CODIFICACIÓN, MODIFICACIÓN Y SÍNTESIS DE SEGMENTOS DE VOZ.
Método de análisis, modificación y síntesis de señal de voz que comprende una fase de localización de ventanas de análisis mediante un proceso iterativo de determinación de la fase de la primera componente sinusoidal y comparación entre el valor de fase de dicha componente y un valor predeterminado,
una fase de selección de tramas de análisis correspondientes a un alófono y reajuste de la duración y la frecuencia fundamental según unos umbrales y una fase de generación de voz sintética a partir de las tramas de síntesis tomando como información espectral de la trama de síntesis la información de la trama de análisis más cercana y tomando tantas tramas de síntesis como periodos tenga la señal sintética. El método permite una localización coherente de las ventanas de análisis dentro de los periodos de la señal y generar de forma exacta los instantes de síntesis de manera síncrona con el periodo fundamental.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P200931212.
Solicitante: TELEFONICA, S.A..
Nacionalidad solicitante: España.
Inventor/es: RODRIGUEZ CRESPO, MIGUEL ANGEL, ESCALADA SARDINA,José Gregorio, ARMENTA LÓPEZ DE VICU;A,Ana.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L13/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 13/00 Síntesis de la voz; Sistemas de síntesis de la voz a partir de texto. › Métodos de producción de voz sintética; Sintetizadores de voz.
- G10L13/04 G10L 13/00 […] › Detalles de sistemas de síntesis de voz, p. ej. estructura del sintetizador o gestión de memoria.
- G10L19/08 G10L […] › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › Determinación o codificación de la función de excitación; Determinación de los parámetros de predicción a largo plazo.
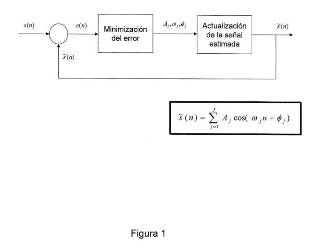
Fragmento de la descripción:
Codificación, modificación y síntesis de segmentos de voz.
Campo de la invención
La presente invención se aplica a las tecnologías del habla. Más concretamente, pertenece a las técnicas de tratamiento digital de la señal de voz usadas, entre otros, dentro de conversores texto-voz.
Antecedentes de la invención
Muchos de los sistemas de conversión texto-voz actuales se basan en la concatenación de unidades acústicas tomadas de voz pregrabada. Esta aproximación es la que permitió dar el salto de calidad necesario para el uso de conversores texto-voz en multitud de aplicaciones comerciales (fundamentalmente, en la generación de información hablada a partir de texto en sistemas de respuesta vocal interactiva a los que se accede telefónicamente).
Aunque la concatenación de unidades acústicas permite obviar el difícil problema de modelar completamente la producción de la voz humana, tiene que manejar otro problema básico: cómo concatenar trozos de voz tomados de distintos ficheros de origen, que pueden presentar diferencias apreciables en los puntos de pegado.
Las posibles causas de discontinuidad y defectos en la voz sintética son de diverso tipo:
Por este motivo, los conversores texto-voz suelen emplear diversos procedimientos de tratamiento de la señal de voz que permiten, tras la concatenación de unidades, unirlas suavemente en los puntos de pegado, y modificar su prosodia para que resulte continua y natural. Y todo ello debe hacerse degradando lo menos posible la señal original.
Los sistemas de conversión texto-voz más tradicionales contaban con un repertorio de unidades relativamente reducido (por ejemplo, difonemas o demisílabas), en los que normalmente sólo se disponía de un candidato para cada una de las posibles combinaciones de sonidos contempladas. En estos sistemas la necesidad de hacer modificaciones a las unidades es muy elevada.
Los sistemas de conversión texto-voz más recientes se basan en la selección de unidades de un inventario mucho más amplio (síntesis por corpus). Este amplio inventario dispone de muchas alternativas de las diferentes combinaciones entre sonidos, que se diferencian en su contexto fonético, prosodia, posición dentro de la palabra y del enunciado. La selección óptima de esas unidades de acuerdo a un criterio de coste mínimo (costes de unidad y de concatenación) permite reducir la necesidad de hacer modificaciones en las unidades, y mejora mucho la calidad y naturalidad de la voz sintética resultante. Pero no es posible eliminar totalmente la necesidad de manipular las unidades pregrabadas, porque los corpus de voz son finitos y no pueden asegurar una completa cobertura para sintetizar de manera natural cualquier enunciado, y siempre habrá puntos de pegado.
Existen distintos métodos de representación y modificación de la señal de voz que han sido usados dentro de conversores texto-voz.
Los métodos basados en el solapamiento y suma de ventanas de la señal de voz en el dominio temporal (métodos PSOLA, "Pitch Synchronous Overlap and Add") gozan de gran aceptación y difusión. El más clásico de estos métodos aparece descrito en "Pitch-synchronous waveform processing techniques for text-to-speech synthesis using dyphones" (E. Moulines y F. Charpentier, Speech Communication, vol. 9, pp. 453-467, dic. 1990). Se obtienen tramas (ventanas) de la señal de voz de manera síncrona con el periodo fundamental ("pitch"). Las ventanas de análisis deben estar centradas en los instantes de cierre de la glotis (GCI's, "Glottal Closure Instants") u otros puntos identificables dentro de cada periodo de la señal, que deben encontrarse cuidadosamente y ser etiquetados coherentemente, para evitar desajustes de fase en los puntos de pegado. El marcado de estos puntos es una tarea laboriosa que no se puede realizar de forma completamente automática (requiere ajustes), y que condiciona el buen funcionamiento del sistema. La modificación de duración y frecuencia fundamental (F0) se realiza mediante la inserción o borrado de tramas, y el alargamiento o estrechamiento de las mismas (cada trama de síntesis es un periodo de la señal, y el desplazamiento entre dos tramas sucesivas es el inverso de la frecuencia fundamental). Puesto que los métodos PSOLA no incluyen un modelo explícito de la señal de voz, la tarea de interpolar las características espectrales de la señal en los puntos de pegado resulta difícil de realizar.
El método MBROLA ("Multi-Band Resynthesis Overlap and Add") descrito en "Text-to-Speech Synthesis based on a MBE re-synthesis of the segments database" (T. Dutoit y H. Leich, Speech Communication, vol. 13, pp. 435-440, 1993) aborda el problema de la falta de coherencia de fase en los pegados sintetizando una versión modificada de las partes sonoras de la base de datos de voz, forzando que tengan un F0 y una fase determinada (igual en todos los casos). Pero este proceso afecta a la naturalidad de la voz.
También se han propuesto métodos tipo LPC ("Linear Predictive Coding") para hacer síntesis de voz, como el descrito en "An approach to Text-to-Speech synthesis" (R. Sproat and J. Olive, Speech Coding and Synthesis, pp. 611-633, Elsevier, 1995). Estos métodos limitan la calidad de la voz al suponer un modelo de sólo polos. El resultado depende mucho de si la voz original de referencia se ajusta mejor o peor a las suposiciones del modelo. Suele plantear problemas especialmente con voces femeninas e infantiles.
También se han propuesto modelos de tipo sinusoidal, en los que la señal de voz se representa mediante una suma de componentes sinusoidales. Los parámetros de los modelos sinusoidales permiten hacer de forma bastante directa e independiente tanto la interpolación de parámetros como las modificaciones prosódicas. En cuanto a asegurar la coherencia de fase en los puntos de pegado, algunos modelos han optado por manejar un estimador de los instantes de cierre de la glotis (proceso que no siempre da buenos resultados), como por ejemplo en "Speech Synthesis based on Sinusoidal Modeling" (M. W. Macon, PhD Thesis, Georgia Institute of Technology, oct. 1996). En otros casos se ha asumido la simplificación de considerar una hipótesis de fase mínima (que afecta a la naturalidad de la voz en algunos casos, haciendo que se perciba más hueca y amortiguada), como en un trabajo publicado por algunos de los inventores de esta propuesta: "On the Use of a Sinusoidal Model for Speech Synthesis in Text-to-Speech" (M. Á. Rodríguez, P. Sanz, L. Monzón y J. G. Escalada, Progress in Speech Synthesis, pp. 57-70, Springer, 1996).
Los modelos sinusoidales han ido incorporando diferentes aproximaciones para resolver el problema de la coherencia de fase. En "Removing Linear Phase Mismatches in Concatenative Speech Synthesis" (Y. Stylianou, IEEE Transactions on Speech and Audio Processing, vol. 9, no. 3, pp. 232-239 marzo 2001) se propone un método para analizar la voz con ventanas que se desplazan de acuerdo al F0 de la señal, pero sin necesidad de que estén centradas en los GCI's. Esas tramas son sincronizadas a posteriori en un punto común basándose en la información del espectro de fase de la señal, sin afectar a la calidad de la voz. Se aplica la propiedad de la Transformada de Fourier en la que añadir una componente lineal al espectro de fase equivale a desplazar la forma de onda en el dominio del tiempo. Se fuerza que el primer armónico de la señal quede con una fase resultante de valor 0, y el resultado es que todas las ventanas de voz quedan centradas de manera coherente respecto a la forma de onda, independientemente de en qué punto concreto de un periodo de la señal...
Reivindicaciones:
1. Método de análisis, modificación y síntesis de señal de voz que comprende:
a. una fase de localización de ventanas de análisis mediante un proceso iterativo de determinación de la fase de la primera componente sinusoidal de la señal y comparación entre el valor de fase de dicha componente y un valor predeterminado hasta encontrar una posición para la que la diferencia de fase representa un desplazamiento temporal menor a media muestra de voz.
b. una fase de selección de tramas de análisis correspondientes a un alófono y reajuste de la duración y la frecuencia fundamental según un modelo, de manera que si la diferencia entre la duración original o la frecuencia fundamental original y las que se quieren imponer supera unos umbrales, se ajustan la duración y la frecuencia fundamental para generar tramas de síntesis.
c. una fase de generación de voz sintética a partir de las tramas de síntesis tomando como información espectral de la trama de síntesis la información de la trama de análisis más cercana y tomando tantas tramas de síntesis como periodos tenga la señal sintética.
2. Método según la reivindicación 1, donde una vez localizada la primera ventana de análisis se busca la siguiente desplazándose medio periodo y así sucesivamente.
3. Método según las reivindicaciones 1 ó 2 donde se hace una corrección de fase añadiendo una componente lineal a la fase de todas las sinusoides de la trama.
4. Método según cualquiera de las reivindicaciones anteriores donde el umbral de modificación para la duración es menor del 25%.
5. Método según la reivindicación 4 donde el umbral de modificación para la duración es menor del 15%.
6. Método según cualquiera de las reivindicaciones anteriores donde el umbral de modificación para la frecuencia fundamental es menor del 15%.
7. Método según la reivindicación 6 donde el umbral de modificación para la frecuencia fundamental es menor del 10%.
8. Método según cualquiera de las reivindicaciones anteriores, donde la fase de generación a partir de las tramas de síntesis se realiza por solapamiento y suma con ventanas triangulares.
9. Uso del método de cualquiera de las reivindicaciones anteriores en conversores de texto-voz.
10. Uso del método de cualquiera de las reivindicaciones 1 a 9 para mejorar la inteligibilidad de las grabaciones de voz.
11. Uso del método de cualquiera de las reivindicaciones 1 a 9 para pegar segmentos de grabaciones de voz diferenciados en cualquier característica de su espectro.
Patentes similares o relacionadas:
Método de codificación de impulsos de las señales de excitación, del 29 de Julio de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método para codificar una señal de voz, que comprende: la obtención de la distribución de impulsos de la señal de voz, en una pista, de los impulsos a codificarse […]
Método de predicción y dispositivo de decodificación para la señal de la banda de expansión del ancho de banda, del 24 de Junio de 2020, de Crystal Clear Codec, LLC: Un método para predecir una señal de banda de frecuencia de extensión del ancho de banda, que comprende: demultiplexación de un flujo de bits recibido y […]
Mejora del contenido insonoro para decodificador CELP de tasa baja, del 17 de Junio de 2020, de VoiceAge EVS LLC: Un dispositivo para modificar, durante la decodificación de una señal de sonido, una síntesis de una excitación de dominio de tiempo decodificada […]
Decodificador de audio y método para proporcionar una información de audio decodificada usando un ocultamiento de errores en base a una señal de excitación de dominio de tiempo, del 29 de Abril de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un decodificador de audio para proporcionar una información de audio decodificada en base a una información de audio codificada , comprendiendo […]
Método de generación y procesado de señal de ruido, codificador/decodificador y sistema de codificación/decodificación, del 22 de Abril de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de procesado de señal de ruido basado en predicción lineal, en donde el método comprende: adquirir (S51) una señal de ruido, y obtener un coeficiente de predicción […]
Método y disposición para suavizar ruido estacionario de fondo, del 25 de Diciembre de 2019, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método para suavizar ruido de fondo, comprendiendo el método: recibir y decodificar (S10) una señal codificada que comprende tanto una componente de voz […]
Aparato y método para la renderización de audio empleando una definición de distancia geométrica, del 25 de Diciembre de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Aparato para reproducir un objeto de audio asociado con una posición, que comprende: un calculador de distancia para calcular distancias de la […]
Decodificador de audio y método para proporcionar una información de audio decodificada usando un ocultamiento de error que modifica una señal de excitación de dominio de tiempo, del 4 de Diciembre de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un decodificador de audio para proporcionar una información de audio decodificada basándose en una información de audio […]