Método y aparato para procesar una señal de audio.
Método de procesamiento de una señal de audio, que comprende las etapas de:
identificar si un tipo de codificación de la señal de audio es un tipo de codificación de señales musicales utilizando información de un primer tipo;
si el tipo de codificación de la señal de audio no es el tipo de codificación de señales musicales, identificar si el tipo de codificación de la señal de audio es un tipo de codificación de señales de habla o un tipo de codificación de señales mixtas utilizando información de un segundo tipo;
si el tipo de codificación de la señal de audio es el tipo de codificación de señales mixtas, extraer los datos espectrales y un coeficiente de predicción lineal de la señal de audio;
generar una señal residual para predicción lineal llevando a cabo una conversión de frecuencia inversa sobre los datos espectrales;
reconstruir la señal de audio llevando a cabo una codificación de predicción lineal sobre el coeficiente de predicción lineal y la señal residual; y
reconstruir una señal de región de alta frecuencia utilizando una señal de base de extensión correspondiente a una región parcial de la señal de audio reconstruida e información de extensión de banda.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/KR2009/001081.
Solicitante: LG ELECTRONICS INC..
Nacionalidad solicitante: República de Corea.
Dirección: 20, Yeouido-dong, Yeongdeungpo-gu Seoul 150-721 REPUBLICA DE COREA.
Inventor/es: YOON,Sung Yong, LEE,Hyun Kook, KIM,Dong Soo, LIM,Jae Hyun.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L19/00 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H).
- G11B20/10 G […] › G11 REGISTRO DE LA INFORMACION. › G11B REGISTRO DE LA INFORMACION BASADO EN UN MOVIMIENTO RELATIVO ENTRE EL SOPORTE DE REGISTRO Y EL TRANSDUCTOR (registro de valores medidos según un procedimiento que no necesita el uso de un transductor para la reproducción G01D 9/00; aparatos de registro o de reproducción que utilizan una banda marcada por un procedimiento mecánico, p. ej. una banda de papel perforada, o que utilizan soportes de registro individuales, p. ej. fichas perforadas o fichas magnéticas G06K; transferencia de datos de un tipo de soporte de registro a otro G06K 1/18; circuitos para el acoplamiento de la salida de un dispositivo de reproducción a un receptor radio H04B 1/20; cabezas de lectura para gramófonos o transductores acústicos electromecánicos o sus circuitos H04R). › G11B 20/00 Tratamiento de la señal, no específica del procedimiento de registro o reproducción; Circuitos correspondientes. › Registro o reproducción digitales.
- H03M7/30 ELECTRICIDAD. › H03 CIRCUITOS ELECTRONICOS BASICOS. › H03M CODIFICACION, DECODIFICACION O CONVERSION DE CODIGO, EN GENERAL (por medio de fluidos F15C 4/00; convertidores ópticos analógico/digitales G02F 7/00; codificación, decodificación o conversión de código especialmente adaptada a aplicaciones particulares, ver las subclases apropiadas, p. ej. G01D, G01R, G06F, G06T, G09G, G10L, G11B, G11C, H04B, H04L, H04M, H04N; cifrado o descifrado para la criptografía o para otros fines que implican la necesidad de secreto G09C). › H03M 7/00 Conversión de un código, en el cual la información está representada por una secuencia dada o por un número de dígitos, en un código en el cual la misma información está representada por una secuencia o por un número de dígitos diferentes. › Compresión (análisis-síntesis de la voz para reducción de redundancia G10L 19/00; para transmisión de imágenes H04N ); Expansión; Supresión de datos innecesarios, p. ej. reducción de redundancia.
- H04N7/24 H […] › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04N TRANSMISION DE IMAGENES, p. ej. TELEVISION. › H04N 7/00 Sistemas de televisión (detalles H04N 3/00, H04N 5/00; métodos y arreglos, para la codificación, decodificación, compresión o descompresión de señales de vídeo digital H04N 19/00; distribución selectiva de contenido H04N 21/00). › Sistemas para la transmisión de señales de televisión que utilizan la modulación por impulsos codificados (H04N 21/00 tiene prioridad).
PDF original: ES-2464722_T3.pdf
Fragmento de la descripción:
Método y aparato para procesar una señal de audio.
Antecedentes de la invención Campo de la invención La presente invención se refiere a un aparato de procesamiento de señales de audio para codificar y decodificar varios tipos de señales de audio de manera eficaz, y a un método para ello.
Exposición de la técnica relacionada En general, las tecnologías de codificación se clasifican convencionalmente en dos tipos, tales como los codificadores de audio perceptuales y los codificadores basados en la predicción lineal. Por ejemplo, el codificador de audio perceptual, optimizado para música, adopta un esquema en el que se reduce el tamaño de la información en un proceso de codificación usando el principio del enmascaramiento, el cual constituye una teoría de sicoacústica auditiva humana, sobre un eje de frecuencia. Por el contrario, el codificador basado en la predicción lineal, optimizado para el habla, adopta un esquema en el que se reduce el tamaño de la información modelando la vocalización del habla sobre un eje de tiempo.
No obstante, cada una de las tecnologías descritas anteriormente presenta un buen rendimiento sobre cada señal de audio optimizada (por ejemplo, una señal de habla, una señal de música) , pero no consigue proporcionar un rendimiento uniforme sobre una señal de audio generada a partir de una mezcla complicada de diferentes tipos de señales de audio o señales de habla y música juntas.
En la técnica anterior, el documento EP 1 278 184 A2 da a conocer un códec híbrido que proporciona codificación por transformada para señales musicales y utiliza un filtro de síntesis de LP con Predicción Lineal, común, para señales tanto de habla como musicales.
Sumario de la invención Por lo tanto, la presente invención se refiere a un método de procesamiento de una señal de audio según se reivindica en las reivindicaciones 1 y 13, y a un aparato para el mismo según se reivindica en las reivindicaciones 7 y 14, que sustancialmente eliminan uno o más de los problemas debidos a limitaciones y desventajas de las anterioridades.
Un objetivo de la presente invención es proporcionar un aparato para procesar una señal de audio y un método para ello, mediante los cuales se pueden comprimir y/o reconstruir tipos diferentes de señales de audio con una mayor eficiencia.
Otro objetivo de la presente invención es proporcionar un esquema de codificación de audio adecuado para características de una señal de audio.
En la descripción que se proporciona a continuación, se expondrán características y ventajas adicionales de la invención, y las mismas, en parte, resultarán evidentes a partir de la descripción, o se pueden asimilar poniendo en práctica la invención. Los objetivos y otras ventajas de la invención se materializarán y obtendrán por medio de la estructura indicada particularmente en la descripción redactada y en las reivindicaciones de la misma, así como en los dibujos adjuntos.
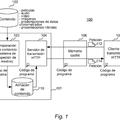
Para lograr estas y otras ventajas y, de acuerdo con el objetivo de la presente invención, según se materializa y describe ampliamente, un método de procesamiento de una señal de audio según la presente invención incluye las etapas de identificar si un tipo de codificación de la señal de audio es un tipo de codificación de señales musicales usando información de un primer tipo, si el tipo de codificación de la señal de audio no es el tipo de codificación de señales musicales, identificar si el tipo de codificación de la señal de audio es un tipo de codificación de señales de habla o un tipo de codificación de señales mixtas usando información de un segundo tipo, si el tipo de codificación de la señal de audio es el tipo de codificación de señales mixtas, extraer datos espectrales y un coeficiente de predicción lineal a partir de la señal de audio, generar una señal residual para predicción lineal llevando a cabo una conversión de frecuencia inversa sobre los datos espectrales, reconstruir la señal de audio llevando a cabo una codificación de predicción lineal sobre el coeficiente de predicción lineal y la señal residual, y reconstruir una señal de región de alta frecuencia usando una señal de base de extensión correspondiente a una región parcial de la señal de audio reconstruida e información de extensión de banda.
Para lograr adicionalmente estas y otras ventajas y de acuerdo con el objetivo de la presente invención, un aparato para procesar una señal de audio incluye un demultiplexor que extrae información de un primer tipo e información de un segundo tipo a partir de un flujo continuo de bits, una unidad de determinación de decodificador que identifica si un tipo de codificación de la señal de audio es un tipo de codificación de señales musicales usando información del primer tipo, de manera que, si el tipo de codificación de la señal de audio no es el tipo de codificación de señales musicales, el decodificador identifica si el tipo de codificación de la señal de audio es un tipo de codificación de señales de habla o un tipo de codificación de señales mixtas usando información del segundo tipo, determinando a continuación el decodificador un esquema de decodificación, una unidad de extracción de información, si el tipo de codificación de la señal de audio es el tipo de codificación de señales mixtas, que extrae datos espectrales y un coeficiente de predicción lineal a partir de la señal de audio, una unidad de transformación de frecuencias que genera una señal residual para predicción lineal llevando a cabo una conversión de frecuencia inversa sobre los datos espectrales, una unidad de predicción lineal que reconstruye la señal de audio llevando a cabo una codificación de predicción lineal sobre el coeficiente de predicción lineal y la señal residual, y una unidad de decodificación de extensión de ancho de banda que reconstruye una señal de región de alta frecuencia usando una señal de base de extensión correspondiente a una región parcial de la señal de audio reconstruida e información de extensión de banda.
Preferentemente, la señal de audio incluye una pluralidad de subtramas y en donde la información del segundo tipo existe por una unidad de la subtrama.
Preferentemente, un ancho de banda de la señal de región de alta frecuencia no es igual al de la señal de base de extensión. Preferentemente, la información de extensión de banda incluye por lo menos uno de un rango de filtro aplicado a la señal de audio reconstruida, una frecuencia de inicio de la señal de base de extensión y una frecuencia final de la señal de base de extensión.
Preferentemente, si el tipo de codificación de la señal de audio es el tipo de codificación de señales musicales, la señal de audio comprende una señal en el dominio de la frecuencia, en donde si el tipo de codificación de la señal de audio es el tipo de codificación de señales de habla, la señal de audio comprende una señal en el dominio del tiempo, y en donde si el tipo de codificación de la señal de audio es el tipo de codificación de señales mixtas, la señal de audio comprende una señal en el dominio de MDCT.
Preferentemente, la extracción del coeficiente de predicción lineal incluye extraer un modo de coeficiente de predicción lineal y extraer el coeficiente de predicción lineal que tiene un tamaño de bits variable correspondiente al modo extraído del coeficiente de predicción lineal.
Debe apreciarse que tanto la anterior descripción general como la siguiente descripción detallada son ejemplificativas y explicativas, y están destinadas a proporcionar una explicación adicional de la invención según se reivindica.
Breve descripción de los dibujos Los dibujos adjuntos, que se incluyen para proporcionar una comprensión adicional de la invención y se incorporan a la presente memoria descriptiva formando parte de la misma, ilustran formas de realización de la invención y, junto con la descripción, sirven para explicar los fundamentos de la invención.
En los dibujos:
la figura 1 es un diagrama de bloques de un aparato de codificación de audio según una forma de realización de la presente invención;
la figura 2 es un diagrama de bloques de un aparato de codificación de audio según otra forma de realización de la presente invención;
la figura 3 es un diagrama de bloques detallado de una unidad de preprocesamiento de ancho de banda 150 según una forma de realización de la presente invención;
la figura 4 es un diagrama de flujo para un método de codificación de una señal de audio usando información del tipo de audio según una forma de realización de la presente invención;
la figura 5 es un diagrama para un... [Seguir leyendo]
Reivindicaciones:
1. Método de procesamiento de una señal de audio, que comprende las etapas de:
identificar si un tipo de codificación de la señal de audio es un tipo de codificación de señales musicales utilizando información de un primer tipo;
si el tipo de codificación de la señal de audio no es el tipo de codificación de señales musicales, identificar si el tipo de codificación de la señal de audio es un tipo de codificación de señales de habla o un tipo de codificación de señales mixtas utilizando información de un segundo tipo;
si el tipo de codificación de la señal de audio es el tipo de codificación de señales mixtas, extraer los datos espectrales y un coeficiente de predicción lineal de la señal de audio;
generar una señal residual para predicción lineal llevando a cabo una conversión de frecuencia inversa sobre los datos espectrales;
reconstruir la señal de audio llevando a cabo una codificación de predicción lineal sobre el coeficiente de predicción lineal y la señal residual; y
reconstruir una señal de región de alta frecuencia utilizando una señal de base de extensión correspondiente a una región parcial de la señal de audio reconstruida e información de extensión de banda.
2. Método según la reivindicación 1, en el que la señal de audio incluye una pluralidad de subtramas y en el que la 25 información del segundo tipo existe por una unidad de la subtrama.
3. Método según la reivindicación 1, en el que un ancho de banda de la señal de región de alta frecuencia no es igual al de la señal de base de extensión.
4. Método según la reivindicación 1, en el que la información de extensión de banda incluye por lo menos uno de un rango de filtro aplicado a la señal de audio reconstruida, una frecuencia de inicio de la señal de base de extensión y una frecuencia final de la señal de base de extensión.
5. Método según la reivindicación 1, en el que si el tipo de codificación de la señal de audio es el tipo de
codificación de señales musicales, la señal de audio comprende una señal en el dominio de la frecuencia, en el que si el tipo de codificación de la señal de audio es el tipo de codificación de señales de habla, la señal de audio comprende una señal en el dominio del tiempo, y en el que si el tipo de codificación de la señal de audio es el tipo de codificación de señales mixtas, la señal de audio comprende una señal en el dominio de MDCT.
6. Método según la reivindicación 1, comprendiendo la etapa de extracción del coeficiente de predicción lineal las etapas de:
extraer un modo de coeficiente de predicción lineal; y
extraer el coeficiente de predicción lineal que presenta un tamaño de bits variable correspondiente al modo de coeficiente de predicción lineal extraído.
7. Aparato para procesar una señal de audio, que comprende:
un demultiplexor (210) configurado para extraer información de un primer tipo e información de un segundo tipo a partir de un flujo continuo de bits;
una unidad de determinación de decodificador (220) configurada para identificar si un tipo de codificación de la señal de audio es un tipo de codificación de señales musicales utilizando información del primer tipo, estando 55 configurada además la unidad de determinación de decodificador (220) , si el tipo de codificación de la señal de audio no es el tipo de codificación de señales musicales, para identificar si el tipo de codificación de la señal de audio es un tipo de codificación de señales de habla o un tipo de codificación de señales mixtas utilizando información del segundo tipo, estando configurada además la unidad de determinación de decodificador (220) para determinar a continuación un esquema de decodificación;
una unidad de extracción de información (233) configurada, si el tipo de codificación de la señal de audio es el tipo de codificación de señales mixtas, para extraer los datos espectrales y un coeficiente de predicción lineal de la señal de audio;
una unidad de transformación de frecuencias (235) configurada para generar una señal residual para predicción lineal llevando a cabo una conversión de frecuencia inversa sobre los datos espectrales;
una unidad de predicción lineal (236) configurada para reconstruir la señal de audio llevando a cabo una codificación de predicción lineal sobre el coeficiente de predicción lineal y la señal residual; y
una unidad de decodificación de extensión de ancho de banda (250) configurada para reconstruir una señal de región de alta frecuencia utilizando una señal de base de extensión correspondiente a una región parcial de la señal de audio reconstruida e información de extensión de banda.
8. Aparato según la reivindicación 7, en el que la señal de audio incluye una pluralidad de subtramas y en el que la información del segundo tipo existe por una unidad de una subtrama.
9. Aparato según la reivindicación 7, en el que un ancho de banda de la señal de región de alta frecuencia no es igual al de la señal de base de extensión.
10. Aparato según la reivindicación 7, en el que la información de extensión de banda incluye por lo menos uno de un rango de filtro aplicado a la señal de audio reconstruida, una frecuencia de inicio de la señal de base de extensión y una frecuencia final de la señal de base de extensión.
11. Aparato según la reivindicación 7, en el que si el tipo de codificación de la señal de audio es el tipo de codificación de señales musicales, la señal de audio comprende una señal en el dominio de la frecuencia, en el que si el tipo de codificación de la señal de audio es el tipo de codificación de señales de habla, la señal de audio comprende una señal en el dominio del tiempo, y en el que si el tipo de codificación de la señal de audio es el tipo de codificación de señales mixtas, la señal de audio comprende una señal en el dominio de MDCT.
12. Aparato según la reivindicación 7, en el que la unidad de extracción de información (233) está configurada para extraer un modo de coeficiente de predicción lineal; y
extraer el coeficiente de predicción lineal que presenta un tamaño de bits variable correspondiente al modo del coeficiente de predicción lineal extraído.
13. Método de procesamiento de una señal de audio, que comprende las etapas de:
eliminar de una señal de frecuencia de una señal de submezcla de la señal de audio una señal de alta frecuencia de la señal de audio correspondiente a una región de alta frecuencia y generar información de extensión de banda para reconstruir la señal de banda de alta frecuencia y dar salida a una señal de submezcla de baja frecuencia de la señal de audio;
determinar un tipo de codificación de la señal de audio;
si la señal de audio es una señal musical, generar información de un primer tipo que indica que la señal de audio se codifica en un tipo de codificación de señales musicales;
si la señal de audio no es la señal musical, generar información de un segundo tipo que indica que la señal de 45 audio se codifica o bien en un tipo de codificación de señales de habla o bien en un tipo de codificación de señales mixtas;
si el tipo de codificación de la señal de audio es el tipo de codificación de señales mixtas, generar un coeficiente de predicción lineal llevando a cabo una codificación de predicción lineal sobre la señal de submezcla de baja frecuencia de la señal de audio;
generar una señal residual para la codificación de predicción lineal utilizando la señal de submezcla de baja frecuencia;
generar un coeficiente espectral mediante una transformación de frecuencia de la señal residual; y
generar un flujo continuo de bits de audio que incluye la información del primer tipo, la información del segundo tipo, el coeficiente de predicción lineal y la señal residual.
14. Aparato para procesar una señal de audio, que comprende:
una unidad de preprocesamiento de ancho de banda (150) configurada para eliminar de una señal de frecuencia de una señal de submezcla de la señal de audio una señal de alta frecuencia de la señal de audio correspondiente a una región de alta frecuencia y dar salida a una señal de baja frecuencia de la señal de audio,
estando configurada además la unidad de preprocesamiento de ancho de banda (150) para generar información de extensión de banda con el fin de reconstruir la señal de alta frecuencia;
una unidad de clasificación de señales (100) configurada para determinar un tipo de codificación de la señal de audio, estando configurada además la unidad de clasificación de señales (100) , si la señal de audio es una señal musical, para generar información de un primer tipo que indica que la señal de audio está codificada en un tipo de codificación de señales musicales, estando configurada además la unidad de clasificación de señales (100) , si la señal de audio no es la señal musical, para generar información de un segundo tipo que indica que la señal de audio está codificada o bien en un tipo de codificación de señales de habla o bien un tipo de codificación de señales mixtas;
una unidad de modelado de predicción lineal (110) configurada, si el tipo de codificación de la señal de audio es el tipo de codificación de señales mixtas, para generar un coeficiente de predicción lineal llevando a cabo una codificación de predicción lineal sobre la señal de submezcla de baja frecuencia de la señal de audio;
una unidad de extracción de señales residuales (132) configurada para generar una señal residual para la 15 codificación de predicción lineal usando la señal de submezcla de baja frecuencia; y
una unidad de transformación de frecuencias (133) configurada para generar un coeficiente espectral mediante la transformación de frecuencias de la señal residual.
15. Aparato según la reivindicación 14, en el que la señal de audio incluye una pluralidad de subtramas, y en el que la información del segundo tipo se genera por una unidad de una subtrama.
Patentes similares o relacionadas:
Procedimiento de transferencia de datos y aparato que opera insertando otro contenido en el contenido principal, del 17 de Junio de 2020, de SAMSUNG ELECTRONICS CO., LTD.: Un procedimiento de reproducción de datos multimedia, por un cliente, comprendiendo el procedimiento: solicitar y recibir un primer archivo que […]
Procedimiento y aparato para la encapsulación de activos de transporte de medios del grupo de expertos en imágenes en movimiento dentro de la organización internacional de normalización de archivos de medios de base, del 6 de Mayo de 2020, de SAMSUNG ELECTRONICS CO., LTD.: Un procedimiento para transmitir datos de medios mediante una entidad emisora en un sistema de transporte de medios MMT de MPEG, comprendiendo el […]
Sincronización de flujo modificado, del 6 de Mayo de 2020, de KONINKLIJKE KPN N.V.: Método para permitir la sincronización entre destinos de al menos un primer y al menos un segundo flujo, estando asociado dicho segundo flujo con el […]
Sistema y método para codificación y decodificación aritmética, del 29 de Abril de 2020, de NTT DOCOMO, INC.: Método de decodificación aritmética para convertir una secuencia de información compuesta por una secuencia de bits en una secuencia de eventos binarios compuesta […]
Adaptación de un flujo de datos escalables con inclusión de unas retransmisiones, del 19 de Febrero de 2020, de Orange: Un procedimiento de adaptación de un flujo de datos escalable que comprende unas primeras unidades de datos (O_Data) y que define una pluralidad […]
 Transmisión de solicitud de bloque mejorada usando http cooperativa paralela y corrección de errores hacia adelante, del 30 de Octubre de 2019, de QUALCOMM INCORPORATED: Un procedimiento para su uso en un sistema de comunicación en el que un dispositivo cliente solicita segmentos de medios desde un sistema de ingestión […]
Transmisión de solicitud de bloque mejorada usando http cooperativa paralela y corrección de errores hacia adelante, del 30 de Octubre de 2019, de QUALCOMM INCORPORATED: Un procedimiento para su uso en un sistema de comunicación en el que un dispositivo cliente solicita segmentos de medios desde un sistema de ingestión […]
Sistema de demanda y reproducción de medios, del 23 de Octubre de 2019, de Sky CP Limited: Un receptor de medios adaptado para reproducir elementos de contenido de medios primarios y secundarios recibidos de un servidor de medios en respuesta a una […]
 Procedimiento de presentación de flujos de velocidad adaptativa, del 28 de Agosto de 2019, de DISH Technologies L.L.C: Un procedimiento de presentación de flujos de velocidad adaptativa, comprendiendo el procedimiento: transmitir mediante un reproductor multimedia que opera en una […]
Procedimiento de presentación de flujos de velocidad adaptativa, del 28 de Agosto de 2019, de DISH Technologies L.L.C: Un procedimiento de presentación de flujos de velocidad adaptativa, comprendiendo el procedimiento: transmitir mediante un reproductor multimedia que opera en una […]