DISPOSITIVO Y PROCEDIMIENTO PARA GENERAR UNA SEÑAL MULTICANAL CON UN PROCESAMIENTO DE SEÑAL DE VOZ.
Dispositivo para generar una señal (10) multicanal con un número de señales de canal de salida,
que es mayor que un número de señales de canal de entrada de una señal (12) de entrada, siendo el número de señales de canal de entrada igual a 1 o mayor, con las características siguientes: un mezclador (14) ascendente para mezclar de manera ascendente la señal de entrada, que presenta una parte de voz, para proporcionar al menos una señal de canal directo y al menos una señal de canal de entorno con una parte de voz; un detector (18) de voz para detectar un segmento de la señal de entrada, de la señal de canal directo o de la señal de canal de entorno, en el que aparece la parte de voz; y un modificador (20) de señal para modificar un segmento de la señal de canal de entorno, que corresponde al segmento detectado por el detector (18), para obtener una señal de canal de entorno modificada, en la que la parte de voz está atenuada o eliminada, no estando atenuado o estando atenuado en menor medida el segmento en la señal de canal directo; y un medio (22) de emisión de señal de altavoz para emitir señales de altavoz en un esquema de reproducción utilizando el canal directo y la señal de canal de entorno modificada, siendo las señales de altavoz las señales de canal de salida
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2008/008324.
Solicitante: FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V..
Nacionalidad solicitante: Alemania.
Dirección: HANSASTRASSE 27C 80686 MUNCHEN ALEMANIA.
Inventor/es: HERRE, JURGEN, UHLE, CHRISTIAN, HELLMUTH, OLIVER, POPP, HARALD, KASTNER,THORSTEN.
Fecha de Publicación: .
Fecha Solicitud PCT: 1 de Octubre de 2008.
Clasificación Internacional de Patentes:
- G10L21/02A4
- H04S5/00F
Clasificación PCT:
- G10L21/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 21/00 Tratamiento de la señal de la voz para producir otra señal audible o no audible, p. ej. visual o táctil, con el fin de modificar su calidad o su inteligibilidad (G10L 19/00 tiene prioridad). › Mejora de la inteligibilidad de la voz, p. ej. reducción de ruido o eliminación de ecos (reducción de efectos de eco en los sistemas de transmisión en línea H04B 3/20; supresión de eco en teléfonos de manos libres H04M 9/08).
- H04S5/02 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04S SISTEMAS ESTEREOFONICOS. › H04S 5/00 Sistemas seudoestereofónicos, p. ej. en los que las señales de un canal suplementario son derivadas de la señal monofásica por desfase, retardo o reverberación. › del tipo seudocuadrafónico, p. ej. en los que las señales de los canales de llegada son derivados de señales estereofónicas de dos canales.
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia, Ex República Yugoslava de Macedonia, Albania.
PDF original: ES-2364888_T3.pdf
Fragmento de la descripción:
La presente invención se refiere al campo del procesamiento de señales de audio y en particular a la generación de varios canales de salida a partir de menos canales de entrada, como por ejemplo un canal (mono) o dos canales (estéreo) de entrada.
Un dispositivo correspondiente se desprende por ejemplo del documento EP 1 021 063.
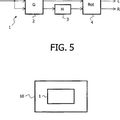
El material de audio multicanal se está volviendo cada vez más popular. Esto ha llevado a que, entretanto, también muchos usuarios finales tengan sistemas de reproducción multicanal. Esto se debe principalmente a que los DVD son cada vez más populares, y que por tanto también muchos usuarios de DVD entretanto tengan equipos multicanal 5.1. Los sistemas de reproducción de este tipo están compuestos en general por tres altavoces L (izquierdo), C (central) y R (derecho), que normalmente están dispuestos delante del usuario, y dos altavoces Ls y Rs, que están dispuestos detrás del usuario, y normalmente aún un canal LFE, que también se denomina canal de efecto de baja frecuencia o subwoofer. Un escenario de canales de este tipo se indica en la figura 5b y en la figura 5c. Mientras que el posicionamiento de los altavoces L, C, R, Ls, Rs respecto al usuario debería realizarse como se indica en las figuras 10 y 11, para que el usuario reciba una impresión auditiva lo mejor posible, el posicionamiento del canal LFE (no se muestra en las figuras 5b y 5c) no es tan decisivo porque a frecuencias tan bajas el oído no puede efectuar ninguna localización y así el canal LFE puede disponerse en cualquier lugar en el que no moleste por su tamaño considerable.
Un sistema multicanal de este tipo ofrece varias ventajas respecto a una reproducción estéreo típica, que es una reproducción de dos canales, tal como se muestra por ejemplo en la figura 5a. También fuera de la posición de escucha central óptima se obtiene una estabilidad mejorada de la impresión auditiva frontal, que también se denomina “imagen frontal” (front image), y concretamente gracias al canal central. Así se obtiene un “punto óptimo” (sweet-spot) más grande, indicando el “punto óptimo” la posición de escucha óptima.
Además el oyente tiene una mejor sensación de “inmersión” en la escena de audio gracias a los dos altavoces traseros Ls y Rs.
Aún así existe un gran número de materiales de audio en propiedad del usuario o disponibles en general que sólo existe como material estéreo, que por tanto sólo tiene dos canales, concretamente el canal izquierdo y el canal derecho. Los soportes de sonido típicos para tales piezas estéreo son los discos compactos.
Para reproducir un material estéreo de este tipo con un equipo de audio multicanal 5.1 existen dos opciones recomendadas por la ITU.
La primera opción consiste en reproducir el canal izquierdo y el derecho a través del altavoz izquierdo y el derecho del sistema de reproducción multicanal. Sin embargo, en esta solución es desventajoso que no se aproveche la pluralidad de altavoces ya existentes, es decir que no se aproveche la existencia del altavoz central y de los dos altavoces traseros.
Otra opción consiste en transformar los dos canales en una señal multicanal. Esto puede ocurrir durante la reproducción
o mediante un procesamiento previo especial que aprovecha ventajosamente los seis altavoces del sistema de reproducción 5.1 existente por ejemplo y así lleva a una impresión auditiva mejorada cuando la mezcla ascendente o “upmix” se realiza sin errores de dos canales a 5 ó 6 canales.
La segunda opción, es decir, el uso de todos los altavoces del sistema multicanal sólo es ventajosa respecto a la primera solución cuando por tanto no se producen errores de mezcla ascendente. Tales errores de mezcla ascendente pueden ser en particular molestos cuando las señales para los altavoces traseros, que también se conocen como señales de ambiente o señales de entorno, no se generan sin errores.
Una posibilidad para realizar este denominado proceso de mezcla ascendente se conoce por la expresión “concepto directo/ambiente”. Las fuentes de sonido directo se reproducen mediante los tres canales frontales de manera que el usuario las percibe en la misma posición que en la versión original de dos canales. La versión original de dos canales se representa esquemáticamente en la figura 5a y concretamente en el ejemplo de diferentes instrumentos de percusión.
La figura 5b muestra una versión mezclada de manera ascendente del concepto, en la que todas las fuentes de sonido originales, esto es, los instrumentos de percusión se reproducen de nuevo por los tres altavoces L, C y R frontales, emitiéndose adicionalmente por los dos altavoces traseros señales de entorno especiales. La expresión “fuente de sonido directo” se utiliza así para describir un sonido que sólo procede directamente de una fuente de sonido discreta como por ejemplo un instrumento de percusión u otro instrumento o en general un objeto de audio especial, tal como se representa esquemáticamente por ejemplo en la figura 5a mediante un instrumento de percusión. Sonidos adicionales de cualquier tipo, como por ejemplo los debidos a reflexiones en la pared, etc. no están presentes en una fuente de sonido directo de este tipo. En este escenario las señales de sonido, emitidas por los dos altavoces traseros Ls, Rs en la figura 5b, sólo están compuestas por señales de entorno, que están presentes o no en la grabación original. Tales señales de entorno o señales “ambiente” no pertenecen a una única fuente de sonido, sino que contribuyen a la reproducción de la acústica arquitectónica de una grabación y llevan por tanto a la denominada sensación de “inmersión” del oyente.
Un concepto alternativo adicional, denominado concepto “en la banda” se representa esquemáticamente en la figura 5c. Cualquier tipo de sonido, es decir, fuentes de sonido directo y sonidos de tipo de entorno se posiciona alrededor del oyente. La posición de un sonido es independiente de su característica (fuentes de sonido directo o sonidos de tipo de entorno) y depende sólo del diseño específico del algoritmo, tal como se representa por ejemplo en la figura 5c. Así en la figura 5c mediante el algoritmo de mezcla ascendente se determina que los dos instrumentos 1100 y 1102 se posicionan lateralmente respecto al oyente, mientras que los dos instrumentos 1104 y 1106 se posicionan delante del usuario. Esto lleva a que ahora los dos altavoces traseros Ls, Rs también contengan partes de los dos instrumentos 1100 y 1102 y ya no sólo sonidos de tipo de entorno, como aún era el caso de la figura 5b en el que los mismos instrumentos están posicionados todos delante del usuario.
La publicación “C. Avendano y J.M. Jot: “Ambience Extraction and Synthesis from Stereo Signals for Multichannel Audio Upmix”, IEEE International Conference on Acoustics, Speech and signal Processing, ICASSP 02, Orlando, Fl, mayo de 2002” da a conocer una técnica en el dominio de frecuencia, para identificar y extraer información de entorno en señales de audio estéreo. Este concepto se basa en el cálculo de una coherencia entre canales y una función de correlación no lineal, que permitirá determinar regiones en tiempo-frecuencia en la señal estéreo que principalmente se componen de componentes de entorno. A continuación se sintetizan y utilizan señales de entorno para alimentar los canales traseros
o canales “envolventes” Ls, Rs (figuras 10 y 11) de un sistema de reproducción multicanal.
En la publicación “R. Irwan y Ronald M. Aarts: “A method to convert stereo to multi-channel sound”, The proceedings of the AES 19th International Conference, Schloss Elmau, Alemania, 21-24 de junio, páginas 139-143, 2001” se presenta un procedimiento para transformar una señal estéreo en una señal multicanal. La señal para los canales envolventes se calcula utilizando una técnica de correlación cruzada. Se utiliza un análisis de componente principal (PCA; PCA = Principle Component Analysis) para calcular un vector que indica una dirección de la señal dominante. Este vector se correlaciona entonces a partir de una representación de dos canales para dar una representación de tres canales con el fin de generar los tres canales frontales.
Todas las técnicas conocidas intentan extraer de diferentes maneras las señales de ambiente o señales de entorno de la señal estéreo original o incluso sintetizarlas... [Seguir leyendo]
Reivindicaciones:
1. Dispositivo para generar una señal (10) multicanal con un número de señales de canal de salida, que es mayor que un número de señales de canal de entrada de una señal (12) de entrada, siendo el número de señales de canal de entrada igual a 1 o mayor, con las características siguientes:
un mezclador (14) ascendente para mezclar de manera ascendente la señal de entrada, que presenta una parte de voz, para proporcionar al menos una señal de canal directo y al menos una señal de canal de entorno con una parte de voz;
un detector (18) de voz para detectar un segmento de la señal de entrada, de la señal de canal directo o de la señal de canal de entorno, en el que aparece la parte de voz; y
un modificador (20) de señal para modificar un segmento de la señal de canal de entorno, que corresponde al segmento detectado por el detector (18), para obtener una señal de canal de entorno modificada, en la que la parte de voz está atenuada o eliminada, no estando atenuado o estando atenuado en menor medida el segmento en la señal de canal directo; y
un medio (22) de emisión de señal de altavoz para emitir señales de altavoz en un esquema de reproducción utilizando el canal directo y la señal de canal de entorno modificada, siendo las señales de altavoz las señales de canal de salida.
2. Dispositivo según la reivindicación 1, en el que el medio (22) de emisión de señal de altavoz está configurado para funcionar según un esquema directo/de entorno, en el que cada canal directo puede correlacionarse con un altavoz propio, y cada señal de canal de entorno puede correlacionarse con un altavoz propio, estando configurado el medio
(22) de emisión de señal de altavoz para correlacionar con señales de altavoz, para altavoces situados detrás de un oyente en el esquema de reproducción, sólo la señal de canal de entorno y no el canal directo.
3. Dispositivo según la reivindicación 1, en el que el medio (22) de emisión de señal de altavoz está configurado para funcionar según un esquema en banda, en el que cada señal de canal directo puede correlacionarse con uno o varios altavoces en función de su posición, y en el que el medio (22) de emisión de señal de altavoz está configurado para sumar la señal de canal de entorno y el canal directo o una parte de la señal de canal de entorno o del canal directo, que están determinadas para un altavoz, con el fin de obtener una señal de emisión de altavoz para el altavoz.
4. Dispositivo según una de las reivindicaciones anteriores, en el que el medio de emisión de señal de altavoz está configurado para proporcionar señales de altavoz para al menos tres canales, que en el esquema de reproducción pueden situarse delante de un oyente, y para generar al menos dos canales, que en el esquema de reproducción pueden situarse detrás del oyente.
5. Dispositivo según una de las reivindicaciones anteriores,
en el que el detector (18) de voz está configurado para funcionar por bloques en el tiempo, y para analizar cada bloque temporal de manera selectiva en frecuencia por bandas, con el fin de detectar una banda de frecuencia para un bloque temporal, y
en el que el modificador (20) de señal está configurado para modificar una banda de frecuencia en un bloque temporal de la señal de canal de entorno que corresponde a la banda detectada por el detector (18) de voz.
6. Dispositivo según una de las reivindicaciones anteriores,
en el que el modificador de señal está configurado para atenuar la señal de canal de entorno o partes de la señal de canal de entorno en un intervalo de tiempo detectado por el detector (18) de voz, y
estando configurados el mezclador (14) ascendente y el medio (22) de emisión de señal de altavoz para generar el al menos un canal directo de manera que el mismo segmento temporal no se atenúe o se atenúe en menor medida, de modo que el canal directo presente una componente de voz, que en una reproducción pueda percibirse con más intensidad que una componente de voz en la señal de canal de entorno modificada.
7. Dispositivo según una de las reivindicaciones anteriores, en el que el modificador (20) de señal está configurado para someter la al menos una señal de canal de entorno a un filtrado paso alto cuando el detector (18) de voz ha detectado un segmento temporal en el que aparece una parte de voz, situándose una frecuencia límite del filtro paso alto entre 400 Hz y 3.500 Hz.
8. Dispositivo según una de las reivindicaciones anteriores,
en el que el detector (18) de voz está configurado para detectar una aparición temporal de una componente de señal de voz, y
en el que el modificador (20) de señal está configurado para determinar una frecuencia fundamental de la componente de señal de voz, y
para atenuar (43) selectivamente sonidos en la señal de canal de entorno o la señal de entrada a la frecuencia fundamental y los armónicos, con el fin obtener la señal de canal de entorno modificada o la señal de entrada modificada.
9. Dispositivo según una de las reivindicaciones anteriores,
en el que el detector (18) de voz está configurado para determinar por cada banda de frecuencia una medida de un contenido de voz, y
en el que el modificador (20) de señal está configurado para atenuar (72a, 72b) una banda correspondiente de la señal de canal de entorno según la medida con un factor de atenuación, resultando una medida superior en un factor de atenuación superior y una medida inferior en un factor de atenuación inferior.
10. Dispositivo según la reivindicación 9, en el que el modificador (20) de señal presenta las características siguientes:
un convertidor (70) de dominio de tiempo-frecuencia para convertir la señal de entorno en una representación espectral;
un atenuador (72a, 72b) para la atenuación variable de manera selectiva en frecuencia de la representación espectral; y
un convertidor (73) de dominio de frecuencia-tiempo para convertir la representación espectral atenuada de manera variable al dominio de tiempo, con el fin de obtener la señal de canal de entorno modificada.
11. Dispositivo según la reivindicación 9 ó 10, en el que el detector (18) de voz presenta las características siguientes:
un convertidor (42) de dominio de tiempo-frecuencia para proporcionar una representación espectral de una señal de análisis;
un medio para calcular una o varias características (71a, 71b) por cada banda de la señal de análisis; y
un medio (80) para calcular una medida de un contenido de voz basándose en una combinación de la una o varias características por cada banda.
12. Dispositivo según la reivindicación 11, en el que el modificador (20) de señal está configurado para calcular como características una medida de planeidad espectral (SFM) o una energía de modulación de 4 Hz (4HzME).
13. Dispositivo según una de las reivindicaciones anteriores, en el que el detector (18) de voz está configurado para analizar la señal (18c) de canal de entorno, y en el que el modificador (20) de señal está configurado para modificar la señal (16) de canal de entorno.
14. Dispositivo según una de las reivindicaciones 1 a 12, en el que el detector (18) de voz está configurado para analizar la señal (18a) de entrada, y en el que el modificador (20) de señal está configurado para modificar la señal (16) de canal de entorno basándose en información (18d) de control del detector (18) de voz.
15. Dispositivo según una de las reivindicaciones 1 a 12, en el que el detector (18) de voz está configurado para analizar la señal (18a) de entrada, y en el que el modificador (20) de señal está configurado para modificar la señal de entrada basándose en información (18d) de control del detector (18) de voz, y en el que el mezclador (14) ascendente presenta un extractor de canal de entorno, que está configurado para, basándose en la señal de entrada modificada, determinar la señal (16') de canal de entorno modificada, estando configurado además el mezclador (14) ascendente para, basándose en la señal (12) de entrada en la entrada del modificador (20) de señal, determinar la señal (15) de canal directo.
16. Dispositivo según una de las reivindicaciones 1 a 12,
en el que el detector (18) de voz está configurado para analizar la señal (18a) de entrada, en el que además está previsto un analizador (30) de voz, para someter la señal de entrada a un análisis de voz, y
en el que el modificador (20) de señal está configurado para modificar la señal (16) de canal de entorno basándose en información (18d) de control del detector (18) de voz y basándose en información (18e) de análisis de voz del analizador
(30) de voz.
17. Dispositivo según una de las reivindicaciones anteriores, en el que el mezclador (14) ascendente está configurado como decodificador de matriz.
18. Dispositivo según una de las reivindicaciones anteriores, en el que el mezclador (14) ascendente está configurado como mezclador ascendente ciego que, basándose únicamente en la señal (12) de entrada, pero sin información de mezcla ascendente transmitida de manera adicional, genera la señal (15) de canal directo y la señal (16) de canal de entorno.
19. Dispositivo según una de las reivindicaciones anteriores,
en el que el mezclador (14) ascendente está configurado para realizar un análisis estadístico de la señal (12) de entrada, con el fin de generar la señal (15) de canal directo y la señal (16) de canal de entorno.
20. Dispositivo según una de las reivindicaciones anteriores, en el que la señal de entrada es una señal mono con un canal y en el que la señal de salida es una señal multicanal con dos o más señales de canal.
5 21. Dispositivo según una de las reivindicaciones 1 a 19, en el que el mezclador (14) ascendente está configurado para obtener como señal de entrada una señal estéreo con dos señales de canal estéreo, y en el que el mezclador (14) ascendente está configurado además para realizar la señal (16) de canal de entorno basándose en un cálculo de correlación cruzada de las señales de canal estéreo.
22. Procedimiento para generar una señal (10) multicanal con un número de señales de canal de salida, que es mayor que un número de señales de canal de entrada de una señal (12) de entrada, siendo el número de señales de canal de entrada igual a 1 o mayor, con las etapas siguientes:
mezclar de manera ascendente (14) la señal de entrada, para proporcionar al menos una señal de canal directo y al menos una señal de canal de entorno;
detectar (18) un segmento de la señal de entrada, de la señal de canal directo o de la señal de canal de entorno, en el 15 que aparece una parte de voz; y
modificar (20) un segmento de la señal de canal de entorno que corresponde al segmento detectado en la etapa de la detección (18), para obtener una señal de canal de entorno modificada, en la que la parte de voz está atenuada o eliminada, no estando atenuado o estando atenuado en menor medida el segmento en la señal de canal directo; y
emitir (22) señales de altavoz en un esquema de reproducción utilizando el canal directo y la señal de canal de entorno 20 modificada, siendo las señales de altavoz las señales de canal de salida.
23. Programa informático con un código de programa para realizar el procedimiento según la reivindicación 22, cuando el código de programa se ejecuta en un ordenador.
Patentes similares o relacionadas:
 CODIFICACION Y DECODIFICACION DE AUDIO, del 26 de Mayo de 2010, de KONINKLIJKE PHILIPS ELECTRONICS N.V.: Codificador de audio que comprende:
- medios para recibir una señal de audio de canal M donde M>2;
- medios de mezclado descendente […]
CODIFICACION Y DECODIFICACION DE AUDIO, del 26 de Mayo de 2010, de KONINKLIJKE PHILIPS ELECTRONICS N.V.: Codificador de audio que comprende:
- medios para recibir una señal de audio de canal M donde M>2;
- medios de mezclado descendente […]
 CONVERSION DE CANAL DE AUDIO, del 17 de Febrero de 2010, de KONINKLIJKE PHILIPS ELECTRONICS N.V.
DOLBY SWEDEN AB: Dispositivo para la conversión de un primer número (M) de canales de audio de entrada en un segundo número (N) de canales de audio de salida, en el que […]
CONVERSION DE CANAL DE AUDIO, del 17 de Febrero de 2010, de KONINKLIJKE PHILIPS ELECTRONICS N.V.
DOLBY SWEDEN AB: Dispositivo para la conversión de un primer número (M) de canales de audio de entrada en un segundo número (N) de canales de audio de salida, en el que […]
DISPOSITIVO DE MEJORA DE SONIDO DE VOZ, del 16 de Enero de 2012, de FUJITSU LIMITED: Un dispositivo de mejora de sonido de voz incluyendo: una unidad de calculo SNR configurada para calcular una SNR que es una relacion […]
PROCEDIMIENTO, DISPOSITIVO Y MEDIO DE CÓDIGO DE PROGRAMA INFORMÁTICO PARA LA CONVERSIÓN DE VOZ, del 22 de Agosto de 2011, de ASOCIACIÓN CENTRO DE TECNOLOGÍAS DE INTERACCIÓN VISUAL Y COMUNICACIONES VICOMTECH DEL POZO ECHEZARRETA, MARÍA ARANTZAZU: Un procedimiento para convertir una señal de habla de un hablante fuente en un a señal de voz convertida, que comprende los pasos de: - una etapa de entrenamiento, […]
 MEJORAMIENTO DE AUDIO EN DOMINIO CODIFICADO, del 21 de Abril de 2010, de NOKIA CORPORATION: Un procedimiento de mejoramiento de una señal de audio codificada que comprende índices que representan parámetros de señales de audio de señales de audio que comprenden […]
MEJORAMIENTO DE AUDIO EN DOMINIO CODIFICADO, del 21 de Abril de 2010, de NOKIA CORPORATION: Un procedimiento de mejoramiento de una señal de audio codificada que comprende índices que representan parámetros de señales de audio de señales de audio que comprenden […]
SISTEMA Y DISPOSITIVO INALÁMBRICO Y PONIBLE PARA REGISTRO, PROCESAMIENTO Y REPRODUCCIÓN DE SONIDOS EN PERSONAS CON DISTROFIA EN EL SISTEMA RESPIRATORIO, del 5 de Marzo de 2020, de ARAGÓN HAN, Daniel: La invención se refiere a un sistema y dispositivo para el registro, procesamiento y reproducción de sonidos en personas con distrofia en el […]
Métodos, aparatos y sistema para codificar y decodificar una señal, del 8 de Enero de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método para codificar una señal, que comprende: realizar un proceso de decisión de clasificación sobre una señal de banda de alta frecuencia de una señal […]
Métodos para codificar y decodificar una señal de audio, decodificador de audio y codificador de audio, del 1 de Enero de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un método para codificar una señal de audio, comprendiendo el método: (a) recibir una señal de audio ; (b) generar una señal de audio codificada; […]