Codificación de sonido con bajo retardo que alterna codificación predictiva y codificación por transformada.
Procedimiento de codificación de una señal de sonido digital, que incluye las etapas de:
- codificación (E601) de una trama anterior de muestras de la señal digital según una codificación predictiva,
- codificación (E603) de una trama actual de muestras de la señal digital según una codificación por transformada;
caracterizándose el procedimiento porque una primera parte de la trama actual está codificada (E602) por una codificación predictiva restringida respecto de la codificación predictiva de la trama anterior reutilizando al menos un parámetro de la codificación predictiva de la trama anterior y codificando solo los parámetros no reutilizados de esta primera parte de la trama actual
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/FR2011/053097.
Solicitante: Orange.
Nacionalidad solicitante: Francia.
Dirección: 78, rue Olivier de Serres 75015 Paris FRANCIA.
Inventor/es: KOVESI, BALAZS, RAGOT,STEPHANE, BERTHET,PIERRE.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L19/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › utilizando análisis espectrales, p. ej. codificadores vocales de transformación o codificadores vocales subbanda.
- G10L19/022 G10L 19/00 […] › Bloqueo, p. ej. agrupación de muestras en el tiempo; Elección de las ventanas de análisis; Factorización de interferencias.
- G10L19/04 G10L 19/00 […] › utilizando técnicas de predicción.
- G10L19/14
- G10L19/18 G10L 19/00 […] › Codificadores de voz que utilizan modos múltiples.
PDF original: ES-2529221_T3.pdf
Fragmento de la descripción:
Codificación de sonido con bajo retardo que alterna codificación predictiva y codificación por transformada La presente invención se refiere al ámbito de la codificación de señales digitales.
La invención se aplica ventajosamente a la codificación de sonidos que presentan alternancias de voz y de música.
Para codificar eficazmente los sonidos de voz, se preconizan las técnicas de tipo CELP ("Code Excited Linear Prediction"). Para codificar eficazmente los sonidos musicales, se preconizan más bien las técnicas de codificación por transformada.
Los codificadores de tipo CELP son codificadores predictivos. Tiene por objeto modelizar la producción de la voz a partir de diversos elementos: una predicción lineal a corto plazo para modelizar el conducto vocal, una predicción a largo plazo para modelizar la vibración de las cuerdas vocales en periodo sonoro, y una excitación derivada de un diccionario fijo (ruido blanco, excitación algebraica) para representar la innovación que no se ha podido modelizar
Los codificadores por transformada más utilizados (codificador MPEG AAC o ITU-T G.722.1 Anexo C por ejemplo) utilizan transformadas de muestreo crítico con el fin de compactar la señal en el campo transformada. Se denomina "transformada del muestreo crítico", una transformada para la que el número de coeficientes en el campo de transformada es igual al número de muestras temporales analizadas.
Una solución para codificar eficazmente una señal que contiene estos dos tipos de contenido, consiste en seleccionar a lo largo del tiempo la mejor técnica. Esta solución ha sido especialmente preconizada por el organismo de estandarización 3GPP ("3rd Generation Partnership Project") y se ha propuesto una técnica denominada AMR WB+.
Esta técnica está basada en una tecnología CELP de tipo AMR-WB, más específicamente de tipo ACELP (por "Algébrale Code Excited Linear Prediction" en inglés) y una codificación por transformada basada en una transformada de Fourierde recubrimiento en un modelo de tipo TCX (porTransform Coded eXcitation" en inglés).
La codificación ACELP y la codificación TCX son ambas técnicas de tipo lineal predictivo. Cabe señalar que el código AMR-WB+ se ha desarrollado para los servicios 3GPP PSS (por Packet Switched Streaming" en inglés), MBMS (por "Multimedia Broadcast/Multicast Service" en inglés) y MMS (por "Multimedia Messaging Service" en inglés), dicho de otro modo para servicios de difusión y almacenamiento, sin grandes condicionantes sobre el retardo algorítmico.
Esta solución está afectada por una calidad insuficiente respecto de la música. Esta insuficiencia procede en particular de la codificación por transformadas. En particular, la transformada de Fourier de recubrimiento no es una transformación de muestreo crítico, y por ello es sub-óptima.
Además, las ventanas utilizadas en este codificador no son óptimas respecto de la concentración de energía: las formas frecuenciales de estas ventanas casi-rectangulares son sub-óptimas.
Una mejora de la codificación AMR-WB+ combinada con los principios de la codificación MPEG AAC (por "Advanced Audio Coding" en inglés) es proporcionada por el código MPEG USAC (por "Unified Speech Audio Coding" en inglés), que sigue desarrollándose en el ISO/MPEG. Las aplicaciones apuntadas por MPEG USAC no son convencionales, sino que responden a servicios de difusión y almacenamiento sin graneles condicionantes sobre el retardo algorítmico.
La versión inicial del códec USAC, denominada RM (Reference Model ), se describe en el artículo de M. Neuendorf et ál. A Novel Scheme for Low Bitrate Unified Speech and Audio Coding - MPEG RM, 7-1 may 29, 12th AES Convention. Este códec RM alterna entre varios modos de codificación:
Para las señales de tipo de voz: modos LPD (por "linear Predictive Domain" en inglés) que comprenden dos modos diferentes derivados de la codificación AMR-WB+:
- Un modo ACELP
Un modo TCX denominado wLPT (por "wighted Linear Predective Transform" en inglés) que utiliza una transformada de tipo MDCT (contrariamente al códec AMR-WB+).
Para las señales de tipo música: modo FD (por "Frequency Domain" en inglés" que utiliza una codificación por transformada MDCT (por "Modified Discrete Cosine Transform" en inglés) de tipo MPEG AAC (por "Advanced Audio Coding" en inglés) en 124 muestras.
En comparación con el códec AMR-WB+, las diferencias principales aportadas por la codificación USAC RM para la parte mono son la utilización de una transformada con decimación crítica de tipo MDCT para la codificación por transformada y la cuantificación del espectro MDCT por cuantificación escalar con codificación aritmética. Cabe
señalar que la banda acústica codificada por los diferentes modos (LPD, FD) depende del modo seleccionado, lo cual no es el caso en el códec AMR-WB+ donde los modos ACELP y TCX operan en la misma frecuencia de muestreo interna. Además, la decisión de modo en el códec USAC RM se realiza en bucle abierto (u "open loop" en inglés) para cada trama de 124 muestras. Se recuerda que se denomina decisión de buche cerrado ("closed loop" en inglés) aquella que se efectúa ejecutando los diferentes modos de codificación en paralelo y eligiendo a posteriori el modo que proporciona el mejor resultado según un criterio predefinido. En el caso de una decisión de bucle abierto, la decisión es tomada a priori en función de los datos y de las observaciones disponibles pero sin probar si esta decisión es óptima o no.
En el códec USAC, las transiciones entre modos LPD y FD son cruciales para garantizar una calidad suficiente sin fallo de conmutación, sabiendo que cada modo (ACELP, TCX, FD) tiene una "firma específica" "en términos de artefactos) y que los modos FD y LPD son de naturaleza diferentes - el modo FD se basa en una codificación por transformada en el campo de la señal, mientras que los modos LPD utilizan una codificación lineal predictiva en el campo perceptualmente ponderado con memorias de filtro que se han de gestionar correctamente. La gestión de las conmutaciones intermodo en el códec USCA RM se detalla en el artículo de J. Lecomte et ál., "Efficient cross-fade Windows for transitions between LPC-based and non-LPC based audio coding". 7-1 May 29, 126th AES Convention. Como se ha explicado en este artículo, la dificultad principal reside en las transiciones entre modos LPD hacia FD y viceversa. Solo se tiene en cuenta aquí el caso de las transiciones de ACELP hacia FD.
Para entender correctamente el funcionamiento, se recuerda aquí el principio de la codificación por transformada MDCT a través de un ejemplo típico de realización.
En el codificador la transformación MDCT se divide en tres etapas:
Ponderación de la señal por una ventana denominada aquí "ventana MDCT" de longitud 2M.
Solape temporal (o "time-domain aliasing" en inglés) para formar un bloque de longitud M.
Transformación DCT (por "Discrete Cosine Transform" en inglés) de longitud M.
La ventana MDCT está dividida en 4 porciones adyacentes de longitud iguales M/2, denominadas "cuartos".
La señal se multiplica por la ventana de análisis y a continuación se efectúan los solapes: el primer cuarto (de ventana) está solapado (es decir invertido en el tiempo y puesto en modo de recubrimiento) en el segundo cuarto y el cuarto cuarto está solapado en el tercero.
Más concretamente, el solape de un cuarto sobre otro se efectúa de la siguiente manera: la primera muestra del primer cuarto se añade (o resta) a la última muestra del segundo cuarto, la segunda muestra del primer cuarto se suma (o resta) a la penúltima muestra del segundo cuarto, y así sucesivamente hasta la última muestra del primer cuarto que se suma (o resta) a la primera muestra del segundo cuarto.
De este modo se obtiene, a partir de 4 cuartos, 2 cuartos solapados donde cada muestra es el resultado de una combinación lineal de 2 muestras de la señal a codificar. Esta combinación lineal se denomina solape temporal.
Estos 2 cuartos solapados se codifican a continuación conjuntamente después de la transformación DCT. En la siguiente trama, se realiza un desfase de una media ventana (es decir el 5 % de recubrimiento), el tercer y el cuarto cuartos de la trama anterior se convierten entonces en el primer y segundo cuarto de la trama actual. Después del solape, se envía una segunda combinación lineal de los mismos pares de muestras como en la trama anterior, pero con pesos diferentes.
En el descodificador, después de la transformación DCT inversa, se obtiene por lo tanto la versión descodificada de estas señales solapadas. Dos tramas consecutivas contienen el resultado... [Seguir leyendo]
Reivindicaciones:
1Procedimiento de codificación de una señal de sonido digital, que incluye las etapas de:
- codificación (E61) de una trama anterior de muestras de la señal digital según una codificación predictiva,
- codificación (E63) de una trama actual de muestras de la señal digital según una codificación por transformada;
caracterizándose el procedimiento porque una primera parte de la trama actual está codificada (E62) por una codificación predictiva restringida respecto de la codificación predictiva de la trama anterior reutilizando al menos un parámetro de la codificación predictiva de la trama anterior y codificando solo los parámetros no reutilizados de esta primera parte de la trama actual.
2.- Procedimiento según la reivindicación 1, caracterizado porque la codificación predictiva restringida utiliza un filtro de predicción copiado de la trama anterior de codificación predictiva.
3.- Procedimiento según la reivindicación 2, caracterizado porque la codificación predictiva restringida utiliza, además, un valor descodificado del tono y/o de su ganancia asociada de la trama anterior de codificación predictiva.
4.- Procedimiento según la reivindicación 1, caracterizado porque algunos parámetros de codificación predictiva utilizados para la codificación predictiva restringida son cualificados en modo diferencial respecto de los parámetros descodificados de la trama anterior de codificación predictiva.
5.- Procedimiento según la reivindicación 1, caracterizado porque incluye una etapa de obtención de las señales reconstruidas procedentes de las codificaciones y descodificaciones locales predictiva y por transformada de la primera parte de la trama actual y de combinaciones (E64) por un fundido encadenado de estas señales reconstruidas.
6.- Procedimiento según la reivindicación 5, caracterizado porque dicho fundido encadenado de las señales reconstruidas se realiza en una porción de la primera parte de la trama actual en función de la forma de la ventana de la codificación por transformada.
7.- Procedimiento según la reivindicación 5, caracterizado porque dicho fundido encadenado de las señales reconstruidas se realiza en una porción de la primera parte de la trama actual, no conteniendo dicha porción ningún solape temporal.
8.- Procedimiento según la reivindicación 1, caracterizado porque la codificación por transformada utiliza una ventana de ponderación que incluye un número elegido de coeficientes de ponderación sucesivos de valor nulo al final y al principio de ventana.
9.- Procedimiento según la reivindicación 1, caracterizado porque la codificación por transformada utiliza una ventana de ponderación asimétrica que incluye un número elegido de coeficientes de ponderación sucesivos de valor nulo en al menos un extremo de la ventana.
1.- Procedimiento de descodificación de una señal de sonido digital, que incluye las etapas de:
- descodificación (E65) predictiva de una trama anterior de muestras de la señal digital recibida y codificada según una codificación predictiva,
- descodificación (E67) por transformada inversa de una trama actual de muestras de la señal digital recibida y codificada según una codificación por transformada;
caracterizándose el procedimiento porque incluye, además, una etapa de descodificación (E66) por una descodificación predictiva restringida respecto de la descodificación predictiva de la trama anterior de una primera parte de la trama actual recibida y codificada según una codificación predictiva restringida, reutilizando al menos un parámetro de la descodificación predictiva de la trama anterior y descodificando solo los parámetros recibidos para esta primera parte de la trama actual.
11.- Procedimiento según la reivindicación 1, caracterizado porque incluye una etapa de combinación (E68) por un fundido encadenado de las señales descodificadas por transformada inversa y por descodificación predictiva restringida para al menos una porción de la primera parte de la trama actual.
12.- Procedimiento según la reivindicación 1, caracterizado porque la codificación predictiva restringida utiliza un filtro de predicción descodificado y utilizado por la descodificación predictiva de la trama anterior.
13.- Procedimiento según la reivindicación 12, caracterizado porque la descodificación predictiva restringida utiliza,
además, un valor descodificado del tono y/o de su ganancia asociada de la descodificación predictiva de la trama anterior.
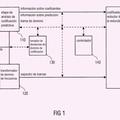
14.- Codificador de señal de sonido digital, que incluye:
- un módulo (211) de codificación predictiva para codificar una trama anterior de muestras de la señal digital,
- un módulo (221) de codificación por transformada para codificar una trama actual de muestras de la señal digital;
caracterizado porque incluye, además, un módulo (231) de codificación predictiva restringida respecto de la codificación predictiva de la trama anterior para codificar una primera parte de la trama actual, reutilizando al menos un parámetro de la codificación predictiva de la trama anterior y codificando solo los parámetros no reutilizados de esta primera parte de la trama actual.
15.- Descodificador de señal de sonio digital que incluye:
- un módulo (51) de descodificación predictiva para descodificar una trama anterior de muestras de la señal digital recibida y codificada según una codificación predictiva,
- un módulo (53) de descodificación por transformada inversa para descodificar una trama actual de muestras de la señal digital recibida y codificada según una codificación por transformada;
caracterizado porque incluye, además, un módulo (55) de descodificación predictiva restringida respecto de la descodificación predictiva de la trama anterior para descodificar una primera parte de la trama actual recibida y codificada según una codificación predictiva restringida, reutilizando al menos un parámetro de la descodificación predictiva de la trama anterior y descodificando solo los parámetros recibidos para esta primera parte de la trama actual.
16.- Programa informático que incluye instrucciones de código para la aplicación de las etapas del procedimiento de codificación según una de las reivindicaciones 1 a 9 y/o de descodificación según una de las reivindicaciones 1 a 13, cuando estas instrucciones son ejecutadas por un procesador.
Patentes similares o relacionadas:
Decodificación de audio estéreo paramétrico, del 9 de Enero de 2019, de DOLBY INTERNATIONAL AB: Receptor, que comprende: un demultiplexor para desmultiplexar un flujo de bits para obtener una señal mono y parámetros de amplitud estéreo; […]
Receptor y método para decodificar flujo de datos codificado estéreofónico paramétrico, del 20 de Septiembre de 2017, de DOLBY INTERNATIONAL AB: Receptor, que comprende: un demultiplexor configurado para extraer una señal monofónica codificada y parámetros de amplitud estereofónica […]
Método de codificación, método de descodificación, codificador, descodificador, programa y medio de grabación, del 29 de Marzo de 2017, de NIPPON TELEGRAPH AND TELEPHONE CORPORATION: Un método de codificación de voz o de señales acústicas que comprende adquirir códigos correspondientes a residuos de predicción obtenidos según […]
Dispositivo de codificación de sonido y procedimiento de codificación de sonido, del 25 de Enero de 2017, de III Holdings 12, LLC: Un aparato de codificación de voz que comprende: una sección de análisis de parámetro de predicción que calcula una diferencia de retardo y una relación […]
 Codificador y decodificador de audio para codificar tramas de señales de audio muestreadas, del 2 de Febrero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio adaptado para codificar tramas de una señal de audio muestreada para obtener tramas codificadas, en el que una […]
Codificador y decodificador de audio para codificar tramas de señales de audio muestreadas, del 2 de Febrero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio adaptado para codificar tramas de una señal de audio muestreada para obtener tramas codificadas, en el que una […]
Codificador y descodificador de audio para codificar y descodificar muestras de audio, del 6 de Enero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio para codificar muestras de audio, que comprende: un primer codificador de introducción de distorsión por repliegue del espectro […]
Códec de audio sin pérdidas escalable y herramienta de autoría, del 6 de Mayo de 2015, de DTS, INC: Un método para codificar un flujo de bits sin pérdidas escalable para muestras de audio de PCM de M-bits para decodificar mediante un decodificador sin […]
Codificador de extensión de ancho de banda, descodificador de extensión de ancho de banda y vocoder de fase, así como métodos correspondientes y programa de computadora, del 25 de Marzo de 2015, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de extensión de ancho de banda para codificar una señal de audio , la señal de audio que comprende una señal […]