Decodificación de señales de audio multicanal usando predicción compleja.
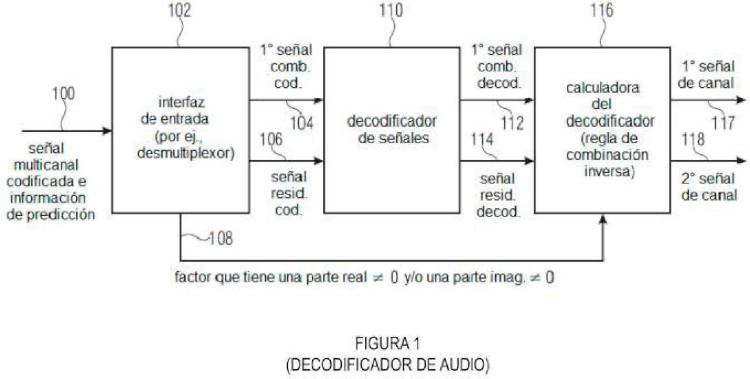
Un decodificador de audio para decodificar una señal de audio multicanal codificada (100),
la señal de audio multicanal codificada comprende una primera señal de combinación codificada generada en base a una regla de combinación para combinar una primera señal de audio de canal y una segunda señal de audio de canal de una señal de audio multicanal, una señal residual de predicción codificada e información de predicción, que comprende: un decodificador de señales (110) para decodificar la primera señal de combinación codificada (104) para obtener una primera señal de combinación decodificada (112) y para decodificar la señal residual codificada (106) para obtener una señal residual decodificada (114); y
una calculadora del decodificador (116) para calcular una señal de audio multicanal decodificada que tiene una primera señal de audio de canal decodificada (117), y una segunda señal de audio de canal decodificada (118) utilizando la señal residual decodificada (114), la información de predicción (108) y la primera señal de combinación decodificada (112), de modo que la primera señal de audio de canal decodificada (117) y la segunda señal de audio de canal decodificada (118) son por lo menos aproximaciones de la primera señal de audio de canal y la segunda señal de audio de canal de la señal de audio multicanal, en donde la información de predicción (108) comprende un factor de valor real distinto de cero y/o un factor imaginario distinto de cero, en el cual la calculadora del decodificador (116) comprende:
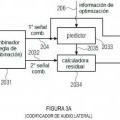
un predictor (1160) para aplicar la información de predicción (108) a la primera señal de combinación decodificada (112) o a una señal (601) proveniente de la primera señal de combinación decodificada para obtener una señal de predicción (1163);
una calculadora de señales de combinación (1161) para calcular una segunda señal de combinación (1165) combinando la señal residual decodificada (114) y la señal de predicción (1163); y
un combinador (1162) para combinar la primera señal de combinación decodificada (112) y la segunda señal de combinación (1165) para obtener una señal de audio multicanal decodificada que tiene la primera señal de audio de canal decodificada (117) y la segunda señal de audio de canal decodificada (118),
en el cual el predictor (1160, 1160a) está configurado para
multiplicar la primera señal de combinación decodificada por el factor real de la información de predicción (108) para obtener una primera parte de la señal de predicción,
estimar una parte imaginaria de la primera señal de combinación decodificada (112) usando una parte real de la primera señal de combinación decodificada (112), comprendiendo estimar la parte imaginaria usar una pluralidad de subbandas de la primera señal de combinación decodificada adyacentes en frecuencia, en las cuales, en caso de bajas o altas frecuencias, se usa una extensión simétrica en frecuencia del cuadro actual de la primera señal de combinación para las subbandas asociadas con frecuencias más bajas o iguales a cero o más altas o iguales a una mitad de una frecuencia de muestreo en la que está basado el cuadro actual, o en el cual los coeficientes de filtro de un filtro incluido en el predictor (1160a) se establecen a diferentes valores para subbandas perdidas en comparación con subbandas no perdidas,
multiplicar la parte imaginaria (601) de la primera señal de combinación decodificada por el factor imaginario de la información de predicción (108) para obtener una segunda parte de la señal de predicción; y
en el cual la calculadora de señales de combinación (1161) está configurada para combinar en forma lineal la primera parte de la señal de predicción y la segunda parte de la señal de predicción y la señal residual decodificada para obtener la segunda señal de combinación (1165).
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2011/054485.
Solicitante: FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V..
Nacionalidad solicitante: Alemania.
Dirección: HANSASTRASSE 27C 80686 MUNCHEN ALEMANIA.
Inventor/es: VILLEMOES, LARS, EDLER, BERND, HILPERT, JOHANNES, PURNHAGEN,HEIKO, RETTELBACH,NIKOLAUS, DISCH,SASCHA, Helmrich,Christian, NEUSINGER,MATTHIAS, CARLSSON,PONTUS, ROBILLARD,JULIEN.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L19/008 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › Codificación de señales de audio multicanalde o de decodificación mediante la correlación entre canales para reducir la redundancia, p. ej. estéreo conjunto, codificación de la intensidad o matrizado.
- G10L19/04 G10L 19/00 […] › utilizando técnicas de predicción.
PDF original: ES-2552839_T3.pdf



Patentes similares o relacionadas:
Técnicas de ocultamiento híbrido: combinación de ocultamiento de pérdida paquete de dominio de frecuencia y tiempo en códecs de audio, del 8 de Abril de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Una unidad de ocultamiento de error (100, 230, 380, 800, 800b) para proporcionar una información de audio de ocultamiento de error (102, 232, […]
Método y disposición para suavizar ruido estacionario de fondo, del 25 de Diciembre de 2019, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método para suavizar ruido de fondo, comprendiendo el método: recibir y decodificar (S10) una señal codificada que comprende tanto una componente de voz […]
Estimación de forma de ganancia para mejorar el rastreo de características temporales de banda alta, del 20 de Noviembre de 2019, de QUALCOMM INCORPORATED: Un procedimiento para generar una versión codificada de una señal de audio , en el que la versión codificada de la señal de audio se genera codificando […]
Dispositivo y método para procesamiento posterior de valores espectrales y codificador y decodificador para señales de audio, del 25 de Julio de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un dispositivo para el procesamiento posterior de valores espectrales basado en un primer algoritmo de transformación para convertir una señal de audio en una representación […]
Codificación y decodificación de posiciones de impulso de pistas de una señal de audio, del 3 de Junio de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato para decodificar una señal de audio codificada, en el que una o más pistas se asocian con la señal de audio codificada, teniendo […]
Codificación de audio en los dominios de tiempo y frecuencia mediante el uso de un procesador cruzado para inicialización continua, del 1 de Mayo de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Codificador de audio para la codificación de una señal de audio, que comprende: un primer procesador de codificación para la codificación […]
Codificador que utiliza cancelación del efecto de solapamiento hacia delante, del 25 de Abril de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Decodificador para decodificar un flujo de datos que comprende una secuencia de tramas en las cuales se codifican segmentos de tiempo de […]
Codificación y decodificación de audio en los dominios de la frecuencia y del tiempo, del 24 de Abril de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Codificador de audio para codificar una señal de audio, que comprende: un primer procesador de codificación para codificar una primera porción […]