12 inventos, patentes y modelos de JUNQUA, JEAN-CLAUDE
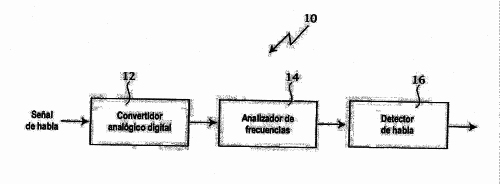
DETECCION DEL HABLA UTILIZANDO MEDIDAS DE CONFIANZA EN EL ESPECTRO DE FRECUENCIAS.
Sección de la CIP Física
(16/07/2006). Ver ilustración. Solicitante/s: PANASONIC TECHNOLOGIES, INC. Clasificación: G10L15/20, G10L11/02.
2005 (2005/46) por "Refrigerator". OG: A-04246.
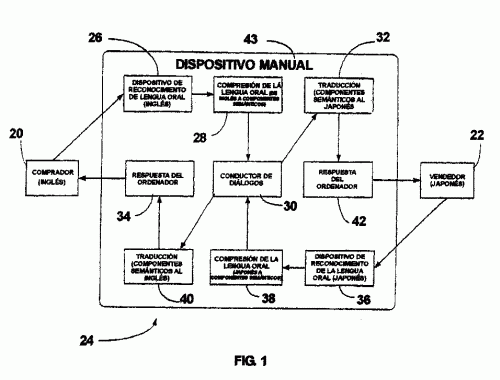
DISPOSITIVO DE CONTROL REMOTO BASADO EN LA PALABRA.
(16/05/2006) Sistema de mando a distancia que comprende: una caja manual dotada de una interface de comunicación por medio de la cual las instrucciones de mando son transmitidas a un componente remoto ; una pantalla de visualización dispuesta en dicha caja; un micrófono dispuesto en dicha caja y que sirve para recibir mensajes orales de entrada; un sistema analizador de voz acoplado a dicho micrófono para procesar dichos mensajes orales de entrada ; un fichero de datos históricos de diálogos utilizado para registrar las conversaciones que han tenido lugar en el conjunto del sistema; una memoria que contiene los datos de perfiles de usuarios ; un administrador de diálogos conectado a dicho sistema analizador de voz , a dicha memoria de datos de perfiles…
MODELOS ACUSTICOS CONTEXTUALES PARA EL RECONOCIMIENTO DEL HABLA CON UN ENTRENAMIENTO DE AUTOVOCES.
Sección de la CIP Física
(01/12/2005). Ver ilustración. Solicitante/s: MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.. Clasificación: G10L15/06.
Método para desarrollar modelos contextuales para el reconocimiento automático de habla que comprende: generar un autoespacio para representar una población de hablantes de entrenamiento; proporcionar un conjunto de datos acústicos para al menos un hablante del entrenamiento y representar dichos datos acústicos en dicho autoespacio para determinar al menos un centroide de alófono para dicho hablante de entrenamiento; y sustraer dicho centroide de dichos datos acústicos para generar datos acústicos adaptados al hablante para dicho hablante de entrenamiento; emplear dichos datos acústicos adaptados al hablante para desarrollar al menos un árbol de decisión que tiene nodos hoja que contienen modelos contextuales para diferentes alófonos.
EXTRACCION ADAPTABLE DE ONDICULAS PARA RECONOCIMIENTO DE VOZ.
(16/10/2005) Método para extraer características para el reconocimiento automático de la voz, que comprende las etapas de: descomponer una señal acústica de voz utilizando un conjunto de ondículas; definir una base de ondículas; y aplicar dicha base de ondículas a dicho conjunto de ondículas para generar una pluralidad de coeficientes de descomposición que representan características extraídas a partir de la señal acústica de voz, caracterizado porque: dicha etapa de definir una base de ondícula comprende maximizar la discriminación de clases particulares de sonidos con relación a la señal descompuesta de voz; dicho conjunto de ondículas se organiza en una estructura arbórea que tiene…
IDENTIFICACION Y VERIFICACION DE INTERLOCUTORES.
(01/10/2005) Método para evaluar una voz con respecto a un interlocutor cliente predeterminado, comprendiendo el método las etapas de: preparar un conjunto de modelos de voz con la voz a partir de una pluralidad de interlocutores de instrucción, en el que la pluralidad de interlocutores de instrucción no incluye al interlocutor cliente; generar vectores de base que definen un espacio de interlocutores a partir del conjunto de modelos de voz para representar dicha pluralidad de interlocutores de instrucción; representar la voz de registro de dicho interlocutor cliente como una primera ubicación en dicho espacio de interlocutores; caracterizado por generar un modelo probabilístico de voz desde la primera ubicación; determinar en el espacio del modelo si un nuevo interlocutor…
SISTEMA DE RECONOCIMIENTO DE HABLA CON LEXICO ACTUALIZABLE MEDIANTE INTRODUCCION DE PALABRAS DELETREADAS.
Sección de la CIP Física
(01/06/2005). Solicitante/s: MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.. Clasificación: G10L15/06.
Un sistema de reconocimiento de habla con un léxico actualizable mediante la entrada de palabras deletreadas que comprende: un fonetizador para generar una transcripción fonética de dicha palabra deletreada entrada; un generador de unidades híbridas receptor de dicha transcripción fonética para generar al menos una representación de unidad híbrida de dicha palabra deletreada entrada basada en dicha transcripción fonética, una unidad híbrida que comprende una mezcla de varias unidades de sonido distintas que incluye al menos una de las sílabas, semisílabas o fonemas; y un constructor de plantillas de palabras que genera, para dicha palabra deletreada, una secuencia de símbolos indicativa de la representación de dicha unidad híbrida para almacenarla en dicho léxico.
METODO Y APARATO ANALIZADOR DEL LENGUAJE NATURAL.
Sección de la CIP Física
(16/04/2005). Ver ilustración. Solicitante/s: MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.. Clasificación: G10L15/18.
Método de análisis sintáctico de lengua oral implementada en un ordenador para procesar una frase de entrada , que comprende las fases de a. facilitar una pluralidad de gramáticas indicativas de temas predeterminados; b. generar una pluralidad de conjuntos de árboles de directorios de análisis sintáctico relacionada con dicha frase de entrada utilizando dichas gramáticas; c. asociar etiquetas con palabras de dicha frase de entrada utilizando dichos conjuntos de árboles de directorios de análisis sintáctico generados ; y d. generar valoraciones de dichas etiquetas basadas en los atributos de dichos conjuntos de árboles de directorios de análisis sintáctico ; y e. seleccionar etiquetas para su uso como representación analizada sintácticamente de dicha frase de entrada basándose en dicha valoración generada.
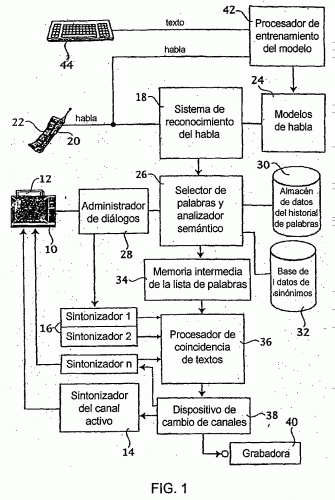
METODO Y DISPOSITIVO DE ELECCION AUTOMATICA DE CANALES DE TELEVISION INTERACTIVA BASADO EN LA COMPRENSION DEL HABLA.
(16/03/2005) Sistema de comprensión del habla que sirve para recibir una petición pronunciada de un usuario y procesa la petición comparándola con una base de conocimientos que contiene información de programación para seleccionar automáticamente un programa de televisión, formado por: un extractor de conocimientos para recibir la información contenida en la guía de programación electrónica (EPG) y procesar la información para crear una base de datos de programas ; un dispositivo de reconocimiento de habla para recibir la petición pronunciada y convertirla en una cadena de texto formada por una pluralidad de palabras; un procesador de lenguaje natural que recibe la cadena de texto…
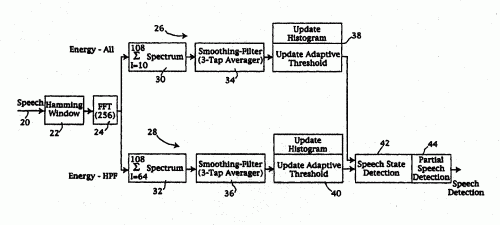
DISPOSITIVO DE DETECCION DE LA PALABRA EN UN ENTORNO RUIDOSO.
Sección de la CIP Física
(16/12/2004). Ver ilustración. Solicitante/s: MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.. Clasificación: G10L11/02.
LA SEÑAL DE ENTRADA SE TRANSFORMA EN EL CAMPO DE FRECUENCIAS Y A CONTINUACION SE SUBDIVIDE EN BANDAS QUE CORRESPONDEN A DIFERENTES GAMAS DE FRECUENCIA. UNOS UMBRALES ADAPTATIVOS SE APLICAN SEPARADAMENTE A LOS DATOS DE CADA BANDA DE FRECUENCIA. DE ESE MODO, SE PRUEBAN LAS ENERGIAS LIMITADAS EN BANDA Y A CORTO PLAZO PARA COMPROBAR LA PRESENCIA O AUSENCIA DE UNA SEÑAL VOCAL. LOS VALORES ADAPTATIVOS DE UMBRAL SE ACTUALIZAN INDEPENDIENTEMENTE PARA CADA UNO DE LOS RECORRIDOS DE SEÑALES, UTILIZANDOSE UNA ESTRUCTURA DE DATOS EN HISTOGRAMA PARA ACUMULAR LOS DATOS A LARGO PLAZO QUE REPRESENTAN LA MEDIA Y VARIANCIA DE ENERGIA DENTRO DE LA CORRESPONDIENTE BANDA DE FRECUENCIAS. LA DETECCION DEL PUNTO FINAL LA REALIZA UNA MAQUINA DE ESTADO QUE PASA DEL ESTADO DE AUSENCIA DE INFORMACION VOCAL AL ESTADO DE PRESENCIA DE INFORMACION VOCAL, Y VICEVERSA, SEGUN LOS RESULTADOS DE LAS COMPARACIONES DE UMBRALES. UN SISTEMA DE DETECCION DE INFORMACION VOCAL PARCIAL MANEJA LOS CASOS EN LOS QUE SE TRUNCA LA SEÑAL DE ENTRADA.
VERIFICACION E IDENTIFICACION DEL HABLANTE MEDIANTE VOCES CARACTERISTICAS.
(16/09/2004) Un método para verificar o identificar un hablante respecto a un hablante cliente predeterminado, consistiendo dicho método en lo siguiente: entrenar un conjunto de modelos de habla sobre el habla de una pluralidad de hablantes de entrenamiento, incluyendo dicha pluralidad de hablantes de entrenamiento un hablante cliente como mínimo; construir un espacio característico para representar dicha pluralidad de hablantes de entrenamiento realizando una reducción de dimensionalidad en conjunto de modelos para generar un conjunto de vectores básicos que definen dicho espacio característico; representar dicho hablante cliente como un primer lugar en dicho espacio característico; procesar datos de entrada del nuevo hablante por entrenamiento de un nuevo modelo de habla en dichos datos de entrada y realizando…
BUSQUEDA AUTOMATICA DE CANALES DE AUDIO POR RECONOCIMIENTO DE PALABRAS PRONUNCIADAS POR EL USUARIO EN EL TEXTO OCULTO O EN LOS CONTENIDOS DE AUDIO PARA TELEVISION INTERACTIVA.
Sección de la CIP Física
(01/06/2004). Ver ilustración. Solicitante/s: MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.. Clasificación: G10L15/28.
Un sistema que recibe la entrada de una infraestructura de telecomunicaciones y muestra la información en una pantalla , teniendo la señal de entrada diversos componentes de información, comprendiendo dicho sistema: un dispositivo reconocedor de habla para recibir las peticiones habladas del usuario y producir una primera salida; un analizador semántico para procesar la primera salida para producir una lista de palabras relacionadas; y un sistema de identificación de patrones de texto coincidentes para comparar la lista de palabras con los diversos componentes de información.
Adaptación no supervisada de un dispositivo de reconocimiento de la palabra utilizando información fiable mediante las N-mejores hipótesis.
Sección de la CIP Física
(16/11/2002). Solicitante/s: MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.. Clasificación: G10L15/06.
Un aparato de reconocimiento de voz que adapta un modelo de voz inicial basado en la entrada de voz del usuario y que comprende: un modelo de voz que representa la dicción bajo la forma de una pluralidad de modelos de unidades de voz asociados a una pluralidad de unidades de voz; un dispositivo de reconocimiento de voz que procesa la entrada de voz de un usuario mediante dicho modelo de voz para generar las N-mejores soluciones de reconocimiento; un sistema de extracción de información fiable para analizar dichas N-mejores soluciones de reconocimiento y seleccionar un conjunto de candidatos de reconocimiento ábles de entre dichas N-mejores soluciones de reconocimiento; un sistema de adaptación que utiliza dichos candidatos de reconocimiento ábles para adaptar el modelo de voz mencionado.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}