Procedimiento y dispositivo para la clasificación de interlocutores.
Procedimiento para la clasificación automática de un interlocutor gracias a un sistema numérico,
en el que se aplican, como mínimo, dos procedimientos distintos de clasificación de un interlocutor a datos vocales digitales, efectuando la combinación de sus resultados,
en el que el primer procedimiento procesa características a base de segmento, y el segundo procedimiento procesa características a base de expresiones,
en el que el procedimiento a base de expresiones utiliza, como mínimo, un Aparato con Vector de Soporte (SVM) por clase de interlocutor sobre la base de las características de tono basadas en la expresión,
en el que el procedimiento a base de segmentos utiliza, como mínimo, un modelo de mezcla Gaussiana (GMM) por clase de interlocutor, que se basa en coeficientes de frecuencia Mel-Cepstral (MFCC), tratados trama a trama.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E07114958.
Solicitante: DEUTSCHE TELEKOM AG.
Nacionalidad solicitante: Alemania.
Dirección: FRIEDRICH-EBERT-ALLEE 140 53113 BONN ALEMANIA.
Inventor/es: MULLER, CHRISTIAN, RUNGE, FRED, STEGMANN, JOACHIM, BURKHARDT,FELIX.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L17/00 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › Identificación o verificación de la persona que habla.
- G10L17/10 G10L […] › G10L 17/00 Identificación o verificación de la persona que habla. › Sistemas multimodales, p. ej. basados en la integración de múltiples motores de reconocimiento o la fusión de sistemas expertos.
PDF original: ES-2535858_T3.pdf
Fragmento de la descripción:
Procedimiento y dispositivo para la clasificación de interlocutores.
Sector de la invención:
La tecnología de voz, es decir, el tratamiento mediante máquinas de la voz natural, ha ganado significación de modo creciente en las décadas pasadas. Pertenecen a las aplicaciones ya establecidas el reconocimiento automático de voz (reconocimiento automático de voz, ASR) y el sintetizador de voz (text-to-speech, TTS). El estado de la técnica de los sistemas de investigación se encuentra en la situación de llevar a cabo un profundo tratamiento estilístico de los textos de voz. Verbmobil [1] constituye, por ejemplo, un sistema para la traducción de frases expresadas espontáneamente en tres idiomas (alemán, inglés y japonés) en el área de convención de plazos.
En la comunicación entre las personas, el sonido de la voz transporta, no obstante, no solamente la significación de una frase, sino además informaciones que se llaman paralingüísticas, que facilitan, por ejemplo, informaciones sobre características del interlocutor. Corresponde a nuestra experiencia diaria que caracterizamos a las personas con las que nos relacionamos por teléfono en base a su voz, y podemos adecuar nuestro proceso de comunicación de conversación de modo correspondiente.
El desarrollo de sistemas que adapten el comportamiento (diálogo) a las necesidades del usuario es el objeto del modelado de usuario. Consigue cada vez más significación, puesto que la utilización de los sistemas de ordenadores ha salido del ámbito de la mesa de trabajo y han encontrado utilización en muchas áreas de la vida. Las exigencias específicas a los sistemas varían con las diferentes situaciones en las que se utilizan. Por ejemplo, un sistema navegador móvil para peatones debe tener en cuenta, por ejemplo, las circunstancias en que el usuario se encuentra, posiblemente en un cruce de calles con elevado nivel sonoro, en la parte interna de la ciudad y debe dirigir una parte muy importante de su atención a su entorno, mientras que en otro caso, se puede encontrar en un tranquilo banco de un parque y se puede dedicar de manera completa al diálogo con el sistema (ver [2]). El área de investigación de la clasificación de interlocutores define, además, el captar las informaciones sobre el interlocutor, que son necesarias para constituir un modelo de usuario adecuado, directamente sobre la base de las informaciones conseguidas por la voz. En este documento se describirá, por ejemplo, el reconocimiento de la edad y el sexo del interlocutor. No obstante, los principios que se establecen pueden ser utilizados en otras características biológicas y mentales del interlocutor tales como, por ejemplo, dimensiones corporales ([3], [4]) o la situación emocional y afectiva ([5]).
Otras investigaciones dadas a conocer hasta el momento [5] describen un experimento para la identificación de características en la voz, en base a las cuales se puede deducir la carga cognitiva del interlocutor. La situación en la que se basa es la siguiente: un sistema de ayuda móvil debe acompañar a un viajero en su recorrido por un gran aeropuerto. Se puede esperar que el viajero tenga una elevada carga cognitiva porque debe tener en cuenta el número de la puerta de embarque y la hora de embarque, y por el hecho de que actúa sobre él mismo una gran cantidad de informaciones del aeropuerto. Además, se encuentra posiblemente sometido a presión por el tiempo, puesto que en un corto periodo de tiempo hasta la salida, no solamente debe encontrar la puerta de embarque sino que, en su recorrido, desea todavía adquirir un regalo. El sistema debe reconocer esta carga y tenerla en cuenta para la generación de indicaciones de recorrido. El experimento simula la situación en el aeropuerto a través de un complejo experimento de doble función, en el que las personas sometidas a prueba son sometidas de modo artificial a carga cognitiva y a presión por el tiempo, y proponen preguntas al sistema de ayuda tales como: "Debo cambiar las ropas a mi pequeño, Cómo llego al lugar de cuidados infantiles más próximo?". Como resultado del experimento se pudo preparar una lista de características en base a las cuales se manifiesta la carga en la voz: velocidad de articulación más lenta, más pausas de voz y más largas y, en especial, aparición elevada de las llamadas disfluencias (por ejemplo, autocorrecciones, repeticiones, interrupciones de la frase, o frases erróneas).
El objeto principal de investigación de [6] es el desarrollo de un procedimiento para la utilización de las informaciones paralingüísticas contenidas en la voz para deducir la edad y el sexo del interlocutor. Las condiciones técnicas de entorno se facilitan por un sistema de diálogo móvil de voz natural, que se ocupa, mediante la integración de dicho procedimiento, en la constitución de un modelo de usuario no intrusivo (ver, por ejemplo, también [7]; [8]). A continuación, este sistema se designará como sistema AGENDER.
En Müller, C. (2006), Clasificación de interlocutores sensible a contexto, de dos etapas sobre el ejemplo de edad y sexo [Two-layered Context-Sensitive Speaker Classification on the Example of Age and Gender], Akademische Verlagsges ellschaft Aka, Berlín se describió un procedimiento para el reconocimiento automático de la edad y sexo del interlocutor. En aquel caso, se utilizaron, no obstante, exclusivamente, características que conducían a la investigación de la edad por la voz de forma directa: "Jitter y Shimmer", así como la armonía como características de la calidad de la voz (que disminuye con la edad), pausas de voz (que, con cargas cognitivas más reducidas aumentan con el aumento de la edad), velocidad de articulación (que disminuye por iguales causas), y frecuencia base de la voz ("Pitch") que manifiesta, en primer lugar, una característica de diferenciación entre interlocutores femeninos y masculinos pero que, no obstante, es también relevante para el reconocimiento de la edad. No
obstante, una combinación de estas características con las llamadas cepstrales de corto plazo (representación del espectro, que se utiliza en el reconocimiento de voz y reconocimiento de interlocutor), no se investigó en este caso.
En la obra de Metze, F., Ajmera, J., Englert, R., Bub, U., Burkhardt, F., Stegmann, J., Müller, C., Fluber, R., Andrassy, B., Bauer, J., y Littel, B. (2007), Comparación de Cuatro Enfoques para el Reconocimiento de Edad y Sexo para Aplicaciones Telefónicas, Actas de la 32 Conferencia Internacional sobre Acústica, Habla y Proceso de Señales (ICASSP 2007), Honolulú, Hawaii, se encuentra una descripción simplificada de Müller (2006). Además, se describen en dicho trabajo otros procedimientos para el reconocimiento de voz. El sistema más satisfactorio en este estudio comparativo, se basa en un procedimiento en el que se forman reconocedores fónicos para las diferentes clases de edad. La decisión de a qué clase pertenece una determinada muestra de voz (probabilidad), tenía lugar sobre la base de los valores de confianza de este reconocedor fónico. El procedimiento, no obstante, no se ha acreditado en la práctica puesto que, para la formación, eran necesarios datos de voz anotados manualmente, que solamente se pueden conseguir con elevados costes financieros. En la obra de Metze y otros, (2007), se describió, además por primera vez, un procedimiento en base a las anteriormente mencionadas cepstrales de corto plazo. De todos modos, en este caso, tampoco se tuvieron en cuenta las características explícitas procedentes de la investigación de la edad de la voz.
Utilizaciones:
La clasificación de interlocutores tal como, por ejemplo, el reconocimiento de edad del interlocutor y sexo, se puede considerar como procedimiento no intrusivo para la captación de un modelo de interlocutor. El Mobile ShopAssist [9] es, por ejemplo, una aplicación Pocket-PC (ordenador de bolsillo), que sirve además para demostrar la utilización de habla natural en un entorno típico de compras. Un tema central de esta aplicación es la interacción móvil y multimodal, que puede consistir en forma de gestos, voz, escritura y una combinación de los mismos. El Personal Navigator [10] (Navegador personal) es una aplicación muy similar en cuanto a la técnica de interacción: Los usuarios pueden efectuar consultas de ruta mediante una combinación de voz y gestos o pedir informaciones sobre edificios que se encuentran en las proximidades.
En base al modelo de usuario que se ha puesto a disposición por el AGENDER, el auxiliar de compras puede realizar una elección específica de productos, en el caso de cámaras digitales, por ejemplo, en caso de que el interlocutor ha sido reconocido como femenino, puede presentar, en principio, un modelo que el fabricante ha desarrollado... [Seguir leyendo]
Reivindicaciones:
1. Procedimiento para la clasificación automática de un interlocutor gracias a un sistema numérico, en el que se aplican, como mínimo, dos procedimientos distintos de clasificación de un interlocutor a datos vocales digitales, efectuando la combinación de sus resultados,
en el que el primer procedimiento procesa características a base de segmento, y el segundo procedimiento procesa características a base de expresiones,
en el que el procedimiento a base de expresiones utiliza, como mínimo, un Aparato con Vector de Soporte (SVM) por clase de interlocutor sobre la base de las características de tono basadas en la expresión, en el que el procedimiento a base de segmentos utiliza, como mínimo, un modelo de mezcla Gaussiana (GMM) por clase de interlocutor, que se basa en coeficientes de frecuencia Mel-Cepstral (MFCC), tratados trama a trama.
2. Procedimiento, según la reivindicación anterior en el que el número de mezclas está comprendido entre 60 y 170, siendo preferentemente 96.
3. Procedimiento, según una o varias de las reivindicaciones anteriores, en el que una combinación del procedimiento de clasificación de interlocutor se realiza sobre la clasificación de nivel ("Score Level").
4. Procedimiento, según las reivindicaciones anteriores, en el que en la combinación de SVM y CMM se introducen ponderaciones, y las ponderaciones son determinadas por medio de una búsqueda específica de clase.
5. Procedimiento, según una o varias de las reivindicaciones anteriores, en el que antes de la clasificación de interlocutor, tiene lugar una extracción de características de los datos de voz.
6. Procedimiento, según una o varias de las reivindicaciones anteriores, en el que tiene lugar una combinación de identificativos de un terminal, contactando un sistema para una clasificación de interlocutores, con la finalidad de almacenar información relativa a la clasificación de interlocutor con respecto a los identificadores, que son tenidos en cuenta por una nueva clasificación de interlocutor.
7. Procedimiento, según las reivindicaciones anteriores, en el que se lleva a cabo adicionalmente el almacenamiento de características de clasificación de interlocutor o datos digitales de voz en bruto en relación con el identificador.
8. Dispositivo para la clasificación automática de interlocutores, que comprende:
- un sistema digital, que recibe datos de voz de una persona a través de un interfaz;
- una unidad de proceso, que puede tener acceso a los datos de voz, y que está diseñada y dispuesta de manera tal que, como mínimo, se aplican dos procedimientos distintos de clasificación de interlocutores a los datos de voz, y los resultados son combinados entre sí, en el que el primer procedimiento procesa características basadas en segmento, y el segundo procedimiento procesa características basadas en
expresión,
en el que el procedimiento basado en expresión (SVM) utiliza, como mínimo, un aparato con vector de soporte para cada clase de interlocutor en base a características de tono basadas en la expresión,
de manera que el procedimiento basado en segmentos utilizado, utiliza como mínimo un modelo de mezcla Gaussiana (GMM) para cada clase de interlocutor, que se basa en Coeficientes de Frecuencia Mel-Cepstral (MFCC), que son procesados trama a trama.
9. Dispositivo, según la reivindicación anterior, en el que el número de mezclas está comprendido entre 60 y 170, preferentemente 96.
10. Dispositivo, según una o varias de las reivindicaciones anteriores, en el que mediante la unidad de proceso tiene lugar una combinación del procedimiento de clasificación de interlocutores en base a clasificación del nivel ("Score Level").
11. Aparato, según una de las reivindicaciones anteriores, en el que en la combinación de SVM y CMM se introducen ponderaciones, y las ponderaciones son determinadas con ayuda de búsquedas específicas de clase.
12. Aparato, según una o varias de las reivindicaciones anteriores, en el que mediante la unidad de proceso u otros medios tiene lugar antes de la clasificación de interlocutor, una extracción de características de los datos de voz.
13. Aparato, según una o varias de las reivindicaciones de aparato anteriores, en el que se dispone de medios para llevar a cabo una combinación de la clasificación de interlocutor con características del aparato terminal, que contacta con un sistema para la clasificación de interlocutores para almacenar informaciones de la clasificación de interlocutor en relación con los identificadores, que se toman en cuenta en una nueva clasificación de interlocutores.
14. Aparato, según la reivindicación anterior, en el que se almacena en una memoria, además de las características de clasificación de interlocutor, datos en brutos digitales de voz.
Patentes similares o relacionadas:
Sistema y procedimiento de registro de audio inteligente para dispositivos móviles, del 2 de Noviembre de 2018, de QUALCOMM INCORPORATED: Un procedimiento para un dispositivo móvil, comprendiendo el procedimiento: mientras el dispositivo móvil está en una modalidad de reposo, capturar una señal […]
Dispositivo de montaje sobre la cabeza para percepción de realidad aumentada, del 30 de Octubre de 2017, de UNIVERSIDAD DE MALAGA: Dispositivo de montaje sobre la cabeza para percepción de realidad aumentada. La invención refiere un dispositivo que comprende medios de montaje sobre la […]
Procedimiento para verificar la identidad de un orador y medio legible por ordenador y ordenador relacionados, del 12 de Octubre de 2016, de AGNITIO, S.L.: Procedimiento para verificar la identidad de un orador en base a la voz de oradores, que comprende las etapas de: a) recibir una expresión de voz de una palabra o una […]
Tarjeta inteligente con micrófono, del 7 de Enero de 2015, de VODAFONE HOLDING GMBH: Una tarjeta inteligente, que comprende un micrófono para capturar una señal de audio, y al menos un medio (104; 110; 111i) de procesamiento para procesar […]
 Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz, del 3 de Diciembre de 2013, de UNIVERSIDAD DE LAS PALMAS DE GRAN CANARIA: Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz.
La presente […]
Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz, del 3 de Diciembre de 2013, de UNIVERSIDAD DE LAS PALMAS DE GRAN CANARIA: Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz.
La presente […]
Detección de falsificación por cortar y pegar por alineamiento temporal dinámico, del 27 de Noviembre de 2013, de AGNITIO, S.L.: Procedimiento para comparar expresiones de voz, comprendiendo el procedimiento las etapas de: extraer una pluralidad de rasgos de una primera expresión […]
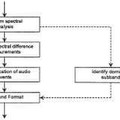 Segmentación de señales de audio en eventos auditivos, del 11 de Abril de 2013, de DOLBY LABORATORIES LICENSING CORPORATION: Un método para dividir cada uno de los múltiples canales de señales de audio digital en eventos auditivos, quecomprende:
detectar cambios en el contenido […]
Segmentación de señales de audio en eventos auditivos, del 11 de Abril de 2013, de DOLBY LABORATORIES LICENSING CORPORATION: Un método para dividir cada uno de los múltiples canales de señales de audio digital en eventos auditivos, quecomprende:
detectar cambios en el contenido […]
MÉTODO Y SISTEMA PARA LA ESTIMACIÓN DE PARÁMETROS FISIOLÓGICOS DE LA FONACIÓN, del 23 de Diciembre de 2011, de UNIVERSIDAD POLITECNICA DE MADRID: La invención consiste en un método y sistema de cómputo para el registro y análisis de la voz, que permite calcular una serie de parámetros de la fonación. Estos transportan […]