Método implementado por ordenador para recuperación de imágenes por contenido y programa de ordenador del mismo.
Método implementado por ordenador y programa de ordenador para recuperación de imágenes por contenido.
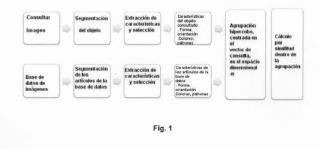
El método comprende seleccionar y segmentar una imagen consultada; extraer características mediante el cálculo de al menos dos descriptores de características incluyendo color y textura; y determinar la similitud de la imagen consultada con una pluralidad de imágenes incluidas en una base de datos que contiene imágenes, dicha pluralidad de imágenes incluyendo también características extraídas calculadas por dichos al menos dos descriptores. Los citados descriptores de características de color y textura calculados se combinan en diferentes espacios de color, los cuales comprenden unas medidas estadísticas globales y locales en dichos espacios, proporcionando un descriptor semántico de alto nivel invariante.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P201300816.
Solicitante: SHOT & SHOP. S.L.
Nacionalidad solicitante: España.
Inventor/es: PÉREZ DE LA COBA,Sira.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F17/30
Fragmento de la descripción:
Método implementado por ordenador para recuperación de imágenes por contenido v programa de ordenador del mismo
Campo de la invención
Esta invención concierne al campo de las tecnologías para reconocimiento visual de objetos e imágenes. Particularmente, la invención concierne a un método implementado por ordenador y a un programa de ordenador para recuperación de imágenes por contenido, basado principalmente en descriptores visuales únicos. Asimismo también se utilizan herramientas basadas en una similitud subjetiva y objetiva, y en un cálculo optimizado de la distancia entre imagen consultada y potenciales similares.
Antecedentes
El reconocimiento visual es cada día más importante en nuestra sociedad debido a la implantación de los ordenadores y al ámbito virtual.
El campo de aplicación de los motores de búsqueda visual y de las tecnologías de visión artificial, reconocimiento de objetos y patrones es amplio y ya se ha extendido a una diversidad de diferentes funcionalidades y sectores tales como: visión industrial y por ordenador, navegación, control de procesos, seguridad nacional, comercio electrónico, diagnóstico médico, investigación biológica, identificación de personas y biometría, marketing, redes sociales, etc.
Especialmente el uso de la búsqueda visual para su uso en la identificación y similitud es un campo con múltiples intereses, donde las aplicaciones comerciales se han desarrollado en las últimas décadas debido al incremento de las imágenes y vídeos digitales, el uso de Internet y las últimas tecnologías de los teléfonos inteligentes, PDAs, etc. que incluyen cámaras cada vez más avanzadas.
La primera aproximación para solucionar el problema de la búsqueda visual fue la recuperación por texto, donde las imágenes se indexan usando palabras clave, códigos de clasificación o títulos en el mensaje. Las principales limitaciones de estas tecnologías son dos; la primera, que se necesita indexar y etiquetar las imágenes, lo que supone emplear mucho tiempo y recursos, y la segunda, que no es un método estándar, ya que cada usuario puede interpretar, definir y describir subjetivamente las imágenes de forma diferente.
Una alternativa a la recuperación basada en el texto es la técnica de Recuperación de Imágenes Por Contenido (CBIR) que recupera imágenes relevantes
de forma semántica de una base de datos de imágenes basándose en características de imagen que se derivan automáticamente.
El procesamiento de imágenes es muy complejo, aparte del volumen que ocupan, existe el gran desafío de trasladar de forma eficaz percepciones de alto nivel a características de imagen de bajo nivel y solucionar el conocido intervalo semántico. Los objetivos a conseguir con estas tecnologías son:
Debería tener un tiempo de respuesta menor
Debería ser preciso
Debería ser sencillo consultar la recuperación de una imagen
Debería ser robusto e invariante a los distintos entornos, condiciones de captura de imagen y cambios de perspectiva
Debería ser escalable a grandes bases de datos y flexible y extensible a otros tipos de objetos, imágenes y/o patrones
Dentro de los sistemas CBIR, uno de los puntos fundamentales para su buen funcionamiento es la definición y extracción de las características de las imágenes, es decir, la definición de los vectores óptimos y adecuados, también llamados descriptores, que describan de la forma más completa y precisa, la información visual de la imagen o región que representan, con la mínima cantidad de datos necesarios, y con el fin de reconocer, identificar, ordenar o clasificar la imagen u objeto de interés y/o sus similares, mediante métodos eficaces de búsqueda y comparación sobre grandes bases de datos de imágenes.
Algunas de las tecnologías desarrolladas se basan en comparaciones directas, coincidencias de patrones (pattern matching) o métodos de correlación aplicados a las imágenes completas o a las ventanas de imágenes completas / regiones de interés (ROI). Dichos enfoques son precisos y están bien adaptados para estudiar la estructura global de un objeto concreto, previamente conocido, acotado y entrenado, o patrones estáticos fijos, pero no pueden afrontar la oclusión parcial, cambios importantes en la perspectiva u objetos deformables (de K. Grauman and B. Leibe Chaper 3 Local Features: Detection and Description.. Visual Object Recognition. Synthesis Lectures on Artificial Intelligence and Machine Leaming, Morgan & Claypool (2011)). Además, normalmente no resisten los cambios de iluminación o la presencia de ruido de elementos extraños, por lo que la flexibilidad y escalabilidad de estos sistemas es muy costosa, y por tanto, su aplicación en CBIR es bastante cuestionable.
Otro de los factores clave en la definición de los descriptores adecuados para los sistemas CBIR es que sean invariantes, lo que significa que no se vean afectados
por parámetros sensibles a las diferentes condiciones o entornos de captura de la imagen u objeto, como son la iluminación, rotación, escala, reversión, traslación, transformaciones afines, y otros efectos.
Como alternativa, se busca desarrollar sistemas CBIR donde se implementen descriptores basados en características simples (Low level features) que sean invariantes, para que, por un lado, describan de forma robusta las imágenes u objetos bajo distintos contextos y condiciones de captura, y por otro lado, eviten el uso y análisis de características de alto nivel, (High level features), que son más complejas y costosas, tanto a nivel de implementación como de consumo y procesamiento necesario.
El uso de los vectores formados por estas características de bajo nivel (Low level features) consiste en indexar propiedades visuales, usando valores numéricos para describir dichas características, representando después la imagen u objeto como un punto en un espacio N-dimensional. El proceso consiste en extraer las características del vector de la imagen u objeto consultado, y aplicar los sistemas de medición y métodos de clasificación para analizar la similitud conforme a la base de datos.
Actualmente hay métodos algorítmicos para extraer este tipo de características invariantes de las imágenes como son Scale-invariant feature transform (or SIFT), G- RIF: Generalized Robust Invariant Feature, SURF Speeded Up Robust Features", PCA-SIFT, GLOH, etc. Sin embargo estos métodos describen la apariencia local concreta de objetos o regiones específicas de las imágenes, a partir de la selección de un conjunto de puntos de interés, obtenidos mediante métodos de entrenamiento aplicados sobre dichas imágenes, previamente conocidas y acotadas, y por tanto no siendo extensibles a otros objetos y categorías sin el entrenamiento previo correspondiente.
En este contexto, los principales desafíos afrontados, son la especificación de estructuras de indexación que permitan acelerar la recuperación de imágenes con métodos flexibles y escalables.
Así pues, otra alternativa de características de bajo nivel son los descriptores de características tipo color, forma, textura, etc., que permiten desarrollar vectores genéricos aplicables a imágenes y objetos de distinta naturaleza. Entre los métodos de optimización de dichos vectores/descriptores, se persigue obtener la máxima información con el mínimo número de parámetros o variables incluidos en los mismos, utilizando para ello métodos de selección para determinar las características más
importantes y sus combinaciones para describir y consultar artículos en grandes bases de datos, reduciendo la complejidad (de tiempo y procesamiento a nivel computacional) de búsqueda y recuperación, al tiempo que intentando mantener un alto rendimiento de precisión. Además, ayuda a los usuarios finales al asociar automáticamente las características y medidas adecuadas de una base de datos determinada (I.Guyon and A.Elisseff.An Introduction to Variable and Feature Selection.2003) Journal of Machine Learning Research 3 (1157-1182).). Estos se pueden dividir en dos grupos:
Los métodos de transformación de características tales como PCA e ICA hacen corresponder el espacio de características original con el espacio dimensional más bajo y construyen nuevos vectores de características. El problema de los algoritmos de transformación de características es su sensibilidad al ruido y las características resultantes no transmiten ningún significado para el usuario.
Los esquemas de selección de características son sólidos contra el ruido y las características resultantes son altamente interpretables. El objetivo de la selección de características es elegir un subconjunto de características...
Reivindicaciones:
1. Método implementado por ordenador para recuperación de imágenes por contenido, del tipo que comprende:
a) seleccionar una imagen consultada;
b) segmentar, mediante la aplicación de una técnica de segmentación, dicha imagen consultada;
c) extraer características de dicha imagen consultada segmentada mediante el cálculo de al menos dos descriptores de características incluyendo color y textura; y
d) determinar la similitud de la imagen consultada con una pluralidad de imágenes incluidas en una base de datos, las cuales incluyen también características extraídas calculadas por dichos al menos dos descriptores,
estando el método caracterizado porque en dicha etapa c) dichos descriptores de características de color y textura calculados incluyen la combinación de diferentes espacios de color, los cuales comprenden unas medidas estadísticas globales y locales en dichos espacios, dando como resultado un descriptor semántico de alto nivel, invariante.
2. Método implementado por ordenador según la reivindicación 1, caracterizado porque además dichos descriptores de características de color y textura están combinados con al menos unos descriptores de forma y orientación proporcionando un descriptor de forma/geometría y orientación, invariante.
3. Método implementado por ordenador según la reivindicación 1, caracterizado porque comprende calcular la media y la varianza de la imagen consultada para dichos espacios de color diferentes.
4. Método implementado por ordenador según la reivindicación 3, caracterizado porque comprende además calcular una región de interés (ROI) de un determinado tamaño de píxeles de la imagen consultada para diferenciar diferentes regiones de color o textura en la imagen consultada, en donde dicha ROI calculada es aquella que cumple unos valores de media y varianza con una distancia Euclídea más cercana a dichos valores de media y varianza calculados de la imagen consultada.
5. Método implementado por ordenador según la reivindicación 4, caracterizado porque el tamaño de la ROI calculada es de al menos 9x9 píxeles.
6. Método implementado por ordenador según la reivindicación 1, caracterizado porque dichos espacios de color diferentes comprenden al menos HSV, CieLAB o CieXYZ.
7. Método implementado por ordenador según la reivindicación 2, caracterizado porque dicho descriptor de características de forma comprende utilizar los momentos de Hu invariantes y de bajo nivel y otros parámetros no lineales y adimensionales relacionados con el volumen del objeto, basados en áreas como las envolventes convexas, excentricidades, otras formas derivadas y sus ratios relacionados con el objeto.
8. Método implementado por ordenador según la reivindicación 7, caracterizado porque comprende calcular:
- perímetros equivalentes basados en ratios y formas locales detalladas para los contornos internos y otras variables de alto nivel; y/o
- áreas de los defectos de convexidad y ratios lineales relacionados para los bordes internos y externos, convexidades y excentricidades.
9. Método implementado por ordenador según la reivindicación 2, caracterizado porque dicho descriptor de características de orientación se calcula al menos en base a un valor del ángulo, de un primer componente, de un procedimiento estadístico PCA.
10. Método implementado por ordenador según la reivindicación 1, caracterizado porque dicha similitud se determina en base a una medición en el espacio, en tiempo real y aplicada dentro de una agrupación hipercubo, en donde la agrupación hipercubo está:
centrada en la posición del espacio de la imagen de consulta, definida por un vector de radio n-dimensional del total de n-dimensiones de dichos dos descriptores juntos, con valores de radio independientes y diferentes para cada dimensión,
basada en un porcentaje de distancia aceptado del valor de la posición de dicha imagen de consulta, y
limitada al cálculo de distancias 1:1 de la imagen de consulta dentro de la agrupación.
11. Método implementado por ordenador según la reivindicación 10, caracterizado porque dicho vector de radio n-dimensional se calcula para cada dimensión a partir de al menos la posición de dicha imagen consultada.
12. Método implementado por ordenador según la reivindicación 1, caracterizado porque los descriptores de dicha etapa c) se optimizan mediante la aplicación de técnicas de transformación y métodos de filtrado a partir de métodos de clasificación estadística en un análisis de regresión logística multi-variante.
13. Programa de ordenador que comprende código adaptado para realizar las etapas c) y d) del método según la reivindicación 1 cuando se ejecuta en un dispositivo de computación, en un procesador digital de señal, en un circuito específico integrado, en un microcontrolador u otra forma de sistema de procesamiento de datos.
Patentes similares o relacionadas:
Composiciones y métodos para modelar el metabolismo de Saccharomyces cerevisiae, del 3 de Junio de 2020, de THE REGENTS OF THE UNIVERSITY OF CALIFORNIA: Un metodo implementado por computadora para proporcionar a un usuario una simulacion de una funcion fisiologica de levadura relacionada con un gen heterologo […]
Procedimiento de visualización de páginas por medio de un navegador de un equipo como una caja descodificadora Proveedor de Servicios de Internet, del 10 de Enero de 2020, de FREEBOX (100.0%): Un procedimiento de visualización de páginas por un equipo cliente equipado de un sistema cerrado, conectado a un servidor remoto , integrando […]
Procedimiento implementado por ordenador y controlado por ordenador, producto de programa informático y plataforma para disponer datos para su procesamiento y almacenamiento en un motor de almacenamiento de datos, del 4 de Noviembre de 2019, de Dynactionize N.V: Un procedimiento implementado por ordenador y controlado por ordenador de disposición de datos para procesamiento y almacenamiento de los mismos en un […]
MÉTODO DE DOBLAJE Y LOCUCIONES DE AUDIO, del 11 de Julio de 2019, de TANGO VOZ, S.L: Se describe en este documento un método que permite gestionar la producción de doblajes y locuciones de audio destinados a medios audiovisuales de tal manera que no se […]
Un sistema de control para controlar el funcionamiento de una unidad de procesamiento de datos, del 21 de Mayo de 2019, de IG Knowhow Limited: Un sistema de control para controlar el funcionamiento de una unidad de procesamiento de datos, la unidad de procesamiento de datos recibiendo una primera […]
Dispositivo de procesamiento de información, método de procesamiento de información, programa de procesamiento de información y soporte de registro, del 1 de Mayo de 2019, de RAKUTEN, INC: Dispositivo de procesamiento de información que comprende: un medio (12b) de memoria de palabra de área local que almacena una palabra de área […]
Método para proporcionar una estructura de índice en una base de datos, del 1 de Mayo de 2019, de Capish International AB: Metodo para proporcionar una estructura de indice en una base de datos que comprende una pluralidad de tipos de objetos, donde cada tipo de objetos […]
SISTEMA PARA LA DETECCIÓN REMOTA DEL USO DEL CINTURÓN DE SEGURIDAD EN UN VEHÍCULO, del 18 de Abril de 2019, de CASANOVA RENT VOLKS, S.A. DE C.V: La presente invención se refiere a la industria automotriz, particularmente está relacionada con los cinturones de seguridad con que están equipados los vehículos, […]