PROCEDIMIENTO PARA EL CONTROL DE UN SISTEMA DE DATOS RELACIONAL.
Procedimiento para el control de un sistema de base de datos relacional por la ejecución de una búsqueda de base de datos en una base de datos relacional,
que contiene como estructura de datos asociada una pluralidad de tablas de datos unidas entre sí por relaciones utilizando un lenguaje de base de datos, estando disponible una tabla de relaciones y elaborándose una instrucción para la base de datos procesable que no contiene operaciones referidas a las relaciones y se determina un camino de acceso que establece concretamente un orden de acceso a la base de datos, caracterizado - porque la instrucción para la base de datos elaborada sólo contiene funciones de tratamiento, tablas de datos y sus columnas a las que deben aplicarse las funciones de tratamiento, y los órdenes así como el nivel de jerarquía con el que debe realizarse el procesamiento, en el que el orden y los niveles de jerarquía de las tablas de datos empleadas se representan en forma de un árbol ordenado, y la raíz del árbol ordenado contiene todos los nombres de las tablas de datos sólo de la búsqueda de orden superior, y las subbúsquedas subordinadas a la raíz están inscritas en la estructura de árbol como nudos que contienen los nombres de las tablas de datos asociados a las subbúsquedas, - porque en la tabla de relaciones, de forma conocida en sí, se indican las relaciones como links entre dos respectivas tablas de datos a través del al menos un respectivo campo llave, - porque basado en el árbol mencionado, el camino de acceso se determina calculándose en primer lugar al menos un camino de acceso parcial, a través de la tabla de relaciones, entre dos respectivas tablas de datos sucesivas elegidas, en base a las relaciones disponibles entre las tablas de datos sucesivas, y luego ensamblándose el camino de acceso a partir de todos los caminos de acceso parciales calculados, - porque operaciones orientadas a la relaciones se introducen en la instrucción para la base de datos indicada mediante el camino de acceso determinado con la tabla de relaciones, por lo que se produce una instrucción SQL que puede tratarse por todo sistema de base de datos que soporta el estándar SQL
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/AT2005/000430.
Solicitante: MEDIAREIF MÖSTL & REIF KOMMUNIKATIONS- UND INFORMATIONSTECHNOLOGIEN OEG.
Nacionalidad solicitante: Austria.
Dirección: BREITENSEER STRASSE 110/20/11 1140 WIEN AUSTRIA.
Inventor/es: MOSTL,MATTHIAS.
Fecha de Publicación: .
Fecha Solicitud PCT: 28 de Octubre de 2005.
Fecha Concesión Europea: 4 de Agosto de 2010.
Clasificación PCT:
- G06F17/30
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia.
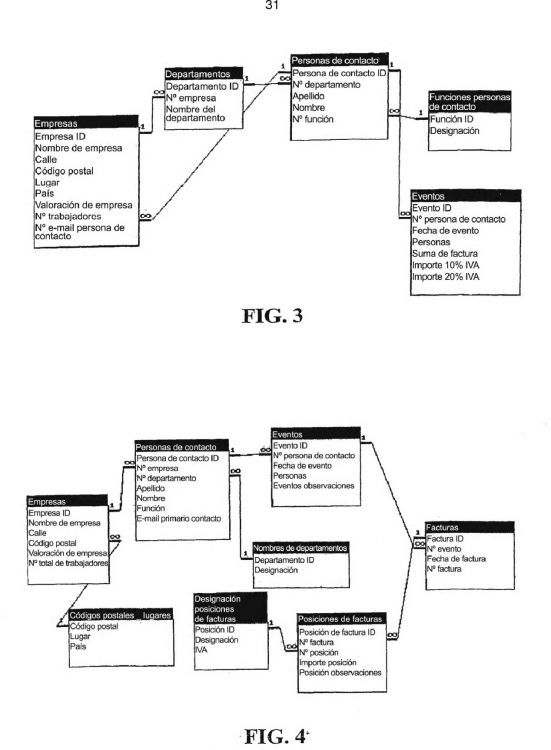
Fragmento de la descripción:
La invención se refiere a un procedimiento para el control de un sistema de base de datos relacional por la ejecución de una búsqueda de base de datos en una base de datos relacional, que contiene como estructura de datos asociada una pluralidad de tablas de datos unidas entre sí por relaciones utilizando un lenguaje de base de datos, estando disponible una tabla de relaciones y elaborándose una instrucción para la base de datos procesable que no contiene operaciones referidas a las relaciones y se determina un camino de acceso que establece concretamente un orden de acceso a la base de datos.
El concepto de la base de datos relacional se destaca por un fácil manejo del usuario, separación de programa y datos, estructura de tablas e integridad de datos por reducción de la redundancia respecto a otras bases de datos.
Se han hecho muchos experimentos de lenguajes de búsqueda en bases de datos que se basan en el modelo de la base de datos relacional, de los que el lenguaje SQL ha resultado como el más utilizable. Todos los otros planteamientos, como OLAP, OQL y TSQL se han integrado con el paso del tiempo en el estándar SQL.
Del documento US 2005/0076045 A1 se desprende un procedimiento para estructurar los datos en un sistema de base de datos relacional, con el que se mejoran las posibilidades de valoración de una base de datos multidimensional, en el que se ofrece la posibilidad del ensamblaje de respectivamente varios elementos (VALUE HOLDING ITEMS y STRUCTURE ITEMS) de una dimensión para formar respectivamente un nuevo elemento (STRUCTURE ITEM) de la dimensión y al mismo tiempo se emplea un procedimiento para generar instrucciones SQL optimizadas mediante el almacenamiento intermedio de datos, para compensar las elevadas pérdidas de velocidad provocadas normalmente con otras instrucciones SQL para las mismas cuestiones. Se indica un camino para ensamblar jerárquicamente diferentes elementos de una dimensión para los que en combinación no se almacena respectivamente un valor agregado en la tabla de datos utilizada. Los elementos (STRUCTURE ITEMS) que existen sin valores agregados pueden elegirse libremente conforme al procedimiento descrito en este documento al contrario que los elementos (VALUE HOLDING ITEMS) que existen con valores agregados y en cualquier momento pueden cambiarse o ampliarse.
El documento US 6 732 091 B1 describe un procedimiento para el tratamiento de búsquedas de base de datos, así por ejemplo para SQL, eligiéndose un plan de acceso lo mejor posible de la pluralidad de todos los planes de acceso posibles que producen el mismo resultado para una instrucción dada en una estructura de datos concreta. La base para ello es una forma
limitada de la tabla de relaciones, permitiéndose sólo enlaces NATURAL-JOIN.
En la práctica ha resultado ser una desventaja que las búsquedas estén referidas sólo a una estructura de datos concreta de la base de datos utilizada en el estado ahora disponible. Tanto
pronto como se realiza un cambio en la estructura de los datos da como resultado cambios en la búsqueda. La misma búsqueda para una estructura de datos determinada parece por ello en ocasiones completamente diferente para otra estructura de datos.
El elemento principal de una búsqueda SQL se forma en muchos casos por operaciones orientadas a las relaciones, como proyecciones, interconexión (join) o selección o operaciones orientadas a la cantidad, como agrupación de cantidad, corte por cantidad o diferencia de cantidad. En este caso se aplica de forma práctica siempre al menos la formación de un producto cartesiano de tablas de datos y limitaciones con ayuda del dato de relación.
En el ejemplo 1 indicado a continuación se clarifica la influencia de la estructura de datos en la formulación de la búsqueda.
Ejemplo 1:
Edición de todas las empresas de Viena, clasificados según los nombres de empresas, sus departamentos y sus personas de contacto.
Estructura de datos, 1:
Relaciones: Empresas <-> departamentos <-> personas de contacto
SELECT empresas.*, departamentos.*, personas de contacto.* Función de tratamiento FROM empresas, departamentos, personas de contacto Producto cartesiano; dato de relación WHERE (empresas . empresa ID = departamentos . Nº empresa) Dato de relaciónAND (departamentos . departamento ID = personas de contacto . Nº departamento) Dato de relación AND (empresas . lugar = “Viena”) Función de tratamiento ORDER BY empresas . nombre Función de tratamiento
Estructura de datos 2:
Relaciones: Empresas <-> sector de actividad <-> departamentos <-> personas de contacto
SELECT empresas.*, departamentos.*, personas de contacto.* Función de tratamiento
FROM empresas, sector de actividad, departamentos, personas de contacto Producto cartesiano; dato de relación
WHERE (empresas . empresa ID = sector de actividad . Nº empresa)
Dato de relación AND (sector de actividad . sector ID = departamentos . Nº sector) Dato de relación AND (departamentos . departamento ID = personas de contacto . Nº departamento)
Dato de relación ORDER BY empresas . nombre Función de tratamiento
Como puede verse según la estructura de datos existen respectivamente relaciones que deben indicarse siempre de nuevo para cada instrucción para la base de datos (statement), por lo que se produce una independencia de la estructura de datos.
El objetivo de la invención es crear un procedimiento con el que se elimina la dependencia de la instrucción para la base de datos de la estructura de datos y se consiga una simplificación para el usuario.
Otro objetivo es permitir un acortamiento de la escritura por lo que se mejore fuertemente la claridad de las búsquedas.
Otro objetivo de la invención es especificar un procedimiento mencionado al inicio con el que pueda accederse al mismo tiempo en diferentes estructuras de datos existentes y con instrucciones que se han escrito sólo para una estructura de datos determinada.
Según la invención esto se consigue, -porque la instrucción para la base de datos elaborada contiene sólo funciones de tratamiento, tablas de datos y sus columnas a las que deben aplicarse las funciones de tratamiento, y los órdenes así como el nivel de jerarquía con el que debe realizarse el procesamiento, en el que el orden y los niveles de jerarquía de las tablas de datos empleadas se representan en forma de un árbol ordenado, y la raíz del árbol ordenado contiene todos los nombres de las tablas de datos sólo de la búsqueda de orden superior, y las subbúsquedas subordinadas a la raíz están inscritas en la estructura del árbol como nudos que contienen los nombres de las tablas de datos asociados a las subbúsquedas,
- porque en la tabla de relaciones, de forma conocida en sí, se indican las relaciones como links entre dos respectivas tablas de datos a través del al menos un respectivo campo llave,
- porque el camino de acceso se determina calculándose en primer lugar un camino de acceso parcial, a través de la tabla de relaciones, entre dos respectivas tablas de datos sucesivas elegidas, en base a las relaciones disponibles entre las tablas de datos sucesivas, y luego ensamblándose el camino de acceso a partir de todos los caminos de acceso parciales calculados,
- porque operaciones orientadas a la relaciones se introducen en la instrucción para la base de datos indicada mediante el camino de acceso determinado con la tabla de relaciones, por lo que se produce una instrucción SQL que puede tratarse por todo sistema de base de datos que soporta el estándar SQL. Mediante la supresión de las operaciones referidas a las relaciones se acorta por un lado la
instrucción para la base de datos y con ello se indica de forma clara para el usuario y por otro lado en una forma independiente de la estructura de datos base, por lo que se producen ventajas de velocidad en la elaboración y procesamiento. Con la ayuda de la tabla de relaciones conocida para cada estructura de datos se calcula el camino de acceso que determina el orden de acceso a la base de datos y puede consultarse para la generación de una instrucción SQL o puede consultarse directamente para el procesamiento.
En la tabla de relaciones están contenidas todas las relaciones que corresponden a la estructura de datos asociada a la base de datos buscada y además...
Reivindicaciones:
1. Procedimiento para el control de un sistema de base de datos relacional por la ejecución de una búsqueda de base de datos en una base de datos relacional, que contiene como estructura de datos asociada una pluralidad de tablas de datos unidas entre sí por relaciones utilizando un lenguaje de base de datos, estando disponible una tabla de relaciones y elaborándose una instrucción para la base de datos procesable que no contiene operaciones referidas a las relaciones y se determina un camino de acceso que establece concretamente un orden de acceso a la base de datos, caracterizado
- porque la instrucción para la base de datos elaborada sólo contiene funciones de tratamiento, tablas de datos y sus columnas a las que deben aplicarse las funciones de tratamiento, y los órdenes así como el nivel de jerarquía con el que debe realizarse el procesamiento,
en el que el orden y los niveles de jerarquía de las tablas de datos empleadas se representan en forma de un árbol ordenado, y la raíz del árbol ordenado contiene todos los nombres de las tablas de datos sólo de la búsqueda de orden superior, y las subbúsquedas subordinadas a la raíz están inscritas en la estructura de árbol como nudos que contienen los nombres de las tablas de datos asociados a las subbúsquedas,
- porque en la tabla de relaciones, de forma conocida en sí, se indican las relaciones como links entre dos respectivas tablas de datos a través del al menos un respectivo campo llave,
- porque basado en el árbol mencionado, el camino de acceso se determina calculándose en primer lugar al menos un camino de acceso parcial, a través de la tabla de relaciones, entre dos respectivas tablas de datos sucesivas elegidas, en base a las relaciones disponibles entre las tablas de datos sucesivas, y luego ensamblándose el camino de acceso a partir de todos los caminos de acceso parciales calculados,
- porque operaciones orientadas a la relaciones se introducen en la instrucción para la base de datos indicada mediante el camino de acceso determinado con la tabla de relaciones, por lo que se produce una instrucción SQL que puede tratarse por todo sistema de base de datos que soporta el estándar SQL. 2. Procedimiento según la reivindicación 1, caracterizado porque en la tabla de
relaciones están contenidos todas las relaciones que corresponden a la estructura de datos asociada a la base de datos buscada, así como dado el caso relaciones libremente generadas.
3. Procedimiento según la reivindicación 1 ó 2, caracterizado porque para la determinación de los caminos de acceso parciales la tabla de relaciones lee en una gráfica que se basa en la teoría de gráficas y con la ayuda de la gráfica así constituida se calculan los caminos de
acceso parciales.
4. Procedimiento según la reivindicación 1, 2 ó 3, caracterizado porque las operaciones orientadas a las relaciones se introducen en la instrucción para la base de datos mediante el camino de acceso.
5. Procedimiento según la reivindicación 1, 2 ó 3, caracterizado porque en la instrucción para la base de datos se indica de forma separada el camino de acceso determinado, que remite paso por paso a las tablas de datos, y para acceder a la base de datos se siguen paso por paso estas referencias a las tablas de datos.
6. Procedimiento según una de las reivindicaciones 1 a 5, caracterizado
- porque en una instrucción para la base de datos para una primera base de datos con una primera estructura de datos asociada se eliminan las primeras operaciones correspondientes orientadas a las relaciones.
- porque las segundas operaciones orientadas a las relaciones se introducen en la instrucción para la base de datos liberada de las primeras relaciones, dichas segundas operaciones orientadas a las relaciones se corresponden a una segunda estructura de datos que está asociada a una segunda base de datos,
- porque la ejecución de la búsqueda se ejecuta en base a la instrucción para la base de datos provista con las segundas operaciones orientadas a las relaciones, determinándose los caminos de acceso parciales utilizando la tabla correspondiente de las segundas relaciones y ensamblándose para formar un camino de acceso.
7. Sistema de base de datos relacional que comprende un sistema informático con una base de datos relacional, una unidad de tratamiento de datos y una memoria, en el que la unidad de tratamiento de datos funciona según el procedimiento según una de las reivindicaciones 1 a 6.
8. Soporte de datos con una instrucción para la base de datos formulada en un lenguaje de la base de datos para controlar y para leer en un sistema de base de datos relacional según la reivindicación 7, caracterizado porque la instrucción para la base de datos presente en el soporte de datos está elaborada sin operaciones referidas a las relaciones, estando indicadas sólo las funciones de tratamiento, tablas de datos y sus columnas en las que deben aplicarse las funciones de tratamiento, y los órdenes así como el nivel de jerarquía con el que debe realizarse el procesamiento, representándose el orden y los niveles de jerarquía de las tablas de datos empleadas en forma de un árbol ordenado, y conteniendo la raíz del árbol ordenado todos los nombres de las tablas de datos sólo de la búsqueda de orden superior, y estando inscritas las subbúsquedas subordinadas a la raíz en la estructura del árbol como nudos que contienen los nombres de las tablas de datos asociados a las subbúsquedas, porque en la tabla de relaciones, de forma conocida en sí, se indican las relaciones como links entre dos respectivas tablas de datos a través del al menos un respectivo campo llave, y porque basado en el árbol mencionado, un camino de acceso está contenido en el soporte de datos, que se determina calculándose en primer lugar al menos un camino de acceso parcial, a través de la tabla de relaciones, entre dos respectivas tablas de datos sucesivas elegidas, en base a las relaciones disponibles entre las tablas de datos sucesivas, y luego ensamblándose el camino de acceso a partir de todos los caminos de acceso parciales calculados, introduciéndose operaciones orientadas a las relaciones en la instrucción para la base de datos indicada mediante el camino de acceso determinado con la tabla de relaciones, por lo que se produce una instrucción SQL que puede tratarse por todo sistema de base de datos que soporta el estándar SQL.
9. Soporte de datos según la reivindicación 8 y para la lectura en un sistema de datos relacional según la reivindicación 7, caracterizado porque el soporte de datos contiene instrucciones para la base de datos en las que ha sido introducido un camino de acceso determinado según el procedimiento según la reivindicación 1 a 6, que se utiliza para controlar el sistema de base de datos mediante la instrucción para la base de datos para el acceso a la base de datos relacional.
10. Soporte de datos según la reivindicación 8 y para la lectura en un sistema de base de datos según la reivindicación 7, caracterizado porque el camino de acceso, que se utiliza para controlar el sistema de base de datos mediante la instrucción para la base de datos para el acceso a la base de datos relacional, está indicada de forma separada en el soporte de datos y el camino de acceso remite paso por paso a las tablas de datos, y para acceder a la base de datos se siguen paso por paso estas referencias a las tablas de datos.
11. Programa informático que presenta instrucciones que están adaptadas para la ejecución del procedimiento según una de las reivindicaciones 1 a 6.
12. Producto de programa informático que presenta un medio legible por ordenador con medios para codificar el programa informático, en el que respectivamente después de cargar el programa informático, un ordenador se induce por el programa para la ejecución del procedimiento según una de las reivindicaciones 1 a 6.
13. Producto de programa informático que presenta un programa informático sobre una señal de soporte electrónica, en el que respectivamente después de la carga del programa informático, un ordenador se induce por el programa para la ejecución del procedimiento según una de las reivindicaciones 1 a 6.
Patentes similares o relacionadas:
Composiciones y métodos para modelar el metabolismo de Saccharomyces cerevisiae, del 3 de Junio de 2020, de THE REGENTS OF THE UNIVERSITY OF CALIFORNIA: Un metodo implementado por computadora para proporcionar a un usuario una simulacion de una funcion fisiologica de levadura relacionada con un gen heterologo […]
Procedimiento de visualización de páginas por medio de un navegador de un equipo como una caja descodificadora Proveedor de Servicios de Internet, del 10 de Enero de 2020, de FREEBOX (100.0%): Un procedimiento de visualización de páginas por un equipo cliente equipado de un sistema cerrado, conectado a un servidor remoto , integrando […]
Procedimiento implementado por ordenador y controlado por ordenador, producto de programa informático y plataforma para disponer datos para su procesamiento y almacenamiento en un motor de almacenamiento de datos, del 4 de Noviembre de 2019, de Dynactionize N.V: Un procedimiento implementado por ordenador y controlado por ordenador de disposición de datos para procesamiento y almacenamiento de los mismos en un […]
MÉTODO DE DOBLAJE Y LOCUCIONES DE AUDIO, del 11 de Julio de 2019, de TANGO VOZ, S.L: Se describe en este documento un método que permite gestionar la producción de doblajes y locuciones de audio destinados a medios audiovisuales de tal manera que no se […]
Un sistema de control para controlar el funcionamiento de una unidad de procesamiento de datos, del 21 de Mayo de 2019, de IG Knowhow Limited: Un sistema de control para controlar el funcionamiento de una unidad de procesamiento de datos, la unidad de procesamiento de datos recibiendo una primera […]
Dispositivo de procesamiento de información, método de procesamiento de información, programa de procesamiento de información y soporte de registro, del 1 de Mayo de 2019, de RAKUTEN, INC: Dispositivo de procesamiento de información que comprende: un medio (12b) de memoria de palabra de área local que almacena una palabra de área […]
Método para proporcionar una estructura de índice en una base de datos, del 1 de Mayo de 2019, de Capish International AB: Metodo para proporcionar una estructura de indice en una base de datos que comprende una pluralidad de tipos de objetos, donde cada tipo de objetos […]
SISTEMA PARA LA DETECCIÓN REMOTA DEL USO DEL CINTURÓN DE SEGURIDAD EN UN VEHÍCULO, del 18 de Abril de 2019, de CASANOVA RENT VOLKS, S.A. DE C.V: La presente invención se refiere a la industria automotriz, particularmente está relacionada con los cinturones de seguridad con que están equipados los vehículos, […]