Aparato y método para procesar una señal de audio decodificada en un dominio espectral.
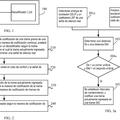
Aparato para procesar una señal de audio decodificada (100) que comprende:
un filtro (102) para filtrar la señal de audio decodificada para obtener una señal de audio filtrada (104);
el aparato estando caracterizado porque comprende:
una etapa de conversión de tiempo a espectral (106) para convertir la señal de audio decodificada y la señal de audio filtrada en correspondientes representaciones espectrales, en donde cada representación espectral tiene una pluralidad de señales de subbanda;
un ponderador (108) para ejecutar una ponderación selectiva en frecuencia de la representación espectral de la señal de audio filtrada mediante la multiplicación de señales de subbanda con respectivos coeficientes de ponderación para obtener una señal de audio filtrada y ponderada;
un sustractor (112) para ejecutar un sustracción por subbandas entre la señal de audio filtrada y ponderada y la representación espectral de la señal de audio decodificada para obtener una señal de audio resultante; y
un convertidor de espectral a tiempo (114) para convertir la señal de audio resultante o una señal derivada de la señal de audio resultante a una representación en el dominio temporal para obtener una señal de audio decodificada y procesada (116).
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2012/052292.
Solicitante: FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V..
Nacionalidad solicitante: Alemania.
Dirección: HANSASTRASSE 27C 80686 MUNCHEN ALEMANIA.
Inventor/es: GEIGER, RALF, SCHNELL,MARKUS, FUCHS,Guillaume, RAVELLI,EMMANUEL, DOEHLA,STEFAN.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L19/012 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › Codificación del ruido de confort o el silencio.
PDF original: ES-2529025_T3.pdf
Fragmento de la descripción:
Aparato y método para procesar una señal de audio decodificada en un dominio espectral
[1] La presente invención se relaciona con el procesamiento de audio y, en particular, con el procesamiento de una señal de audio decodificada con el propósito de realzar la calidad.
[2] Recientemente, se alcanzaron otros avances con respecto a los codees de audio conmutados. Un códec de audio conmutado de alta calidad y baja velocidad de transmisión de bits es el concepto de codificación unificada de voz y audio (concepto USAC). Existe un pre/post-procesamiento común que consiste en una unidad funcional de MPEG envolvente (MPEGs) para manejar un procesamiento estéreo o multicanal y una unidad SBR intensificada (eSBR) que maneja la representación paramétrica de las frecuencias de audio más elevadas en la señal de entrada. Seguidamente hay dos ramas, una que consiste en un tramo de una herramienta de codificación de audio avanzada (AAC) y la otra que consiste en un tramo basado en la codificación por predicción lineal (dominio LP o LPC) que, a su vez, presenta una representación en el dominio frecuencial o una representación en el dominio temporal de la LPC residual. Todos los espectros transmitidos correspondientes tanto a AAC como a LPC están representados en el dominio MDCT siguiendo la cuantización y la codificación aritmética. La representación en el dominio temporal utiliza un esquema de codificación por excitación ACELP. Los diagramas de bloques del codificador y el decodificador están expuestos en la Fig. 1.1 y en la Fig. 1.2 de ISO/IEC CD 233-3.
[3] Un ejemplo adicional de códec de audio conmutado es el códec de banda ancha adaptativa de múltiples velocidades (AMR-WB+) descrito en 3GPP TS 26.29 V1.. (211-3). EL códec de audio AMR-WB+ procesa cuadros de entrada iguales a 248 muestras a una frecuencia de muestreo interno Fs. Las frecuencias de muestreo interno están restringidas al rango de 128 a 384 Hz. Los cuadros de 248 muestras se dividen en dos bandas de frecuencia iguales de muestreo crítico. Esto da lugar a dos súper cuadros de 124 muestras correspondientes a la banda de baja frecuencia (LF) y de alta frecuencia (HF). Cada súper cuadro está dividido en cuatro cuadros de 256 muestras. El muestreo a la velocidad de muestreo interno se obtiene utilizando un esquema de conversión de muestreo variable que remuestrea la señal de entrada. Las señales de LF y HF son codificadas a continuación utilizando dos estrategias diferentes: la LF es codificada y decodificada utilizando un codificador/decodificador de núcleo, sobre la base de ACELP conmutada y excitación por códigos de transformadas (TCX). En el modo ACELP se utiliza el códec AMR-WB standard. La señal HF se codifica con una cantidad relativamente baja de bits (16 bits por cuadro) utilizando un método de extensión de ancho de banda (BWE). El codificador AMR-WB incluye una funcionalidad de pre-procesamiento, un análisis de LPC, una funcionalidad de búsqueda de lazo abierto, una funcionalidad de búsqueda de libros de códigos adaptativos, una funcionalidad de búsqueda de libros de códigos innovadores y actualización de memorias. El decodificador ACELP comprende varias funcionalidades, como por ejemplo la decodificación de libros de códigos adaptativos, ganancias de decodificación, la decodificación de los libros de códigos ¡nnovativos, ISP de decodificación, un filtro de predicción de largo plazo (filtro LTP), la funcionalidad de excitación de construcción, una interpolación de ISP correspondiente a cuatro subcuadros, un postprocesamiento, un filtro de síntesis, un bloque de desénfasis y un bloque de aumento de número demuestras para obtener, en última instancia, la porción de banda inferior de la salida de voz. La porción más alta de la banda de la salida de voz se genera por el escalamiento de las ganancias utilizando un índice de ganancias HB, una bandera VAD y una excitación aleatoria de 16 kHz. Más aun, se utiliza un filtro de síntesis HB seguida por un filtro pasa banda. Se presentan más detalles en la Fig. 3 de G.722.2.
[4] Se ha mejorado este esquema en la AMR-WB+ mediante la ejecución de un post-procesamiento de la señal mono de banda baja. Se hace referencia a las Figs. 7, 8 y 9 que ilustran la funcionalidad en AMR-WB+. La Fig. 7 ilustra un intensificador de tono 7, un filtro paso bajo 72, un filtro paso alto 74, una etapa de rastreo de tono 76 y un sumador 78. Los bloques están conectados de la manera ilustrada en la Fig. 7 y son alimentados por la señal decodificada.
[5] En la intensificación de tono de baja frecuencia, se utiliza una descomposición en dos bandas y se aplica el filtrado adaptativo sólo a la banda inferior. Esto da lugar a un post-procesamiento total que se dirige mayormente a frecuencias cercanas a los primeros armónicos de la señal de voz sintetizada. La Fig. 7 ilustra el diagrama de bloques del intensificador de tono de dos bandas. En la rama más alta la señal decodificada es filtrada por el filtro paso alto 74 para producir las señales de banda más alta sh. En la rama más baja, se procesa en primer lugar la señal decodificada por medio del intensificador de tono adaptativo 7 y luego se la filtra por medio del filtro paso bajo 72 para obtener la señal de post-procesamiento de banda inferior (slee). La señal decodificada de postprocesamiento se obtiene sumando la señal de post-procesamiento de banda inferior y la señal de banda superior. El objetivo del intensificador de tono consiste en reducir el ruido interarmónico en la señal decodificada que se obtiene por medio de un filtro lineal de tiempo variable con una función de transferencia He indicada en la primera línea de la Fig. 9 y descrita por la ecuación de la segunda línea de la Fig. 9. a es un coeficiente que controla la atenuación interarmónica. T es el período de tono de la señal de entrada S (n) y sle (n) es la señal de salida del intensificador de tono. Los parámetros T y a varían con el tiempo y están dados por el módulo de rastreo de tono 76 con un valor de a = 1, la ganancia del filtro descrito por la ecuación de la segunda línea de la Fig. 9 es exactamente cero a las fracuencias 1/(2T), 3/(2T), 5/(2T), etc., es decir, en el punto medio entre la DC ( Hz) y las
frecuencias armónicas 1/T, 3/T, 5/T, etc. Cuando a se aproxima a cero, la atenuación entre los armónicos producidos por el filtro definida en la segunda línea de la Fig. 9 se reduce. Cuando a es cero, el filtro no tiene efecto y es un pasa todo. Para confinar el post-procesamiento a la región de baja frecuencia, la señal intensificada sle es filtrada por paso bajo para producir la señal slef que se suma a la señal de filtro paso alto sh para obtener la señal de síntesis post-procesamiento se.
[6] En la Fig. 8 se ilustra otra configuración equivalente a la ilustración de la Fig. 7 y la configuración de la Fig. 8 elimina la necesidad de filtrado de paso alto. Esto se explica con respecto a la tercera ecuación correspondiente a se en la Fig. 9. El hi_p(n) es la respuesta impulsional del filtro paso bajo y hHp(n) es la respuesta impulsional del filtro paso alto complementario. A continuación, la señal post-proceso SE(n) está dada por la tercera ecuación de la Fig. 9. Por consiguiente, el post procesamiento es equivalente a la sustracción de la señal de error a largo plazo filtrada por paso bajo y escalada a.ei_T(n) de la señal de síntesis s (n). La función de transferencia del filtro de predicción a largo plazo está dada de acuerdo con lo indicado en la última línea de la Fig. 9. Esta configuración alternativa de postprocesamiento está ilustrada en la Fig. 8. El valor T está dado por el retardo de tono de bucle cerrado recibido en cada subcuadro (el retardo detono fraccionado redondeado al entero más próximo). Se ejecuta un simple rastreo para verificar la duplicación de tonos. Si la correlación de tono normalizado en el retardo T/2 es mayor que ,95, luego se utiliza el valor T/2 como nuevo retardo de tono correspondiente al post-procesamiento. El factor a está dado por a = ,5gP, que se limita a a mayor o igual a cero y menor o igual a ,5. gP es la ganancia de tono decodificada limitada entre y 1. En el modo TCX, se ajusta el valor de a a cero. Se utiliza el filtro paso bajo FIR de fase lineal con 25 coeficientes con la frecuencia de corte de aproximadamente 5 Hz. El retardo del filtro es de 12 muestras). La rama superior necesita introducir un retardo que corresponde al retardo del procesamiento en la rama inferior para mantener las señales de las dos ramas alineadas antes de ejecutar la sustracción. En AMR-WB+ Fs=2x la velocidad de muestreo del núcleo. La velocidad de muestreo del núcleo es igual a 128 Hz. Por lo tanto, la frecuencia de corte es igual a 5Hz.
[7] Se ha encontrado que, en especial en el caso de las aplicaciones... [Seguir leyendo]
Reivindicaciones:
1. Aparato para procesar una señal de audio decodificada (1) que comprende:
un filtro (12) para filtrar la señal de audio decodificada para obtener una señal de audio filtrada (14); el aparato estando caracterizado porque comprende:
una etapa de conversión de tiempo a espectral (16) para convertir la señal de audio decodificada y la señal de audio filtrada en correspondientes representaciones espectrales, en donde cada representación espectral tiene una pluralidad de señales de subbanda;
un ponderador (18) para ejecutar una ponderación selectiva en frecuencia de la representación espectral de la señal de audio filtrada mediante la multiplicación de señales de subbanda con respectivos coeficientes de ponderación para obtener una señal de audio filtrada y ponderada;
un sustractor (112) para ejecutar un sustracción por subbandas entre la señal de audio filtrada y ponderada y la representación espectral de la señal de audio decodificada para obtener una señal de audio resultante;
y
un convertidor de espectral a tiempo (114) para convertir la señal de audio resultante o una señal derivada de la señal de audio resultante a una representación en el dominio temporal para obtener una señal de audio decodificada y procesada (116).
2. El aparato según la reivindicación 1, que además comprende un decodificador de intensificación de ancho de banda (129) o un decodificador mono-estéreo o mono-multicanal (131) para calcular la señal derivada de la señal de audio resultante,
en donde el convertidor de espectral a tiempo (114) está configurado para no convertir la señal de audio resultante sino la señal derivada de la señal de audio resultante al dominio temporal de manera que todo el procesamiento por el decodlficador de intensificación de ancho de banda (129) o el decodificador mono-estéreo o mono-multicanal (131) se ejecuta en el mismo dominio espectral definido por la etapa de conversión de tiempo a espectral (16).
3. El aparato según la reivindicación 1 o 2,
en donde la señal de audio decodificada es una señal de salida decodificada por ACELP, y en donde el filtro (12) es un filtro de predicción a largo plazo controlado por la información de tono.
4. El aparato según cualquiera de las reivindicaciones precedentes,
en donde el ponderador (18) está configurado para ponderar la señal de audio filtrada de manera que las subbandas de frecuencia inferior estén menos atenuadas o no atenuadas que las subbandas de frecuencia superior de modo que la ponderación selectiva en frecuencia imprime una característica de paso bajo a la señal de audio
filtrada.
5. El aparato según cualquiera de las reivindicaciones precedentes,
en donde la etapa de conversión de tiempo a espectral (16) y el convertidor de espectral a tiempo (114) están configurados para implementar un banco de filtros de análisis QMF y un banco de filtros de síntesis QMF, respectivamente.
6. El aparato según cualquiera de las reivindicaciones precedentes,
en el cual el sustractor (112) está configurado para sustraer una señal de subbanda de la señal de audio filtrada y ponderada de la correspondiente señal de subbanda de la señal de audio para obtener una subbanda de la señal de audio resultante, en donde las subbandas pertenecen al mismo canal de banco de filtros.
7. El aparato según cualquiera de las reivindicaciones precedentes,
en donde el filtro (12) está configurado para ejecutar una combinación ponderada de la señal de audio y por lo menos la señal de audio desplazada en el tiempo por un período de tono.
8. El aparato según la reivindicación 7,
en donde el filtro (12) está configurado para ejecutar la combinación ponderada sólo combinando la señal de audio y la señal de audio existente en instantes anteriores.
9. El aparato según cualquiera de las reivindicaciones precedentes,
en donde el convertidor de espectral a tiempo (114) tiene un número diferente de canales de entrada con respecto a la etapa de conversión de tiempo a espectral (16) de manera que se obtiene una conversión de velocidad de muestreo, en donde se obtiene un aumento del número de muestras, cuando el número de canales de entrada al convertidor de espectral a tiempo es mayor que el número de canales de salida de la etapa de conversión de tiempo a espectral y en donde se ejecuta una reducción del número de muestras, cuando el número de canales de entrada al convertidor de espectral a tiempo es menor que el número de canales de salida de la etapa de conversión de tiempo a espectral.
1. El aparato según cualquiera de las reivindicaciones precedentes, que además comprende:
un primer decodificador (12) para producir la señal de audio decodificada en una primera porción de tiempo;
un segundo decodificador (122) para producir otra señal de audio decodificada en una segunda porción de tiempo diferente;
una primera rama de procesamiento conectada al primer decodificador (12) y al segundo decodificador (122);
una segunda rama de procesamiento conectada al primer decodificador (12) y al segundo decodificador (122),
en donde la segunda rama de procesamiento comprende el filtro (12) y el ponderador (18) y comprende asimismo una etapa de ganancia controlable (129) y un controlador (13), en donde el controlador (13) está configurado para ajustar una ganancia de la etapa de ganancia (129) a un primer valor para la primera porción de tiempo y a un segundo valor o a cero para la segunda porción de tiempo, que es menor que el primer valor.
11. El aparato según cualquiera de las reivindicaciones precedentes, que además comprende un rastreador de tono para obtener un retardo de tono y para ajustar el filtro (12) sobre la base del retardo de tono como la información de tono.
12. El aparato según la reivindicación 1 o 11, en donde el primer decodificador (12) está configurado para suministrar la información de tono o una parte de la información de tono para ajustar el filtro (12).
13. El aparato según la reivindicación 1, 11 o 12, en donde una salida de la primera rama de procesamiento y una salida de la segunda rama de procesamiento están conectadas a las entradas del sustractor (112).
14. El aparato según cualquiera de las reivindicaciones precedentes, en donde la señal de audio decodificada es proporcionada por un decodificador ACELP (12) incluido en el aparato, y
en donde el aparato comprende además un decodificador adicional (122) implementado en forma de decodificador TCX.
15. Método para procesar una señal de audio decodificada (1), que comprende:
filtrar (12) la señal de audio decodificada para obtener una señal de audio filtrada (14); el método estando caracterizado porque comprende:
convertir (16) la señal de audio decodificada y la señal de audio filtrada en sendas representaciones espectrales, en donde cada representación espectral tiene una pluralidad de señales de subbanda; ejecutar (18) una ponderación selectiva en frecuencia de la señal de audio filtrada mediante la multiplicación de señales de subbanda con respectivos coeficientes de ponderación para obtener una señal de audio filtrada y ponderada;
ejecutar (112) una sustracción por subbandas entre la señal de audio filtrada y ponderada y la representación espectral de la señal de audio decodificada para obtener una señal de audio resultante; y convertir (114) la señal de audio resultante o una señal derivada de la señal de audio resultante en una representación en el dominio temporal a fin de obtener una señal de audio decodificada y procesada (116).
16. Programa de computación que contiene un código para implementar, al ejecutarse en una computadora, el método para procesar una señal de audio decodificada según la reivindicación 15.
Patentes similares o relacionadas:
 Método, dispositivo y sistema de transmisión de datos multimedia, del 24 de Junio de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de codificación de señales de audio que comprende:
en un caso en el cual una manera de codificación de una trama previa de una trama actualmente ingresada […]
Método, dispositivo y sistema de transmisión de datos multimedia, del 24 de Junio de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de codificación de señales de audio que comprende:
en un caso en el cual una manera de codificación de una trama previa de una trama actualmente ingresada […]
Aparato y método de selección de modo de generación de ruido de confort, del 6 de Mayo de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato para codificar información de audio, que comprende: un selector para seleccionar un modo de generación de ruido de confort […]
Método de generación y procesado de señal de ruido, codificador/decodificador y sistema de codificación/decodificación, del 22 de Abril de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de procesado de señal de ruido basado en predicción lineal, en donde el método comprende: adquirir (S51) una señal de ruido, y obtener un coeficiente de predicción […]
Método de procesamiento de señal de voz/audio y aparato de codificación, del 8 de Enero de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de procesamiento de señal de voz/audio, que comprende: si una primera señal de voz/audio de banda ancha es una señal armónica, ajustar una condición determinante […]
Método para estimar ruido en una señal de audio, estimador de ruido, codificador de audio, decodificador de audio, y sistema para transmitir señales de audio, del 20 de Noviembre de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Método para estimar ruido en una señal de audio, comprendiendo el método: determinar (S100) un valor de energía para la señal de audio; convertir […]
Métodos y aparatos para retención DTX en codificación de audio, del 12 de Junio de 2019, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método realizado por un codificador, el codificador funcionando para codificar la conversación y aplicar un esquema de transmisión discontinua, DTX, que […]
Codificación y decodificación de posiciones de impulso de pistas de una señal de audio, del 3 de Junio de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato para decodificar una señal de audio codificada, en el que una o más pistas se asocian con la señal de audio codificada, teniendo […]
Aparato y procedimiento para codificar una señal de audio usando una parte de anticipación alineada, del 10 de Abril de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato para codificar una señal de audio que presenta un flujo de muestras de audio , que comprende: un dispositivo de división en ventanas […]