CIP-2021 : G10L 15/14 : utilizando técnicas de programación dinámica, p. ej. normalización temporal por comparación dinámica [DTW] (G10L 15/18 tiene prioridad).
CIP-2021 › G › G10 › G10L › G10L 15/00 › G10L 15/14[2] › utilizando técnicas de programación dinámica, p. ej. normalización temporal por comparación dinámica [DTW] (G10L 15/18 tiene prioridad).
G FISICA.
G10 INSTRUMENTOS MUSICALES; ACUSTICA.
G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ.
G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad).
G10L 15/14 · · utilizando técnicas de programación dinámica, p. ej. normalización temporal por comparación dinámica [DTW] (G10L 15/18 tiene prioridad).
CIP2021: Invenciones publicadas en esta sección.
Metodología para el reconocimiento automatizado de reptiles mediante la transformación del modelo de Markov de la fusión paramétrica de características de su producción sonora.
(12/04/2017). Solicitante/s: UNIVERSIDAD DE LAS PALMAS DE GRAN CANARIA. Inventor/es: TRAVIESO GONZÁLEZ,Carlos Manuel, SÁNCHEZ RODRÍGUEZ,David De La Cruz, NODA ARENCIBIA,Juan José.
La presente invención se refiere a un procedimiento para el reconocimiento y censo automatizado de reptiles a través de la transformación usando modelos ocultos de Markov de la fusión de las características en diferentes dominios de sus emisiones de señales acústicas permitiendo la identificación de la especie y el seguimiento específico de individuos dentro de una misma especie. Esta metodología emplea una concatenación de características temporales y espectrales para ser automáticamente reconocidas por medio de un sistema inteligente de reconocimiento de patrones.
PDF original: ES-2608613_A1.pdf
PDF original: ES-2608613_B2.pdf
Método para descubrir y reconocer patrones.
(18/02/2015) Método para reconocer un concepto en una señal, por ejemplo una señal de voz, mediante un aparato, comprendiendo el método:
recibir , mediante un receptor del aparato, una primera señal,
muestrear , mediante el aparato, la primera señal para formar una primera secuencia de símbolos unidimensional a partir de la primera señal recibida, por ejemplo usando cuantificación vectorial,
especificar la presencia de un concepto en la primera secuencia mediante una etiqueta de concepto, para cada etiqueta de concepto ck, variando k desde 1 hasta Nc, y para cada retardo ld dado, variando d desde 1 hasta Nl, donde un retardo ld indica una distancia de d elementos en…
Procedimiento de detección de segmentos de habla.
(11/12/2013) Procedimiento de detección de segmentos de habla y de ruido en una señal digital de audio de entrada, estando dividida dicha señal de entrada en una pluralidad de tramas que comprende:
• una primera etapa en la que se realiza una primera clasificación de una trama como ruido si el valor medio de la energía para esta trama y las N tramas anteriores no es superior a un primer umbral de energía (umbral_energ1), siendo N un número entero mayor que 1;
• una segunda etapa en la que para cada trama que no ha sido clasificada como ruido en la primera etapa se decide si dicha trama se clasifica como ruido o como habla en base a la combinación de al menos un primer criterio de similitud espectral de la trama con modelos acústicos de ruido y de habla, un segundo criterio de análisis de energía de la trama respecto…
SISTEMA Y PROCEDIMIENTO DE DETECCION E IDENTIFICACION DE SONIDOS EN TIEMPO REAL PRODUCIDOS POR FUENTES SONORAS ESPECIFICAS.
(15/07/2011) Sistema y procedimiento de detección e identificación de sonidos en tiempo real producidos por fuentes sonoras específicas, que comprende: muestrear, una señal analógica de audio captada por unos medios sensores a partir de al menos una fuente sonora objetivo ; digitalizar la señal muestreada; enventanar la señal digitalizada para obtener tramas de carácter estacionario; extraer, para cada trama, al menos un vector de características; clasificar los vectores de características extraídos; estandarizar la salida de la clasificación; almacenar la señal de salida normalizada; suavizar la señal de salida normalizada almacenada y marcar y extraer eventos sonoros de la señal suavizada a partir de unos parámetros configurados por el usuario.Adicionalmente, comprende una etapa de optimización que permite obtener indicadores estadísticos en la…
COMPRESION DE PROTOTIPOS HMM (MODELOS DE MARKOV ESCONDIDOS).
(16/04/2007) Procedimiento para comprimir prototipos HMM, - prescribiéndose prototipos HMM (Xj); - reproduciéndose los prototipos HMM (Xj) sobre prototipos HMM comprimidos (YJ); - previéndose para reproducir los prototipos HMM (Xj) sobre los prototipos HMM comprimidos (Yj) un codificador que se configura como red neuronal; - teniendo los prototipos HMM comprimidos (Yj) componentes (Yjm, 16), (m = 1, ... M); - siendo transformados los componentes (Yjm) mediante un codificador de bits en números binarios (Yqjm, 23), (j = 1, ..., J), (M = 1, ..., M); - previéndose una red neuronal para reproducir los prototipos HMM comprimidos (Yj) sobre prototipos HMM reconstruidos (Xj); - eligiéndose la estructura y los parámetros de la red neuronal de tal manera que la red neuronal pueda reproducir los números binarios (Yqjm, 23) sobre…
METODO PARA IDENTIFICACION DE SECUENCIAS DE AUDIO.
(16/11/2004) Método para identificación de secuencias de audio. Comprende las siguientes etapas; 1. preprocesado de la secuencia de audio, comprendiendo las etapas de eliminación de las frecuencias superiores a un valor predeterminado con un filtro pasa-bajos, y de digitalización de la señal en un convertidor analógico/digital, 2. extracción de parámetros , representativos de la secuencia de audio, para obtener un vector de parámetros especialmente adaptado al enfoque de identificación propuesto, 3. cálculo de descriptores abstractos , representativos del vector de parámetros, implementados como Modelos Ocultos de Markov, optimizados mediante el uso de una base de datos de definición de descriptores abstractos…
PROCEDIMIENTO PARA LA ADAPTACION DE UN MODELO DE SONIDO HIDDEN MARKOV EN UN SISTEMA DE RECONOCIMIENTO DE VOZ.
(01/07/2002) LA INVENCION SE REFIERE A UN PROCEDIMIENTO PARA ADAPTACION DE UN LIBRO (CB) DE CODIGO DISPONIBLE GENERALMENTE PARA APLICACIONES ESPECIALES CON UN SISTEMA DE RECONOCIMIENTO DE VOZ DEL MODELO SONORO MARKOV OCULTO. ESTAS APLICACIONES SE DEFINEN MEDIANTE UN DICCIONARIO (LEX) CAMBIADO POR EL UTILIZADOR. LA ADAPTACION (ADAP) SE REALIZA DURANTE LA OPERACION Y TIENE LUGAR POR MEDIO DE UN DESPLAZAMIENTO DEL VECTOR DEL PUNTO MEDIO ALMACENADO DE LAS DISTRIBUCIONES DE DENSIDAD DE PROBABILIDAD DE MODELOS MARKOV, EN LA DIRECCION DE UN VECTOR CARACTERISTICO CONOCIDO DE EXPRESIONES DE VOZ SONORAS Y CON RELACION A LOS MODELOS MARKOV OCULTOS ESPECIALMENTE UTILIZADOS. EN COMPARACION CON LAS TACTICAS HABITUALES, LA INVENCION TIENE LA VENTAJA DE QUE LO REALIZA…
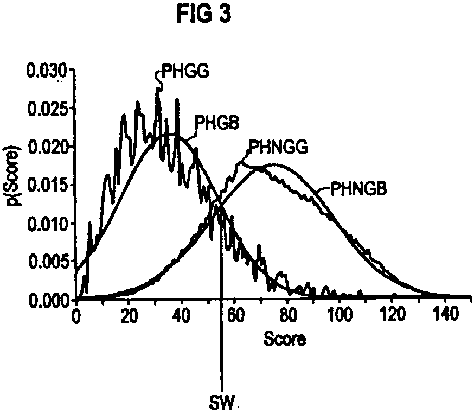
PROCEDIMIENTO PARA CALCULAR UN VALOR UMBRAL PARA EL RECONOCIMIENTO DE VOZ EN UNA PALABRA CLAVE.
(01/07/2002). Ver ilustración. Solicitante/s: SIEMENS AKTIENGESELLSCHAFT. Inventor/es: HOGE, HARALD, JUNKAWITSCH, JOCHEN, RUSKE, GUNTHER.
LA INVENCION PROPONE UN METODO QUE PERMITE CALCULAR EL VALOR UMBRAL DE ACEPTACION, A NIVEL DE PALABRA INDIVIDUAL, DE PALABRAS CLAVE. LA NOVEDAD DE LA INVENCION CONSISTE EN QUE PARA ESTOS VALORES UMBRAL DE DECISION NO ES NECESARIO QUE EXISTAN BANCOS DE DATOS DE PALABRAS DE LAS CORRESPONDIENTES PALABRAS CLAVE, YA QUE LAS DENSIDADES DE DISTRIBUCION DE PROBABILIDAD DE LAS PUNTUACIONES DE LAS RESPECTIVAS PALABRAS CLAVE PUEDEN CALCULARSE DE FORMA TOTALMENTE SINTETICA. PARA ELLO LAS CORRESPONDIENTES PALABRAS CLAVE SE DIVIDEN EN FONEMAS Y SE SUPERPONEN, PONDERADAS POR LONGITUD, LAS DISTRIBUCIONES DE PROBABILIDAD DE LAS PUNTUACIONES DE LOS FONEMAS PARA OBTENER LA DISTRIBUCION DE PROBABILIDAD PARA UNA PALABRA CLAVE. LA FUNCION DE DENSIDAD DE PROBABILIDAD DE DICHA COMBINACION LINEAL SE OBTIENE PLEGANDO LAS FUNCIONES ESCALADAS DE DENSIDAD DE LOS DIFERENTES FONEMAS. EL METODO DE LA INVENCION PUEDE APLICARSE EN LOS MAS DIVERSOS SISTEMAS DE DETECCION DE PALABRAS COMO, POR EJEMPLO, LAS MAQUINAS CONTROLADAS POR VOZ.
{kind=link}