos no etiquetados (420) ;
generar (225) un mapa auto-organizativo de los datos; y
y etiquetar (230) al menos algunos de los datos no etiquetados (510) sobre la base de la proximidad de los datos no etiquetados (510) a los datos etiquetados (501, 502, 503) dentro del mapa auto-organizativo (540) para generar datos auto-etiquetados (520) ;
donde el etiquetado (230) comprende etiquetar datos no etiquetados asociados con cada uno de una pluralidad de nodos (513, 511) en el mapa auto-organizativo (540) con una etiqueta de datos etiquetados asociados con el nodo respectivo (513, 511) ;
el etiquetado (230) comprende también, para cada vecindad alrededor de un nodo asociado con datos etiquetados, determinar (320) si los datos asociados con nodos dentro de una profundidad de vecindad predeterminada tienen diferentes etiquetas y, si no, etiquetar (325) todos los datos no etiquetados asociados con nodos en la respectiva vecindad con la etiqueta de los datos etiquetados en esa vecindad.;
donde el etiquetado (230) comprende también, donde se determina que los nodos dentro de una misma vecindad de profundidad uno tienen datos etiquetados de manera diferente, no etiquetar (335) datos no etiquetados dentro de los nodos que están dentro de la citada vecindad de profundidad uno,
y si no, si se determina que los nodos dentro de una misma vecindad de profundidad uno no tienen datos etiquetados de manera diferente, entonces donde se determina que los nodos dentro de una misma vecindad que no es de profundidad uno tienen datos etiquetados de manera diferente, etiquetar (340) datos no etiquetados dentro de nodos que son adyacentes sólo a uno de los nodos dentro de la misma vecindad que no es de profundidad uno que se ha determinado que tiene datos etiquetados, de manera que a los datos no etiquetados se les asigna la etiqueta de los datos etiquetados dentro de un nodo adyacente.
2. El método de la reivindicación 1, que comprende también entrenar a un clasificador basándose en datos etiquetados y auto-etiquetados.
3. El método de la reivindicación 1 ó la reivindicación 2, en el que el etiquetado (230) se basa en una relación de proximidad de datos no etiquetados y etiquetados dentro de una vecindad de nodos del mapa auto-organizativo.
4. El método de la reivindicación 1 ó la reivindicación 2, en el que la cantidad de datos etiquetados se incrementa añadiendo (350) los datos auto-etiquetados a los datos etiquetados (410) y el etiquetado (230) se repite.
5. El método de la reivindicación 4, donde la generación (225) y/o el etiquetado (230) se repite o repiten hasta que se satisface una condición de terminación predeterminada.
6. El método de una cualquiera de las reivindicaciones 1 a 4, donde la generación y/o el etiquetado (230) se repite o repiten hasta que se satisface una condición de terminación predeterminada.
7. El método de una cualquiera de las reivindicaciones 1 a 5, que comprende también auto-rellenar un campo de datos o una selección de usuario utilizando un clasificador.
8. El método de la reivindicación 3, en el que el etiquetado (230) comprende asignar una clase a los datos autoetiquetados sobre la base de los datos etiquetados en la misma vecindad.
9. El método de cualquiera de las reivindicaciones precedentes, en el que el etiquetado (230) comprende también, para cada vecindad alrededor de un nodo asociado con datos etiquetados, si se determina que los datos asociados con nodos dentro de una profundidad de vecindad predeterminada no tienen etiquetas diferentes, etiquetar (325) todos los datos no etiquetados asociados con nodos en la respectiva vecindad con la etiqueta de los datos etiquetados en esa vecindad.
10. El método de la reivindicación 9, en el que la profundidad de vecindad predeterminada es uno.
11. El método de la reivindicación 9, en el que la profundidad de vecindad predeterminada es dos.
12. El método de una cualquiera de las reivindicaciones 1 a 11, donde los datos etiquetados (410) se generan (220) a partir de los datos no etiquetados (1105) sobre la base de reglas difusas.
13. El método de la reivindicación 12, en el que la generación (220) de los datos etiquetados (410) a partir de datos no etiquetados (1105) comprende:
seleccionar (1110) un conjunto de datos de entrenamiento a partir de datos no etiquetados (1105) ;
establecer (1120) las reglas difusas como un conjunto de reglas para determinar cómo etiquetar los datos de entrenamiento no etiquetados (1110) ; y
asignar (1125) etiquetas a los datos de entrenamiento no etiquetados (1110) basándose en las reglas difusas para 5 generar con ello los datos etiquetados (410) .
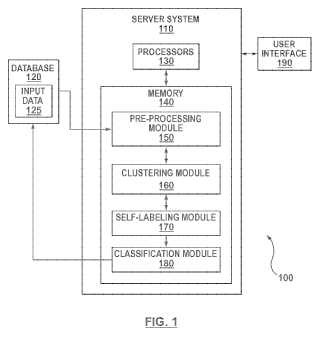
14. Un sistema (100) para etiquetar datos para su uso en la clasificación configurado para llevar a cabo el método de cualquiera de las reivindicaciones 1 a 13.
15. Almacén legible por un ordenador que almacena instrucciones de programa de ordenador (180) las cuales,
cuando son ejecutadas por al menos un procesador (130) , hacen que el al menos un procesador (130) ejecute el 10 método de una cualquiera de las reivindicaciones 1 a 13.
Patentes similares o relacionadas:
Dispositivo de procesamiento de imágenes, método de procesamiento de imágenes y programa, del 29 de Julio de 2020, de RAKUTEN, INC: Dispositivo de procesamiento de imágenes, que comprende: medios de obtención de imágenes captadas para la lectura de datos […]
PROCEDIMIENTO DE IDENTIFICACIÓN DE IMÁGENES ÓSEAS, del 2 de Julio de 2020, de UNIVERSIDAD DE GRANADA: La presente invención tiene por objeto un procedimiento para asistir en la toma de decisiones a un experto forense de cara a la identificación de […]
MÉTODO PARA LA ELIMINACIÓN DEL SESGO EN SISTEMAS DE RECONOCIMIENTO BIOMÉTRICO, del 2 de Julio de 2020, de UNIVERSIDAD AUTONOMA DE MADRID: Método para eliminación del sesgo (por edad, etnia o género) en sistemas de reconocimiento biométrico, que comprende definir un conjunto de M muestras de Y personas […]
Sistema y método para la autenticación biométrica en conexión con dispositivos equipados con cámara, del 19 de Febrero de 2020, de Element, Inc: Un sistema antisuplantación para detectar y usar características tridimensionales de una huella de la palma humana con el fin de proporcionar acceso selectivo a los […]
Detección y seguimiento de objetos en imágenes, del 19 de Febrero de 2020, de QUALCOMM INCORPORATED: Un procedimiento implementado por ordenador que comprende: detectar, dentro de una imagen, un objeto cerca de una superficie usando […]
Caracterización de una colisión de vehículo, del 1 de Enero de 2020, de GEOTAB Inc: Un método que comprende: en respuesta a la obtención de información con respecto a una colisión potencial entre un vehículo y un objeto, obtener, durante un periodo de […]
Un sistema de visualización de información personal y método asociado, del 11 de Diciembre de 2019, de AMADEUS S.A.S.: Un sistema para identificación y/o autenticación de un usuario en una terminal de viaje, comprendiendo el sistema: una base de datos […]
Procedimiento de procesamiento de una señal asíncrona, del 16 de Octubre de 2019, de Sorbonne Université: Procedimiento de reconocimiento de formas en una señal asíncrona producida por un sensor de luz, teniendo el sensor una matriz de píxeles dispuesta frente […]