Herencia en subdivisión de árbol múltiple de matriz de muestras.
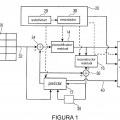
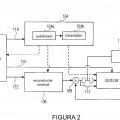
Decodificador para reconstruir una matriz de muestras de información que representa una señal de información muestreada espacialmente,
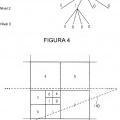
que se subdivide, de acuerdo con información de subdivisión, en regiones de hoja de diferentes tamaños mediante subdivisión multi-árbol, desde un flujo de datos, en el que cada región de hoja tiene asociada a la misma un nivel de jerarquía de una secuencia de niveles de jerarquía de la subdivisión multi-árbol, cada región de hoja tiene asociada a la misma parámetros de codificación, los parámetros de codificación se representan, para cada región de hoja, mediante un conjunto respectivo de elementos de sintaxis, cada elemento de sintaxis es de un tipo de elemento de sintaxis respectivo de un conjunto de tipos de elementos de sintaxis, y comprendiendo el decodificador
un extractor para extraer (550) la información de subdivisión y la información de herencia, señalizadas en el flujo de datos además de la información de sub-división, desde el flujo de datos, indicando la información de herencia en cuanto a si se usa o no herencia, y si se indica que se usa herencia, al menos una región de herencia de la matriz de muestras de información que está compuesta de un conjunto de las regiones de hoja y se corresponde con un nivel de jerarquía de secuencia de niveles de jerarquía de la sub-división multi-árbol, que es inferior que cada uno de los niveles de jerarquía al que está asociado el conjunto de regiones de hoja;
en el que el decodificador está configurado para, si se indica que se usa herencia,
extraer (554) un subconjunto de herencia que incluye al menos un elemento de sintaxis de un tipo de elemento de sintaxis predeterminado desde el flujo de datos por región de herencia, y
usar (556) el subconjunto de herencia como una predicción para un subconjunto de herencia correspondiente de elementos de sintaxis en el conjunto de elementos de sintaxis que representa los parámetros de codificación asociados al conjunto de regiones de hoja de los que la respectiva al menos una región de herencia está compuesta.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2011/055794.
Solicitante: GE Video Compression, LLC.
Inventor/es: WIEGAND, THOMAS, MARPE,DETLEV, HELLE,PHILIPP, OUDIN,SIMON.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- H04N19/46 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04N TRANSMISION DE IMAGENES, p. ej. TELEVISION. › H04N 19/00 Métodos o disposiciones para la codificación, decodificación, compresión o descompresión de señales de vídeo digital. › Incorporación de información adicional en la señal de vídeo durante el proceso de compresión (H04N 19/517, H04N 19/68, H04N 19/70 tienen prioridad).
- H04N19/52 H04N 19/00 […] › por codificación predictiva.
- H04N19/53 H04N 19/00 […] › Estimación del movimiento en multirresolución; Estimación del movimiento jerárquicamente.
- H04N19/96 H04N 19/00 […] › Codificación de árbol, p. ej. codificación en árbol cuádruple(quad-tree).
PDF original: ES-2553245_T3.pdf

Patentes similares o relacionadas:
Método para segmentación de imágenes usando columnas, del 22 de Julio de 2020, de DOLBY INTERNATIONAL AB: Un método para codificar una imagen de video que comprende una pluralidad de bloques (1… 24) de árbol codificados dispuestos en al menos […]
Procedimiento, aparato y programa para codificar datos de imágenes en un flujo de bits, del 15 de Julio de 2020, de CANON KABUSHIKI KAISHA: Procedimiento para codificar datos de imagen en un flujo de bits, comprendiendo el procedimiento: codificar, en el flujo de bits, un indicador […]
Filtrado multimétrico, del 8 de Julio de 2020, de QUALCOMM INCORPORATED: Un procedimiento de codificación de datos de vídeo en un esquema de filtro en bucle adaptativo basado en árbol cuaternario, QALF, con múltiples filtros, comprendiendo […]
Codificación luma-croma con tres predictores espaciales distintos, del 17 de Junio de 2020, de DOLBY INTERNATIONAL AB: Un codificador de video para codificar datos de señal de video para un bloque de imagen, comprendiendo el codificador de video un codificador para codificar […]
Procedimiento de descodificación predictiva de vídeo en movimiento, dispositivo de descodificación predictiva de vídeo en movimiento, del 17 de Junio de 2020, de NTT DOCOMO, INC.: Procedimiento de descodificación predictiva de vídeo ejecutado por un dispositivo de descodificación predictiva de vídeo, que comprende: […]
Procedimiento de codificación de imágenes, procedimiento de descodificación de imágenes, aparato de codificación de imágenes, aparato de descodificación de imágenes y aparato de codificación / descodificación de imágenes, del 27 de Mayo de 2020, de Sun Patent Trust: Un procedimiento de codificación de imágenes que comprende: dividir (S201) una imagen en mosaicos; codificar (S202) los mosaicos para […]
Reposicionamiento de bloques residuales de predicción en codificación de vídeo, del 6 de Mayo de 2020, de QUALCOMM INCORPORATED: Un procedimiento para decodificar datos de vídeo, comprendiendo el procedimiento: decodificar al menos un bloque residual de datos de vídeo, usando el modo de omisión de transformación […]
Procedimiento de codificación de imágenes, procedimiento de descodificación de imágenes, dispositivo de codificación de imágenes, dispositivo de descodificación de imágenes y dispositivo de codificación/descodificación de imágenes, del 29 de Abril de 2020, de Sun Patent Trust: Un procedimiento de descodificación de imágenes de descodificación de un flujo de bits para generar un bloque descodificado, comprendiendo el procedimiento de descodificación […]